
Updated to cover latest Lucene.Net 3.0.3! Happy New Year!
Introduction
Have you ever heard of Lucene.Net? If not, let me introduce it briefly.
Lucene.Net is a line-by-line port of popular Apache Lucene, which is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search. Especially, an application where you want to achieve something close to Google search results, and no just search results, but very fast search results, or may be just insanely fast search results, but only in your app and on your terms!
So, while technically possibly, though somewhat challenging, you can integrate original Apache Lucene into your .NETapplication, and it will give you insanely fast search. But it will take quite a while, and will probably force to cut corners here and there, thus making your site way too complex and error prone. So, unless you absolutely have to have the fastest search on the planet (and beat Google along the way), you shouldn't go this way, as for majority of .NETapplications Lucene.Net will be madly fast anyway.
Main purpose of Lucene.Net is to be easy to integrate into any .NET application and provide most of the speed and flexibility of the original Java-based library. And it does it pretty good! You will learn that in this article. Even originalApache Lucene documentation applies to Lucene.Net 99% of the time!
You might ask: "why bother with Lucene.Net? My SQL Server returns search results pretty fast anyway...". Yeah I thought that too, until I tried Lucene.Net.
First of all, I discovered that Lucene is still faster than SQL query. And it is absolutely fast when searching for some text or pharase, no matter how many words are in your search. For example, when you search for a sentense of five different words in some text or description and want results to be in an order of relevance, in a same way that major web search engines do. How would you do it in SQL? Or .NET?... Your code might get very complex, and search querries long and complicated... That may become equivalent to slow-turtlish kind of search...
Good news are that Lucene.Net solves most of those problems for you! No need to write complicated search logic anymore! All you need to do is to correctly integrate it into you application! And that is what this article is about!
So, if you are interested in trying Lucene.Net for you .NET web site or application, continue reading, and prepare to embrace some love for Lucene!
Small disclaimer, sort of)):
I am not an expert in Lucene, and this article is not only about Lucene, it is rather about how to make it work in you.NET app/site. Hence, there will not be any advanced Lucene topics covered (at least initially), only what is needed to get it working.
Article Contents
Scenario
- An objective we will achieve by the end of this article
Installation
I. Installing via NuGet
- How to install Lucene.Net via NuGet package manager
II. Installing manually
- How to install Lucene.Net via manual download
Implementing search, Step-by-Step
- Steps you need to take in order to built basic Lucene.Net search
Step 1 - create sample data source
Step 2 - create base empty Lucene search class
Step 3 - add Lucene search index directory handler
Step 4 - add methods for Adding data to Lucene search index
Step 5 - add methods for deleting and optimizing data from Lucene search index
Step 6 - add methods to map Lucene search index data to SampleData
Step 7 - add main search method
Step 8 - add public methods that call main search method
Using the Code
- Sample project and Github download links
References
- What was used as a source, inspiration, and theory about Lucene.Net
Points of Interest
- What I have learned while working on that article
History
- Dated list of article and attached sample site updates
Scenario
This article represents a simple scenario of a search using Lucene.Net:
Given:
- You have some data source (most probably a database) which has some distinctive textual data in it
You need to be able to:
- Create Lucene search index from all the data in you data source and delete the whole index
- Add single record to Lucene search index and delete single record from it
- Search all fields in the Lucene search index and get matching records from Lucene search index ordered by their relevance
- Search by a particular field in the Lucene search index and get matching records from Lucene search indexordered by their relevance
We will create a search in this scenario step-by-step, so you can understand how it all works. I wil explain more about what Lucene search index is in corresponding steps.
Installation
Of course, first we need to install Lucene.Net library itself, don't we?
I. Installing via NuGet
The easiest and preffered way to do that is to install Lucene.Net NuGet package.
Method 1 - using NuGet Package Manager Console
Open Package Manager Console in Visual Studio by clicking:
View > Other Windows > Package Manager Console
And once console will pop at the bottom, lets first search for 'lucene', by typing
'get-package -remote -filter lucene' in the prompt:
Screenshot 1.
From the search results we can see that there is a number of different packages available for us. For the most part those packages only extend default Lucene.Net functionality. They will be not covered in this article, but you can play with them later on your own. The only package we will need is a barebone Lucene.Net.
So, to install it let's type 'install-package Lucene.Net':
Screenshot 2.

And, boom! NuGet did a good job again - Lucene.Net is installed and referenced!
Method 2 - using NuGet UI tool
If you are not a fan of typing stuff into any sorts of consoles ("...Console? Console?! what a nonsense, sir/madam!...") or it is not working for any reason, you can use neat NuGet UI. Right click on your project and then click on 'Manage NuGet Packages...':
Screenshot 3.
A nice and clean window will pop up. There, first select: Online > All, then in the search box type 'Lucene.Net', than select Lucene.Net from the list and hit 'Install' (I got it installed already, so it shows green icon instead of 'Install' button):
Screenshot 4.
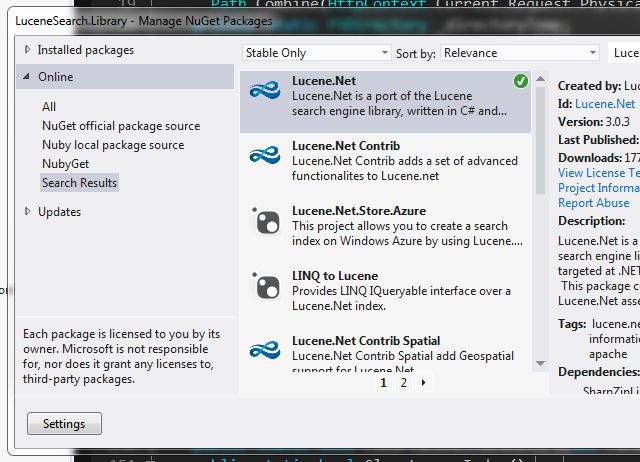
And, that's it you are ready to go!
II. Installing manually
Alternatively you can just download Lucene.Net here - Download Lucene Binaries from official site.
After that, manually copy lucene.net.dll from archive to you bin folder and manually reference it.
So, once everything is installed, let's proceed with our search implementation!
Implementing search, Step-by-Step
Step 1 - create sample data source
In order to use Lucene.Net, we need firstly to create Lucene search index from some set of data (most probably from database). Lucene search index is just a set of text files that Lucene.Net creates, and we'll create it later. So, for our tutorial, let's create an empty SampleData.cs file and add some generic data object into it:
namespace MvcLuceneSampleApp.Search { public class SampleData { public int Id { get; set; } public string Name { get; set; } public string Description { get; set; } } }
This class can represent any data you wish, and of course you can create your own class or use existing one. Also, whenever it will come to testing Lucene, you may want to create a simple static data source repository based on aSampleData class above, and you can stick that code into same SampleData.cs file, you've just created:
using System.Collections.Generic; using System.Linq; namespace MvcLuceneSampleApp.Search { public static class SampleDataRepository { public static SampleData Get(int id) { return GetAll().SingleOrDefault(x => x.Id.Equals(id)); } public static List<SampleData> GetAll() { return new List<SampleData> { new SampleData {Id = 1, Name = "Belgrad", Description = "City in Serbia"}, new SampleData {Id = 2, Name = "Moscow", Description = "City in Russia"}, new SampleData {Id = 3, Name = "Chicago", Description = "City in USA"}, new SampleData {Id = 4, Name = "Mumbai", Description = "City in India"}, new SampleData {Id = 5, Name = "Hong-Kong", Description = "City in Hong-Kong"}, }; }}}
Step summary:
We have created sample data source with generic data class SampleData and sample repositorySampleDataRepository to retrieve our static data.
Step 2 - create base empty Lucene search class
Now let's create an empty LuceneSearch.cs file, and copy following there:
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Web; using Lucene.Net.Analysis.Standard; using Lucene.Net.Documents; using Lucene.Net.Index; using Lucene.Net.QueryParsers; using Lucene.Net.Search; using Lucene.Net.Store; using Version = Lucene.Net.Util.Version; namespace MvcLuceneSampleApp.Search { public static class LuceneSearch { //todo: we will add required Lucene methods here, step-by-step... } }
We will be adding all required methods to do all search related tasks to that class. At that moment you can make sure all your references are correct by building your site, and if build fails, fix your references.
Step summary:
We have created empty LuceneSearch class.
Step 3 - add Lucene search index directory handler
So, let's see what we got now - SampleData class, which represents some data, and LuceneSearch class which is supposed to do a search. But it's empty. So, it needs some code to do the job, right?
A small prerequisite first. Lucene.Net needs to build its search index, which, as I mentioned earlier, is basically a set of files generated by Lucene in some local directory. So, we need to add a special property to LuceneSearch class which represents a handler for a local directory that will store search index:
private static string _luceneDir = Path.Combine(HttpContext.Current.Request.PhysicalApplicationPath, "lucene_index"); private static FSDirectory _directoryTemp; private static FSDirectory _directory { get { if (_directoryTemp == null) _directoryTemp = FSDirectory.Open(new DirectoryInfo(_luceneDir)); if (IndexWriter.IsLocked(_directoryTemp)) IndexWriter.Unlock(_directoryTemp); var lockFilePath = Path.Combine(_luceneDir, "write.lock"); if (File.Exists(lockFilePath)) File.Delete(lockFilePath); return _directoryTemp; }}
Here _luceneDir is a full physical path to the folder, and "lucene_index" is a name of that folder, which sits in an application root. So naturally you also need to create this directory manually or write some code that creates it automatically.
Then, _directory is an instance of Lucene.Net class FSDirectory, and will be used by all of the search methods to access search index.
Step summary:
We have added Lucene search index directory handler to make our LuceneSearch class ready to have search methods added.
Step 4 - add methods for Adding data to Lucene search index
Lucene will create search index based on some actual data, in our case it would be a List<SampleData> with several records, or singe SampleData record.
The first method we need, is a private method that creates a single search index entry based on our data, and it will be reused by public methods which we'll add later:
private static void _addToLuceneIndex(SampleData sampleData, IndexWriter writer) { // remove older index entry var searchQuery = new TermQuery(new Term("Id", sampleData.Id.ToString())); writer.DeleteDocuments(searchQuery); // add new index entry var doc = new Document(); // add lucene fields mapped to db fields doc.Add(new Field("Id", sampleData.Id.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED)); doc.Add(new Field("Name", sampleData.Name, Field.Store.YES, Field.Index.ANALYZED)); doc.Add(new Field("Description", sampleData.Description, Field.Store.YES, Field.Index.ANALYZED)); // add entry to index writer.AddDocument(doc); }
Basically, it takes one record with a class SampleData, maps it to Lucene class Document, and adds it to search indexusing IndexWriter. Please note how Name and DescriptionField.Index.ANALYZED parameter, while Id uses Field.Index.NOT_ANALYZED one. Basically you want to use ANALYZED only on text or single string properties, and NOT_ANALYZED on singular values, like integer Ids.
Now let's add public method that will use _addToLuceneIndex() in order to add a list of records to search index:
public static void AddUpdateLuceneIndex(IEnumerable<SampleData> sampleDatas) { // init lucene var analyzer = new StandardAnalyzer(Version.LUCENE_30); using (var writer = new IndexWriter(_directory, analyzer, IndexWriter.MaxFieldLength.UNLIMITED)) { // add data to lucene search index (replaces older entry if any) foreach (var sampleData in sampleDatas) _addToLuceneIndex(sampleData, writer); // close handles analyzer.Close(); writer.Dispose(); }}
Also, let's add another public method that will add a single record to search index:
public static void AddUpdateLuceneIndex(SampleData sampleData) { AddUpdateLuceneIndex(new List<SampleData> {sampleData}); }
The usage pattern of those two methods is simple - add all database records once:
// add all existing records to Lucene search index LuceneSearch.AddUpdateLuceneIndex(SampleDataRepository.GetAll());
Then whenever new record is being added to the database, call same method, only give it single record:
var new_record = new SampleData {Id = X, Name = "SomeName", Description = "SomeDescription"}; // todo: add record to database... // add record to Lucene search index LuceneSearch.AddUpdateLuceneIndex(new_record);
Step summary:
Now we can create the whole Lucene search index or add a single record to it.
Step 5 - add methods for deleting and optimizing data from Lucene search index
Whenever our database records are being deleted, they will have to be removed from Lucene search index too, otherwise your search will return records that might not exist in the database. let's first add a simple method to remove single record from Lucene search index by record's Id field:
public static void ClearLuceneIndexRecord(int record_id) { // init lucene var analyzer = new StandardAnalyzer(Version.LUCENE_30); using (var writer = new IndexWriter(_directory, analyzer, IndexWriter.MaxFieldLength.UNLIMITED)) { // remove older index entry var searchQuery = new TermQuery(new Term("Id", record_id.ToString())); writer.DeleteDocuments(searchQuery); // close handles analyzer.Close(); writer.Dispose(); } }
The code above basically searches for record by the field Id (and you can use any field of course), gets search results from index, and deletes all of them from index, and in our case it will usually delete single record, as long you always supply full and unique Id value.
Note: main Lucene search methods will be added later, and of course explained in more detail.
Secondy, whenever database schema changes, or you simply want to clear the whole index quickly, you would need a method to clear all index, so let's add that too:
public static bool ClearLuceneIndex() { try { var analyzer = new StandardAnalyzer(Version.LUCENE_30); using (var writer = new IndexWriter(_directory, analyzer, true, IndexWriter.MaxFieldLength.UNLIMITED)) { // remove older index entries writer.DeleteAll(); // close handles analyzer.Close(); writer.Dispose(); } } catch (Exception) { return false; } return true; }
This method simply removes the whole Lucene search index via a method built into Lucene IndexWriter.
Now probably is a good moment to mention that Lucene puts a "lock" on search index files, so when they are being updated or searched, so they cannot be altered. Also, it is important, that each file is "unlocked" because if some of the files would be deleted manually or by some code, and you try to search/update afterwards, it will cause your to see a lot of errors, and we don't want that, right?
So, in order to save ourselves from embarassment and our end users from righteous rage twards ourselves, we always need to .Close() and .Dispose() any Lucene handlers like IndexWriter and StandardAnalyzer.
Additionally, it would be beneficial to run Lucene search index optimization once in a while to speed up searches, especially if your index is getting bigger. So, let's add a small method to do just that:
public static void Optimize() { var analyzer = new StandardAnalyzer(Version.LUCENE_30); using (var writer = new IndexWriter(_directory, analyzer, IndexWriter.MaxFieldLength.UNLIMITED)) { analyzer.Close(); writer.Optimize(); writer.Dispose(); } }
Step summary:
We added three methods - ClearLuceneIndexRecord() to delete single record from Lucene search index,ClearLuceneIndex() to delete all records in the index, and Optimize() method to optimize large indices for faster search.
Step 6 - add methods to map Lucene search index data to SampleData
Hang in there, folks, this step is the last one, before we'll be adding our main search methods!
Now before we can search, do you remember how our _addToLuceneIndex() method from Step 4, mapped our database data to Lucene search index? Well, to get our search results in a form of List<SampleData> or similar, we need a function that will map index to our class SampleData, and here it is:
private static SampleData _mapLuceneDocumentToData(Document doc) { return new SampleData { Id = Convert.ToInt32(doc.Get("Id")), Name = doc.Get("Name"), Description = doc.Get("Description") }; }
So, method above will get Lucene Document h from index (where each field is represented as a string), and will map it to SampleData. Pretty simple, right?
In addition we need two more methods to map a List of Lucene Documents, and a List of Lucene ScoreDocs, each returned by different Lucene search method, and more on that in Step 7 and 8. Both of those methods reuse method_mapLuceneDocumentToData() we defined above:
private static IEnumerable<SampleData> _mapLuceneToDataList(IEnumerable<Document> hits) { return hits.Select(_mapLuceneDocumentToData).ToList(); } private static IEnumerable<SampleData> _mapLuceneToDataList(IEnumerable<ScoreDoc> hits, IndexSearcher searcher) { return hits.Select(hit => _mapLuceneDocumentToData(searcher.Doc(hit.Doc))).ToList(); }
Step summary:
We added methods to map results returned by Lucene to our data class to be reused on our site. Method_mapLuceneDocumentToData() maps Lucene Document with search results from index to our class SampleData, and method _mapLuceneToDataList() in turn maps a list of Lucene Documents or ScoreDocs.
Step 7 - add main search method
And finally, the main search method. It will search Lucene search index by a particular field (Id, Name, or Description) whenever we'll supply its name, or, alternatively it will search all three fields, which is a basis for universal search somewhat similar to your_favourite internet search engine. You may notice that it is still a private method. The reason for that is that this method is universal for any Lucene query.
Lucene query is a little more than just text you are searching for. Basic example is when the query looks like "Mumbai", Lucene will search for exact match for this word, and if query is like "Mum*" then all fields with words starting with "Mum" would be returned as search results. There is definitely many more ways to write advancedLucene querries, but that won't be covered in this article.
In our case, query would be provided by a public method, which will format you search request for a particular search scenario, and it will be added in Step 8. Our scenario is that the private search method below shouldn't change much, and only public one will be ajusted for our search needs.
As a small prerequisite, add this method first:
private static Query parseQuery(string searchQuery, QueryParser parser) { Query query; try { query = parser.Parse(searchQuery.Trim()); } catch (ParseException) { query = parser.Parse(QueryParser.Escape(searchQuery.Trim())); } return query; }
What this method will do, is basically parse your search query string into Lucene Query object, and if parsing fails, it will fix whatever symbols are causing it to fail and return fixed Query object.
And now let's add our main search method:
private static IEnumerable<SampleData> _search (string searchQuery, string searchField = "") { // validation if (string.IsNullOrEmpty(searchQuery.Replace("*", "").Replace("?", ""))) return new List<SampleData>(); // set up lucene searcher using (var searcher = new IndexSearcher(_directory, false)) { var hits_limit = 1000; var analyzer = new StandardAnalyzer(Version.LUCENE_30); // search by single field if (!string.IsNullOrEmpty(searchField)) { var parser = new QueryParser(Version.LUCENE_30, searchField, analyzer); var query = parseQuery(searchQuery, parser); var hits = searcher.Search(query, hits_limit).ScoreDocs; var results = _mapLuceneSearchResultsToDataList(hits, searcher); analyzer.Close(); searcher.Dispose(); return results; } // search by multiple fields (ordered by RELEVANCE) else { var parser = new MultiFieldQueryParser (Version.LUCENE_30, new[] { "Id", "Name", "Description" }, analyzer); var query = parseQuery(searchQuery, parser); var hits = searcher.Search (query, null, hits_limit, Sort.RELEVANCE).ScoreDocs; var results = _mapLuceneSearchResultsToDataList(hits, searcher); analyzer.Close(); searcher.Dispose(); return results; } } }
Of course our private _search() method has many points to be ajusted, and optimized, and it will be up to you to ajust it to your particular needs.
Did you notice var hits_limit = 1000;? As I mentioned in Step 5, when Lucene gets more than 1000 search results, it becomes increasingly slow, so you'd want to limit it to a number which is relevant in your case.
If you add new fields to your index, don't forget to add field names to be searched to this line in multiple fields search like here:
var parser = new MultiFieldQueryParser (Version.LUCENE_30, new[] { "Id", "Name", "Description", "NEW_FIELD" }, analyzer);
Just remember that results returned by _search() method will be ordered by Sort.RELEVANCE, which means that more accurate results will be returned first. Another option is Sort.INDEXORDER, which returns results in the order they've been added to search index. However for most scenarios Sort.RELEVANCE will work just fine.
Step summary:
We added primary private _search() method that will perform searches by single field or multiple fields in Lucene search index based on the search query supplied.
Step 8 (and the last one) - add public methods which call main search method
Our little search engine is practically done right now. Now it is the time to add last methods that will interface with our site or app.
The first one simply formats Lucene search query and calls main private search method _search():
public static IEnumerable<SampleData> Search(string input, string fieldName = "") { if (string.IsNullOrEmpty(input)) return new List<SampleData>(); var terms = input.Trim().Replace("-", " ").Split(' ') .Where(x => !string.IsNullOrEmpty(x)).Select(x => x.Trim() + "*"); input = string.Join(" ", terms); return _search(input, fieldName); }
It replaces all dashes "-" in your search requests, and adds "*" (star) after each word, so that you can search by partial words.
So, basically, method Search() above is pretty much your main playground, where you customize your querries to get perfect search results.
Also, for trying out native Lucene search querries we can add default search method SearchDefault(), which doesn't format your query in any manner:
public static IEnumerable<SampleData> SearchDefault(string input, string fieldName = "") { return string.IsNullOrEmpty(input) ? new List<SampleData>() : _search(input, fieldName); }
Search on the internet about writing advanced and precise Lucene search querries, try them usingSearchDefault() function, then you can modify Search() method to better suit your needs.
As I mentioned in Step 5, now we are also adding a method to return the whole Lucene search index:
public static IEnumerable<SampleData> GetAllIndexRecords() { // validate search index if (!System.IO.Directory.EnumerateFiles(_luceneDir).Any()) return new List<SampleData>(); // set up lucene searcher var searcher = new IndexSearcher(_directory, false); var reader = IndexReader.Open(_directory, false); var docs = new List<Document>(); var term = reader.TermDocs(); while (term.Next()) docs.Add(searcher.Doc(term.Doc)); reader.Dispose(); searcher.Dispose(); return _mapLuceneToDataList(docs); }
Remember, use it wisely, beacause the larger the index gets, the longer it takes to load it all.
Step summary:
We added two methods that so far finalize our basic LuceneSearch class - first method is Search(), which formatsLucene search query, and searches by all fields or by a single field. Second method is GetAllIndexRecords() which merely returns all records in the search index.
Using the Code
Congratulations! If you made it so far in this article, it means you are probably ready and want to put your newLuceneSearch class to test. Or probably your already tested it along the way and got it all and now researching Lucene online documentation)).
To demonstrate it all in action, along with the simple UI, I went ahead and created a sample project for Visual Studio 2012 (including MVC and WebForms examples) that uses all the code from that article and provides a simple interface for Lucene.Net.
- Download sample project
- Fork me on Github
Alternatively, if you have Git installed (if not, read how to setup Git on Windows), create a local clone (copy) of this project on your computer by running this in the bash console (create some folder, right click on it, select 'Git Bash Here', copy command below, and paste into into console via Shift+Insert):
git clone [email protected]:mikhail-tsennykh/Lucene.Net-search-MVC-sample-site.git
And I guess that is the end of this article. I sincerely hope Lucene.Net will speed up your searches and your life!
I hope this article was at least somewhat helpful! Let me know what you think!
References
I used those articles as a source of Lucene.Net inspiration and knowledge. They are quite outdated, but you can find quite a deal of theory and in-depth knowledge on Lucene (with adjustments to the latest Lucene.Net):
- How to get started with Lucene.net
- Lucene.net: the main concepts
- Dissecting Lucene.net storage: Documents and Fields
- Lucene.net: your first application
Points of Interest
While working on this article I somehow developed a warm and sincere relationship with Git))
So, I would humbly suggest - discover inner Git in yourself by reading about it on the official Git site or in Git - simple guide!
History
- 1/2/2013 - updated article and sample project to cover latest Lucene.Net 3.0.3, converted sample project to Visual Studio 2012 and .NET 4.5
- 2/23/2012 - added a better way to parse Lucene search query (thanks to Gavin Harriss for the tip!), in thesample search site added SearchDefault() method to search using raw Lucene query, so sample search site is at version v.1.3 now!
- 2/9/2012 - removed
writer.Optimize()from search methods, since it may degrade search performance, and placed it into separateOptimize()method to be called manually or on schedule (thanks to dave.dolan for the tip!). Also addedanalyzer.Close()line to several methods, as not closedanalyzerwas causing errors in some occasions. Sample search site is updated to v.1.2! - 2/7/2012 -
ClearLuceneIndex()method is updated to a built-in way of clearing the whole Lucene search index (thanks to ENOTTY for this tip!), sample search site is updated to v.1.1 - 2/2/2012 - Cleaned and updated attached sample search site, few small article updates as well
- 2/1/2012 - Initial article about using Lucene.Net 2.9.4 is released along with sample search site v.1.0