简单入门正则表达式 - 第四章 单字符的匹配

一、单一字符的匹配
正则表达式中,最简单的匹配就是单字符匹配了,这就像我们利用文本工具在文档中查找一个字符一样简单。下面我们使用 EmEditor 来做个小实验,在字符串“Regular Expression”中查找字符“e”。
Ctrl+F 打开查找对话框,然后在“查找”框内键入字符“s”,并选用“匹配大小写”和“使用正则表达式”模式,然后进行查找操作。从上图的效果来看,同时有两个“s”被匹配到了,但实际上这是执行了两次匹配操作的结果,每次操作只匹配了一个字符“s”,操作顺序是自左向右。让我们再尝试使用 Expresso 就能看出其中的奥秘,如下图所示:
在“Regular Expression”的选项卡下输入“s”,“Sample Input Data”区域中输入字符串“Regular Expression”,在单击“Run Match”按钮就能看到匹配结果。在上图的右下角出现了两个“s”,这是发生了两次匹配操作,每次都有一个结果的缘故。
二、任意字符的匹配
当我们使用计算机时,经常需要打开和保存文件,这就免不了要与打开/保存对话框打交道,其中涉及到的文件类型都采用 * 点扩展名这种形式。比如说 HTML 文件,它所对应的文件类型就是 *.html 或 *.htm,星号就是一个通配符,表示与任意字符匹配,而在正则表达式中,也有这么一个通配符“.”,它可以与任意单字符相匹配,但通常不包括换行符。
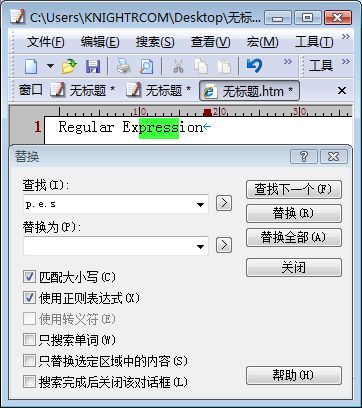
接着上面的例子,我们把正则表达式样式修改为p.e.s,这时的通配符“.”就分别与目标字符串的“r”和“s”相匹配,结果为“Regular Expression”。
三、匹配可选字符
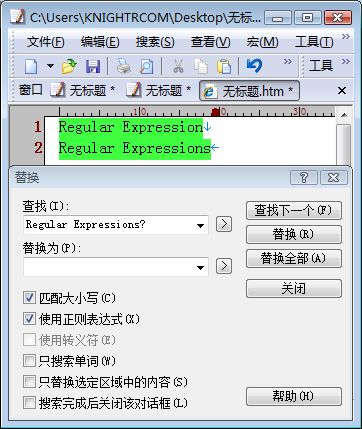
在匹配目标字符串时,有时候可能会有些特殊需求,比方说我们要对词组“Regular Expression”或者“Regular Expressions”进行匹配,无论哪种形式的词组,我们都想能够成功匹配。这时,单词“Expression”后面的“s”就是可选的,在正则表达式中,问号表示它所指定的样式出现的次数为零次或一次,所以,我们可以编写正则表达式Regular Expressions? 来进行匹配。
四、特殊字符的处理
到目前为止,常规字符我们都可以成功地进行匹配,但是,还有一种情况就是像问号这样在正则表达式中含有特殊意义的字符,对于这些字符来说,我们是无法直接利用它们进行匹配操作,那该如何对这些符进行转义呢?跟许多程序语言一样,正则表达式也提供了一个转义的处理机制,我们可以使用转义操作符反斜杆“/”。所以,如果我们想匹配问号和点,使用“/?”和“/.”就可以。同样,对于转义符“/”来说,它对自身也可以实现转义功能,连续的两个“/”代表了一个字符“/”。
修改上面的正则表达式为Regular Expression/?,它就能与字符串“Regular Expression?”相匹配了。在编写正则表达式时,如果碰到了要匹配特殊字符的情况,那就一定要使用转义操作。

五、“*”与“+”
同“?”和“.”一样,“*”和“+”也是具有特殊含义的字符,它们的作用是让某个指定了的正则表达式样式进行多次重复匹配。“*”的重复次数是从零开始的,规定其前导内容必须在目标字符串中出现零次或更多次;而“+”所对应的重复次数是从一开始的,规定其前导内容必须在目标字符串中出现一次或更多次。它们的重复次数都没有上限值限制,也就是说它们的前导内容可以在目标字符串中不断地重复出现。
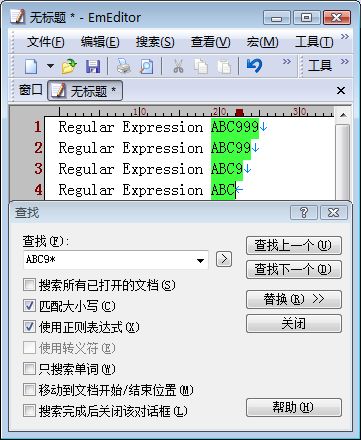
正则表达式ABC9*表示一个以“ABC”开头,后面为零个或多个连续“9”的字符串。这样,它就能与字符串“ABC”、“ABC9”、“ABC99”和“ABC999”等内容相匹配了。
我们先来分析一下对字符串“ABC”的匹配,当正则表达式引擎对ABC匹配结束后,下一个参与匹配的字符就应该是“9”,但根据“*”的零次匹配原则,“9”是可以不出现的,所以,字符串“ABC”就成功地被匹配了。
再来看一下字符串“ABC999”,对字符“C”的匹配结束后,碰到的下一个字符就是“9”,成功匹配之后,继续下一个字符,一直到最后一个字符为止,字符“9”出现的次数与“*”的多次匹配原则保持一致,所以字符串“ABC999”也能够被成功匹配。
六、花括号的使用
上面介绍了如何让我们的匹配内容进行无限次的循环匹配,现在,我们学习一下怎么样精确地控制循环匹配次数。正则表达式提供了一种使用花括号的方法控制循环匹配次数,语法形式有{n}、{n,}、{m,n}三种,其中 m 和 n 都是非负整数,且 m 的值小于 n值。
{n} 代表了被指定的匹配样式必须在目标对象中重复出现 n 次;{n,}表示被指定的匹配样式在目标对象中至少要重复出现 n 次,但无上限值限制;{m,n}指定了循环次数的范围,至少要重复出现 m 次,至多重复出现 n 次,如果 m 值比 n 大,{m, n}的作用就相当于{m, m}。
现在,我们思考一个问题,“*”和“+”同样能够对重复匹配的次数做出限定,那么,如何用花括号形式表示呢?由于“*”表示指定的匹配样式要重复出现 0 或多次,所以,我们可以先用{0}满足重复出现 0 次的要求。但是如又何满能够足重复多次的要求呢,由于最终重复出现的次数是不固定的,我们就不能采用{m,n}这种形式,现在也只有采用最后一种形式{n,},“*”对应的花括号表现形式为{0,}。同理可推“+”对应的花括号表现形式为{1,},相对于用于可选匹配的“?”来说,用{0,1}来替换即可。
七、贪婪模式与懒惰模式
当我们使用含有次数限制的匹配语法时,常常会碰到正则表达式中的贪婪式与懒惰式的概念。那它们到底是什么意思呢?先看一下下面两种对HTML标记进行匹配的例子,构造正则表达式<.+>来匹配字符串“<a>W3C A to Z</a>”,如下图所示:
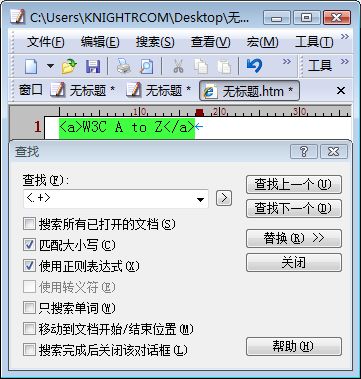
为什么<.+>并没有像我们预想的那样匹配每一个HTML标记,而是一次性“吃掉”了所有的内容呢?这就是贪婪的匹配模式!让我们分析一下正则表达式引擎的匹配机制,就会明白其中的道理了。首先要匹配的字符是“<”(匹配过程01),这个一点问题也没有,然后轮到通配符“.”上场了,因为它后面紧跟着一个“+”,这就能让它毫无顾忌的一个劲儿匹配下去,当匹配到字符串“<a>W3C A to Z</a>”最后一个字符“>”时,引擎发现无法找到相匹配的字符串,就尝试着回退,把最后一次机会让给“>”。结果当然是匹满足条件的了,这就是为什么匹配结果是整个目标字符串而不是“<a>”和“</a>”。
匹配过程01 => <
匹配过程02 => <a>W3C A to Z</a>
匹配过程03 => <a>W3C A to Z</a>backtrack
匹配过程04 => <a>W3C A to Z</a
匹配过程05 => <a>W3C A to Z</a>
匹配过程06 => Match found
接下来,我们再分析一下采用懒惰模式的正则表达式<.+?>,贪婪模式与懒惰模式的语法区别在于重复限定修饰符的后面是否有问号,有的话就是懒惰模式,否则就是贪婪模式。
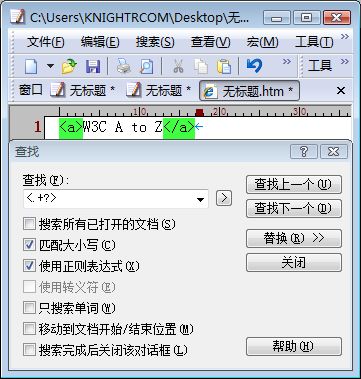
懒惰模式下匹配的结果有两个,“<a>”和“</a>”。对于前者的匹配过程是,首先匹配首字符“<”;然后再将“.”与“a”相匹配,这时“.”已经满足了“+”的匹配次数至少要达到一次的要求,由于懒惰模式的缘故,“+”只要能满足匹配条件就不会继续执行下去;接下来要参与匹配的字符就是“>”,这时恰好满足整个正则表达式的要求。对于后者来说要稍微复杂一点,当第二步“.”与“/”匹配后,第三步就要直接用“>”进行匹配,但“>”并不能与“a”相匹配,所以只能放弃,继续由“.”再次担任匹配任务;与“a”匹配完毕后,重新尝试用“>”进行匹配操作,这次匹配成功并且目标字符串再没有可以参与匹配操作的字符串,整个匹配过程顺利结束,结果就是“</a>”。
|
|
不光是“*”和“+”有贪婪与懒惰两种模式,花括号语法同样存在相同的情况。如果用正则表达式(as){3, 4}来匹配字符串“asasasasas”,结果就是“asasasasas”,有四组“as”被匹配;要是换成(as){3,4}?,结果就是“asasasasas”,有三组“as”被匹配。