CentOS 6.4环境下的Apache Nutch 1.7 + Solr 4.4.0安装笔记
本人原创,转载请注明出处:http://blog.csdn.net/panjunbiao/article/details/12171147
Nutch安装
参考文档:http://wiki.apache.org/nutch/NutchTutorial安装必要程序:
yum update
yum list java*
yum install java-1.7.0-openjdk-devel.x86_64
找到java的安装路径:
参考:http://serverfaullt.com/questions/50883/what-is-the-value-of-java-home-for-centos
设置JAVA_HOME:
参考:http://www.cnblogs.com/zhoulf/archive/2013/02/04/2891608.html
vi + /etc/profile
| JAVA_HOME=/usr/lib/jvm/java JRE_HOME=/usr/lib/jvm/java/jre PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export JAVA_HOME JRE_HOME PATH CLASSPATH |
source /etc/profile
下载二进制包文件:
curl -O http://apache.fayea.com/apache-mirror/nutch/1.7/apache-nutch-1.7-bin.tar.gz
解包:
tar -xvzf apache-nutch-1.7-bin.tar.gz
检验运行文件
cd apache-nutch-1.7
bin/nutch
此时会出现用法帮助,表示安装成功了。
修改文件conf/nutch-site.xml,设置HTTP请求中agent的名字:
| <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>http.agent.name</name> <value>Friendly Crawler</value> </property> </configuration> |
创建种子文件夹
mkdir -p urls
执行第一次爬虫任务:
bin/nutch crawl urls -dir crawl
| solrUrl is not set, indexing will be skipped... crawl started in: crawl rootUrlDir = urls threads = 10 depth = 5 solrUrl=null Injector: starting at 2013-09-29 12:01:30 Injector: crawlDb: crawl/crawldb Injector: urlDir: urls Injector: Converting injected urls to crawl db entries. Injector: total number of urls rejected by filters: 0 Injector: total number of urls injected after normalization and filtering: 0 Injector: Merging injected urls into crawl db. Injector: finished at 2013-09-29 12:01:33, elapsed: 00:00:03 Generator: starting at 2013-09-29 12:01:33 Generator: Selecting best-scoring urls due for fetch. Generator: filtering: true Generator: normalizing: true Generator: jobtracker is 'local', generating exactly one partition. Generator: 0 records selected for fetching, exiting ... Stopping at depth=0 - no more URLs to fetch. No URLs to fetch - check your seed list and URL filters. crawl finished: crawl |
将种子URL写到文件urls/seed.txt中:
| http://www.36kr.com/ |
| # accept anything else # +. # added by panjunbiao +36kr.com |
再次执行爬虫程序,发现有些种子网站被skip了:
bin/nutch crawl urls -dir crawl
| solrUrl is not set, indexing will be skipped... crawl started in: crawl rootUrlDir = urls threads = 10 depth = 5 solrUrl=null Injector: starting at 2013-09-29 12:10:24 Injector: crawlDb: crawl/crawldb Injector: urlDir: urls Injector: Converting injected urls to crawl db entries. Injector: total number of urls rejected by filters: 0 Injector: total number of urls injected after normalization and filtering: 1 Injector: Merging injected urls into crawl db. Injector: finished at 2013-09-29 12:10:27, elapsed: 00:00:03 Generator: starting at 2013-09-29 12:10:27 Generator: Selecting best-scoring urls due for fetch. Generator: filtering: true Generator: normalizing: true Generator: jobtracker is 'local', generating exactly one partition. Generator: Partitioning selected urls for politeness. Generator: segment: crawl/segments/20130929121029 Generator: finished at 2013-09-29 12:10:30, elapsed: 00:00:03 Fetcher: Your 'http.agent.name' value should be listed first in 'http.robots.agents' property. Fetcher: starting at 2013-09-29 12:10:30 Fetcher: segment: crawl/segments/20130929121029 Using queue mode : byHost Fetcher: threads: 10 Fetcher: time-out divisor: 2 QueueFeeder finished: total 1 records + hit by time limit :0 Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Fetcher: throughput threshold: -1 Fetcher: throughput threshold retries: 5 fetching http://www.36kr.com/ (queue crawl delay=5000ms) -finishing thread FetcherThread, activeThreads=8 -finishing thread FetcherThread, activeThreads=7 -finishing thread FetcherThread, activeThreads=6 -finishing thread FetcherThread, activeThreads=5 -finishing thread FetcherThread, activeThreads=4 -finishing thread FetcherThread, activeThreads=3 -finishing thread FetcherThread, activeThreads=2 -finishing thread FetcherThread, activeThreads=1 -finishing thread FetcherThread, activeThreads=1 -finishing thread FetcherThread, activeThreads=0 -activeThreads=0, spinWaiting=0, fetchQueues.totalSize=0 -activeThreads=0 Fetcher: finished at 2013-09-29 12:10:32, elapsed: 00:00:02 ParseSegment: starting at 2013-09-29 12:10:32 ParseSegment: segment: crawl/segments/20130929121029 http://www.36kr.com/ skipped. Content of size 67099 was truncated to 59363 ParseSegment: finished at 2013-09-29 12:10:33, elapsed: 00:00:01 CrawlDb update: starting at 2013-09-29 12:10:33 CrawlDb update: db: crawl/crawldb CrawlDb update: segments: [crawl/segments/20130929121029] CrawlDb update: additions allowed: true CrawlDb update: URL normalizing: true CrawlDb update: URL filtering: true CrawlDb update: 404 purging: false CrawlDb update: Merging segment data into db. CrawlDb update: finished at 2013-09-29 12:10:34, elapsed: 00:00:01 Generator: starting at 2013-09-29 12:10:34 Generator: Selecting best-scoring urls due for fetch. Generator: filtering: true Generator: normalizing: true Generator: jobtracker is 'local', generating exactly one partition. Generator: 0 records selected for fetching, exiting ... Stopping at depth=1 - no more URLs to fetch. LinkDb: starting at 2013-09-29 12:10:35 LinkDb: linkdb: crawl/linkdb LinkDb: URL normalize: true LinkDb: URL filter: true LinkDb: internal links will be ignored. LinkDb: adding segment: file:/root/apache-nutch-1.7/crawl/segments/20130929121029 LinkDb: finished at 2013-09-29 12:10:36, elapsed: 00:00:01 crawl finished: crawl |
<property>
<name>parser.skip.truncated</name>
<value>false</value>
</property>
参考:http://lucene.472066.n3.nabble.com/Content-Truncation-in-Nutch-2-1-MySQL-td4038888.html
修改后再次执行爬虫任务,已经能够正常抓取了:
bin/nutch crawl urls -dir crawl
Solr安装
下载安装文件curl -O http://mirrors.cnnic.cn/apache/lucene/solr/4.4.0/solr-4.4.0.tgz
tar -xvzf solr-4.4.0.tgz
cd solr-4.4.0/example
java -jar start.jar
验证Solr安装(假设安装在本机)
http://localhost:8983/solr/
集成Nutch与Solr
vi + /etc/profile| NUTCH_RUNTIME_HOME=/root/apache-nutch-1.7APACHE_SOLR_HOME=/root/solr-4.4.0export JAVA_HOME JRE_HOME PATH CLASSPATH NUTCH_RUNTIME_HOME APACHE_SOLR_HOME |
mkdir ${APACHE_SOLR_HOME}/example/solr/conf
cp ${NUTCH_RUNTIME_HOME}/conf/schema.xml ${APACHE_SOLR_HOME}/example/solr/conf/
重新启动solr的start程序
java -jar start.jar
建立索引:
bin/nutch crawl urls -dir crawl -depth 2 -topN 5 -solr http://localhost:8983/solr/
索引出错:
| Active IndexWriters : SOLRIndexWriter solr.server.url : URL of the SOLR instance (mandatory) solr.commit.size : buffer size when sending to SOLR (default 1000) solr.mapping.file : name of the mapping file for fields (default solrindex-mapping.xml) solr.auth : use authentication (default false) solr.auth.username : use authentication (default false) solr.auth : username for authentication solr.auth.password : password for authentication Exception in thread "main" java.io.IOException: Job failed! at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1357) at org.apache.nutch.indexer.IndexingJob.index(IndexingJob.java:123) at org.apache.nutch.indexer.IndexingJob.index(IndexingJob.java:81) at org.apache.nutch.indexer.IndexingJob.index(IndexingJob.java:65) at org.apache.nutch.crawl.Crawl.run(Crawl.java:155) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65) at org.apache.nutch.crawl.Crawl.main(Crawl.java:55) |
| 2859895 [qtp1478922764-16] INFO org.apache.solr.update.processor.LogUpdateProcessor ? [collection1] webapp=/solr path=/update params={wt=javabin&version=2} {} 0 1 2859902 [qtp1478922764-16] ERROR org.apache.solr.core.SolrCore ? org.apache.solr.common.SolrException: ERROR: [doc=http://www.36kr.com/] unknown field 'host' at org.apache.solr.update.DocumentBuilder.toDocument(DocumentBuilder.java:174) at org.apache.solr.update.AddUpdateCommand.getLuceneDocument(AddUpdateCommand.java:73) at org.apache.solr.update.DirectUpdateHandler2.addDoc(DirectUpdateHandler2.java:210) at org.apache.solr.update.processor.RunUpdateProcessor.processAdd(RunUpdateProcessorFactory.java:69) at org.apache.solr.update.processor.UpdateRequestProcessor.processAdd(UpdateRequestProcessor.java:51) at org.apache.solr.update.processor.DistributedUpdateProcessor.doLocalAdd(DistributedUpdateProcessor.java:556) at org.apache.solr.update.processor.DistributedUpdateProcessor.versionAdd(DistributedUpdateProcessor.java:692) at org.apache.solr.update.processor.DistributedUpdateProcessor.processAdd(DistributedUpdateProcessor.java:435) at org.apache.solr.update.processor.LogUpdateProcessor.processAdd(LogUpdateProcessorFactory.java:100) at org.apache.solr.handler.loader.XMLLoader.processUpdate(XMLLoader.java:246) at org.apache.solr.handler.loader.XMLLoader.load(XMLLoader.java:173) at org.apache.solr.handler.UpdateRequestHandler$1.load(UpdateRequestHandler.java:92) at org.apache.solr.handler.ContentStreamHandlerBase.handleRequestBody(ContentStreamHandlerBase.java:74) at org.apache.solr.handler.RequestHandlerBase.handleRequest(RequestHandlerBase.java:135) at org.apache.solr.core.SolrCore.execute(SolrCore.java:1904) at org.apache.solr.servlet.SolrDispatchFilter.execute(SolrDispatchFilter.java:659) at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:362) at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:158) at org.eclipse.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1419) at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:455) at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:137) at org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:557) at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:231) at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1075) at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:384) at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:193) at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1009) at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:135) at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:255) at org.eclipse.jetty.server.handler.HandlerCollection.handle(HandlerCollection.java:154) at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:116) at org.eclipse.jetty.server.Server.handle(Server.java:368) at org.eclipse.jetty.server.AbstractHttpConnection.handleRequest(AbstractHttpConnection.java:489) at org.eclipse.jetty.server.BlockingHttpConnection.handleRequest(BlockingHttpConnection.java:53) at org.eclipse.jetty.server.AbstractHttpConnection.content(AbstractHttpConnection.java:953) at org.eclipse.jetty.server.AbstractHttpConnection$RequestHandler.content(AbstractHttpConnection.java:1014) at org.eclipse.jetty.http.HttpParser.parseNext(HttpParser.java:953) at org.eclipse.jetty.http.HttpParser.parseAvailable(HttpParser.java:235) at org.eclipse.jetty.server.BlockingHttpConnection.handle(BlockingHttpConnection.java:72) at org.eclipse.jetty.server.bio.SocketConnector$ConnectorEndPoint.run(SocketConnector.java:264) at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:608) at org.eclipse.jetty.util.thread.QueuedThreadPool$3.run(QueuedThreadPool.java:543) at java.lang.Thread.run(Thread.java:724) 2859920 [qtp1478922764-16] INFO org.apache.solr.update.processor.LogUpdateProcessor ? [collection1] webapp=/solr path=/update params={wt=javabin&version=2} {} 0 5 2859921 [qtp1478922764-16] ERROR org.apache.solr.core.SolrCore ? org.apache.solr.common.SolrException: ERROR: [doc=http://www.36kr.com/] unknown field 'host' at org.apache.solr.update.DocumentBuilder.toDocument(DocumentBuilder.java:174) at org.apache.solr.update.AddUpdateCommand.getLuceneDocument(AddUpdateCommand.java:73) at org.apache.solr.update.DirectUpdateHandler2.addDoc(DirectUpdateHandler2.java:210) at org.apache.solr.update.processor.RunUpdateProcessor.processAdd(RunUpdateProcessorFactory.java:69) at org.apache.solr.update.processor.UpdateRequestProcessor.processAdd(UpdateRequestProcessor.java:51) at org.apache.solr.update.processor.DistributedUpdateProcessor.doLocalAdd(DistributedUpdateProcessor.java:556) at org.apache.solr.update.processor.DistributedUpdateProcessor.versionAdd(DistributedUpdateProcessor.java:692) at org.apache.solr.update.processor.DistributedUpdateProcessor.processAdd(DistributedUpdateProcessor.java:435) at org.apache.solr.update.processor.LogUpdateProcessor.processAdd(LogUpdateProcessorFactory.java:100) at org.apache.solr.handler.loader.XMLLoader.processUpdate(XMLLoader.java:246) at org.apache.solr.handler.loader.XMLLoader.load(XMLLoader.java:173) at org.apache.solr.handler.UpdateRequestHandler$1.load(UpdateRequestHandler.java:92) at org.apache.solr.handler.ContentStreamHandlerBase.handleRequestBody(ContentStreamHandlerBase.java:74) at org.apache.solr.handler.RequestHandlerBase.handleRequest(RequestHandlerBase.java:135) at org.apache.solr.core.SolrCore.execute(SolrCore.java:1904) at org.apache.solr.servlet.SolrDispatchFilter.execute(SolrDispatchFilter.java:659) at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:362) at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:158) at org.eclipse.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1419) at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:455) at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:137) at org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:557) at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:231) at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1075) at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:384) at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:193) at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1009) at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:135) at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:255) at org.eclipse.jetty.server.handler.HandlerCollection.handle(HandlerCollection.java:154) at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:116) at org.eclipse.jetty.server.Server.handle(Server.java:368) at org.eclipse.jetty.server.AbstractHttpConnection.handleRequest(AbstractHttpConnection.java:489) at org.eclipse.jetty.server.BlockingHttpConnection.handleRequest(BlockingHttpConnection.java:53) at org.eclipse.jetty.server.AbstractHttpConnection.content(AbstractHttpConnection.java:953) at org.eclipse.jetty.server.AbstractHttpConnection$RequestHandler.content(AbstractHttpConnection.java:1014) at org.eclipse.jetty.http.HttpParser.parseNext(HttpParser.java:953) at org.eclipse.jetty.http.HttpParser.parseAvailable(HttpParser.java:235) at org.eclipse.jetty.server.BlockingHttpConnection.handle(BlockingHttpConnection.java:72) at org.eclipse.jetty.server.bio.SocketConnector$ConnectorEndPoint.run(SocketConnector.java:264) at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:608) at org.eclipse.jetty.util.thread.QueuedThreadPool$3.run(QueuedThreadPool.java:543) at java.lang.Thread.run(Thread.java:724) |
类似的还有其他一些字段需要补充,方法是编辑 ~/solr-4.4.0/example/solr/collection1/conf/schema.xml,在<field>…</fields>中增加以下的字段:
| <fields> <field name="host" type="string" stored="false" indexed="true"/> <field name="digest" type="string" stored="true" indexed="false"/> <field name="segment" type="string" stored="true" indexed="false"/> <field name="boost" type="float" stored="true" indexed="false"/> <field name="tstamp" type="date" stored="true" indexed="false"/> <field name="anchor" type="string" stored="true" indexed="true" </fields> |
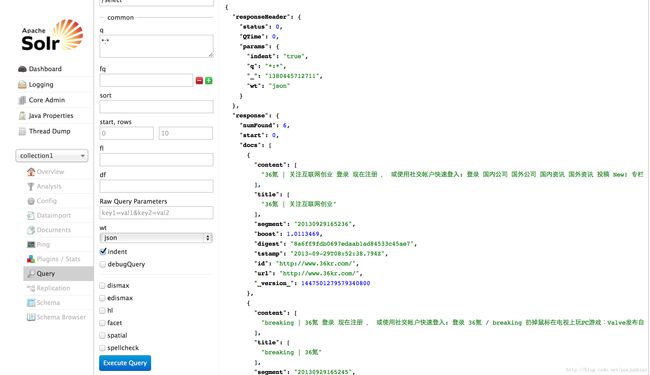
安装验证
重新开始抓取:| [root@localhost apache-nutch-1.7]# rm crawl/ -Rf [root@localhost apache-nutch-1.7]# bin/nutch crawl urls -dir crawl -depth 2 -topN 5 -solrhttp://localhost:8983/solr/ crawl started in: crawl rootUrlDir = urls threads = 10 depth = 2 solrUrl=http://localhost:8983/solr/ topN = 5 Injector: starting at 2013-09-29 15:27:35 Injector: crawlDb: crawl/crawldb Injector: urlDir: urls Injector: Converting injected urls to crawl db entries. Injector: total number of urls rejected by filters: 0 Injector: total number of urls injected after normalization and filtering: 1 Injector: Merging injected urls into crawl db. Injector: finished at 2013-09-29 15:27:38, elapsed: 00:00:02 Generator: starting at 2013-09-29 15:27:38 Generator: Selecting best-scoring urls due for fetch. Generator: filtering: true Generator: normalizing: true Generator: topN: 5 Generator: jobtracker is 'local', generating exactly one partition. Generator: Partitioning selected urls for politeness. Generator: segment: crawl/segments/20130929152740 Generator: finished at 2013-09-29 15:27:41, elapsed: 00:00:03 Fetcher: Your 'http.agent.name' value should be listed first in 'http.robots.agents' property. Fetcher: starting at 2013-09-29 15:27:41 Fetcher: segment: crawl/segments/20130929152740 Using queue mode : byHost Fetcher: threads: 10 Fetcher: time-out divisor: 2 QueueFeeder finished: total 1 records + hit by time limit :0 Using queue mode : byHost Using queue mode : byHost fetching http://www.36kr.com/ (queue crawl delay=5000ms) Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Fetcher: throughput threshold: -1 Fetcher: throughput threshold retries: 5 -finishing thread FetcherThread, activeThreads=8 -finishing thread FetcherThread, activeThreads=7 -finishing thread FetcherThread, activeThreads=6 -finishing thread FetcherThread, activeThreads=5 -finishing thread FetcherThread, activeThreads=4 -finishing thread FetcherThread, activeThreads=3 -finishing thread FetcherThread, activeThreads=2 -finishing thread FetcherThread, activeThreads=1 -finishing thread FetcherThread, activeThreads=1 -finishing thread FetcherThread, activeThreads=0 -activeThreads=0, spinWaiting=0, fetchQueues.totalSize=0 -activeThreads=0 Fetcher: finished at 2013-09-29 15:27:43, elapsed: 00:00:02 ParseSegment: starting at 2013-09-29 15:27:43 ParseSegment: segment: crawl/segments/20130929152740 Parsed (25ms):http://www.36kr.com/ ParseSegment: finished at 2013-09-29 15:27:45, elapsed: 00:00:02 CrawlDb update: starting at 2013-09-29 15:27:45 CrawlDb update: db: crawl/crawldb CrawlDb update: segments: [crawl/segments/20130929152740] CrawlDb update: additions allowed: true CrawlDb update: URL normalizing: true CrawlDb update: URL filtering: true CrawlDb update: 404 purging: false CrawlDb update: Merging segment data into db. CrawlDb update: finished at 2013-09-29 15:27:47, elapsed: 00:00:01 Generator: starting at 2013-09-29 15:27:47 Generator: Selecting best-scoring urls due for fetch. Generator: filtering: true Generator: normalizing: true Generator: topN: 5 Generator: jobtracker is 'local', generating exactly one partition. Generator: Partitioning selected urls for politeness. Generator: segment: crawl/segments/20130929152749 Generator: finished at 2013-09-29 15:27:50, elapsed: 00:00:03 Fetcher: Your 'http.agent.name' value should be listed first in 'http.robots.agents' property. Fetcher: starting at 2013-09-29 15:27:50 Fetcher: segment: crawl/segments/20130929152749 Using queue mode : byHost Fetcher: threads: 10 Fetcher: time-out divisor: 2 QueueFeeder finished: total 5 records + hit by time limit :0 Using queue mode : byHost Using queue mode : byHost fetching http://www.36kr.com/category/breaking (queue crawl delay=5000ms) Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Using queue mode : byHost Fetcher: throughput threshold: -1 Fetcher: throughput threshold retries: 5 -activeThreads=10, spinWaiting=10, fetchQueues.totalSize=4 * queue: http://www.36kr.com maxThreads = 1 inProgress = 0 crawlDelay = 5000 minCrawlDelay = 0 nextFetchTime = 1380439675396 now = 1380439671274 0. http://www.36kr.com/p/206589.html 1. http://www.36kr.com/category/cn-news 2. http://www.36kr.com/category/column 3. http://www.36kr.com/guolee89 -activeThreads=10, spinWaiting=10, fetchQueues.totalSize=4 * queue: http://www.36kr.com maxThreads = 1 inProgress = 0 crawlDelay = 5000 minCrawlDelay = 0 nextFetchTime = 1380439675396 now = 1380439672275 0. http://www.36kr.com/p/206589.html 1. http://www.36kr.com/category/cn-news 2. http://www.36kr.com/category/column 3. http://www.36kr.com/guolee89 -activeThreads=10, spinWaiting=10, fetchQueues.totalSize=4 * queue: http://www.36kr.com maxThreads = 1 inProgress = 0 crawlDelay = 5000 minCrawlDelay = 0 nextFetchTime = 1380439675396 now = 1380439673277 0. http://www.36kr.com/p/206589.html 1. http://www.36kr.com/category/cn-news 2. http://www.36kr.com/category/column 3. http://www.36kr.com/guolee89 -activeThreads=10, spinWaiting=10, fetchQueues.totalSize=4。。。-activeThreads=10, spinWaiting=10, fetchQueues.totalSize=1 * queue: http://www.36kr.com maxThreads = 1 inProgress = 0 crawlDelay = 5000 minCrawlDelay = 0 nextFetchTime = 1380439690613 now = 1380439690291 0. http://www.36kr.com/guolee89 fetching http://www.36kr.com/guolee89 (queue crawl delay=5000ms) -finishing thread FetcherThread, activeThreads=9 -finishing thread FetcherThread, activeThreads=8 -finishing thread FetcherThread, activeThreads=7 -finishing thread FetcherThread, activeThreads=6 -finishing thread FetcherThread, activeThreads=5 -finishing thread FetcherThread, activeThreads=4 -finishing thread FetcherThread, activeThreads=3 -finishing thread FetcherThread, activeThreads=2 -finishing thread FetcherThread, activeThreads=1 -finishing thread FetcherThread, activeThreads=0 -activeThreads=0, spinWaiting=0, fetchQueues.totalSize=0 -activeThreads=0 Fetcher: finished at 2013-09-29 15:28:12, elapsed: 00:00:22 ParseSegment: starting at 2013-09-29 15:28:12 ParseSegment: segment: crawl/segments/20130929152749 Parsed (8ms):http://www.36kr.com/category/breaking Parsed (6ms):http://www.36kr.com/category/cn-news Parsed (6ms):http://www.36kr.com/category/column Parsed (3ms):http://www.36kr.com/guolee89 Parsed (6ms):http://www.36kr.com/p/206589.html ParseSegment: finished at 2013-09-29 15:28:14, elapsed: 00:00:02 CrawlDb update: starting at 2013-09-29 15:28:14 CrawlDb update: db: crawl/crawldb CrawlDb update: segments: [crawl/segments/20130929152749] CrawlDb update: additions allowed: true CrawlDb update: URL normalizing: true CrawlDb update: URL filtering: true CrawlDb update: 404 purging: false CrawlDb update: Merging segment data into db. CrawlDb update: finished at 2013-09-29 15:28:15, elapsed: 00:00:01 LinkDb: starting at 2013-09-29 15:28:15 LinkDb: linkdb: crawl/linkdb LinkDb: URL normalize: true LinkDb: URL filter: true LinkDb: internal links will be ignored. LinkDb: adding segment: file:/root/apache-nutch-1.7/crawl/segments/20130929152740 LinkDb: adding segment: file:/root/apache-nutch-1.7/crawl/segments/20130929152749 LinkDb: finished at 2013-09-29 15:28:16, elapsed: 00:00:01 Indexer: starting at 2013-09-29 15:28:16 Indexer: deleting gone documents: false Indexer: URL filtering: false Indexer: URL normalizing: false Active IndexWriters : SOLRIndexWriter solr.server.url : URL of the SOLR instance (mandatory) solr.commit.size : buffer size when sending to SOLR (default 1000) solr.mapping.file : name of the mapping file for fields (default solrindex-mapping.xml) solr.auth : use authentication (default false) solr.auth.username : use authentication (default false) solr.auth : username for authentication solr.auth.password : password for authentication Indexer: finished at 2013-09-29 15:28:19, elapsed: 00:00:03 SolrDeleteDuplicates: starting at 2013-09-29 15:28:19 SolrDeleteDuplicates: Solr url: http://localhost:8983/solr/ SolrDeleteDuplicates: finished at 2013-09-29 15:28:20, elapsed: 00:00:01 crawl finished: crawl |
检索抓取到的内容,用浏览器打开 http://localhost:8983/solr/#/collection1/query