MyCCL特征码定位原理学习
这段时间学习WEB方面的技术,遇到了木马免杀特征码定位的问题,这里做一下学习笔记。
这里对MyCCL的分块原理做一下探究
对指定文件生成10个切块
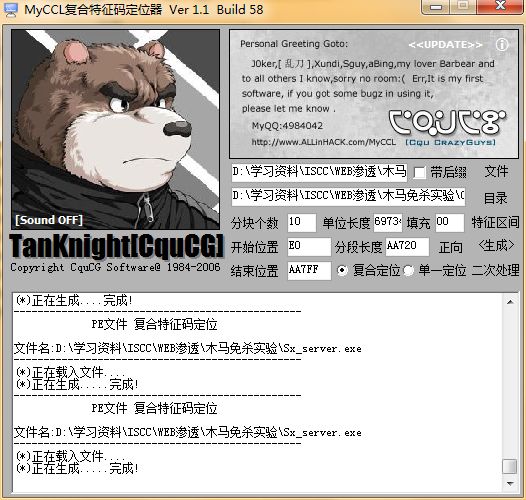
对指定的木马进行切块后,文件列表是这样的。

注意这里是从E0作为切块的偏移量。也就是说从E0的位置开始逐个切块,E0之前的内容是保留的。这样做的目的是保留一些PE必须的头文件信息。
我们来通过亲身的探究来解析一下MyCCL的切块区间定位法到底什么意思,之后再从理论角度入手解释这个原理。
我们打开第一个文件
0000_000000E0_000110B6,用winhex查看。
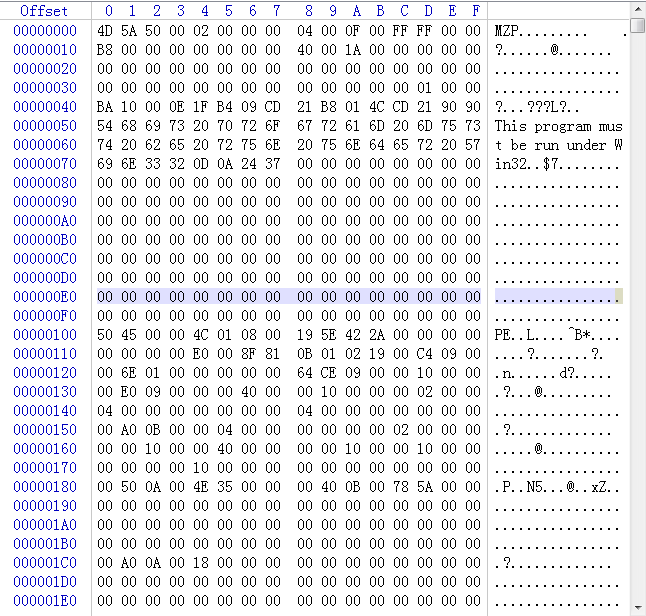
我们发现E0之前的内容是完整保存的。也就是我们指定的起始位置之前的内容不参与切块,因为病毒特征码也不可能在这块区域内。
从文件名我们知道,第一个文件的切块范围为000000E0_000110B6。那我们定位到000110B6看看那里的情况。
因为000000E0 + 000110B6 = 00011198,第一个文件(第一个切块的范围是): 000000E0_00011198。然后后面的数据全部被填充为00。(文件名的第三段代表偏移量)
在继续打开顺序的第二个文件:0001_00011196_000110B6。首先从文件名中可以知道,这个文件的开始正好就是第一个文件的结束。然后我们用winhex打开。定位到00011196这个位置看看。

这次从00011196这个位置开始,一直到0002224C的位置, 原始数据都一直被保留,到0002224C之后的数据又被填充为00了。而0002224C的位置正好就是第三个文件的开始位置。
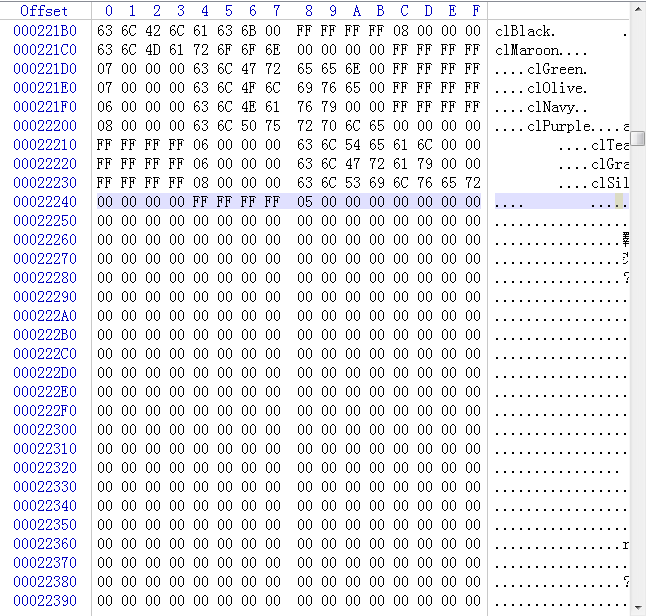
看到这里我们应该明白了,MyCCL所做的事情就是在不断的恢复出原始数据的过程,只不过这个这个动作是分成好几步(块)慢慢来进行的。
如果特征码不在之前的某几块的范围内的话,那杀软在查杀的时候也不会杀除这些文件,因此前几块那些不包含特征码的块文件就会在查杀的时候被保留下来。
我感觉要更清晰的理解原理的话最好是用手工一个文件一个文件顺序的方法进行查毒,直到某一个块文件查处有病毒。则说明这个块文件多露出的那一块原始数据包含了病毒特征码。
那我们的第一个分块的目的就达到了,我们找到了特征码的大致范围,就在刚才多露出的这个块原始数据块中,则这个被查处有病毒的块对应的起始地址和终止地址就我们第一切块的结果。
我们定位特征码的位置,既不能说是看被查出有毒的,也不能说是没被查出有毒的。准确说是第一个被查出有毒的。第一此被查出有毒的那个区段就是特征码的一个范围。
这里假设我们在查杀第二文件的时候查出有病毒,那后面的文件也不用查了,肯定也有病毒,因为它们同样包含了第二个区段。一般我们用手工的查杀方法,查出第二个文件有毒然后清除这个文件。

0001_00011196_000110B6这个文件被删除了
然后,我们点击”二次处理”时MyCCL就能发现第二个文件不见了,就能定位出一个特征区间。看清楚,是MyCCL发现了第二个文件不见了。它就知道了这个特征码是在第二个区段内。
现在明白了为什么有的人杀到一个病毒就停止查杀了吧?因为按顺序摆放,找到某处特征码时,后面的暂时没必要管。为什么说是暂时呢?接下来继续解释。
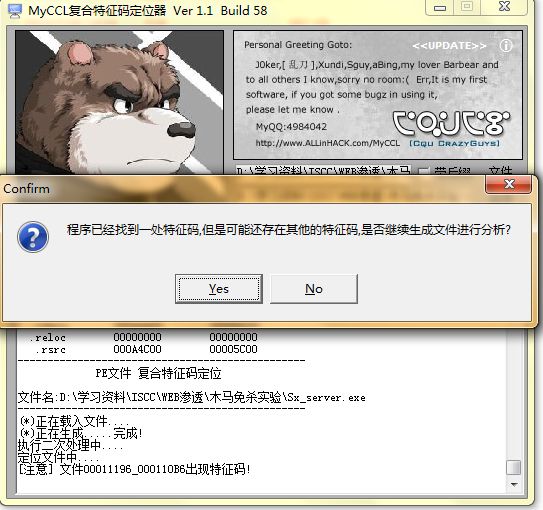
因为现在的杀毒软件一般是复合定位,也就是说多特征码定位,而且发现任何一处特征码就能确定出病毒来,所以MyCCL在确定出一处特征码(这里是第二个文件块)时,会提醒用户要不要继续分析。此时当然选"是"了,这个时候又会生成十个切片。
这次又生成的10(你自己设定的切块数量)个切片就有意思了。
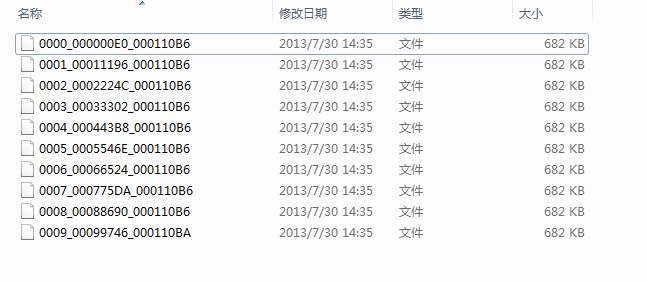
可以看到依然是和第一次的10个块文件一样的分区范围,但是,内容给也是一样的吗 ?我们继续用winhex查看内容,之后再慢慢解释原理。
我们打开第一个文件0000_000000E0_000110B6,然后直接定位到00011198
第一个文件依然是一样的。我们继续打开第二个文件:0001_00011196_000110B6
用winhex打开0001_00011196_000110B6。
好,这次发现不同了,在第一次的生成切块过程中,我们知道,MyCCL是逐步露出原始数据的,那道理第二个文件中应该从00011196位置开始把原始数据露出来了呀?难道是MyCCL程序出错了吗?
当然不是的。
因为这是二次分块定位,第二个文件块我们已经确认是有病毒的了,不需要再用杀软来确认了,所以MyCCL直接填充00,而是从第三个文件开始逐步露出原始数据。不急,我们先实验一下验证一下这个观点。
打开第三个文件:0002_0002224C_000110B6,定位到0002224C的位置。

可以看到,确实和我们说的一样,从第三个文件开始逐步露出原始数据。我们再定位到文件块3的结束位置:00033302,也是第四个文件的开始位置。
由此可以得知,后面的处理过程和之前的第一次分块是一样的原理了。差别就在二次分块时默认将第一次中找到的那块直接填充00了,就不再露出来了。
结果就是二次定位后也同样会生成10个块文件。
我们依然可以从头顺序开始逐个用杀软进行查杀(不过我感觉可以直接从刚才找到的第一个带特征码的文件块后面开始继续试探查杀)。直到再次发现那个首次发现病毒的文件块,则我们要找的第二个病毒特征码就在那个文件块中。
以此类推,还可以继续点击”二次处理”寻找第三个,第四个特征码,只要文件块还没遍历完。但是要注意的是,每次点击”二次处理”生成文件,才能用杀软继续顺序查一次,即每次只能找到一个特征码位置,然后要再次点击”二次处理”。 如果在二次分块的查杀验证中直到最后一个文件块都没有再出现病毒警报的话,则说明这个病毒程序就只有一个病的特征码。即之前找到的那个,整个过程需要杀软的配合。
至此,我们就算完成了第一轮的切片范围搜索,但是这个时候定位的范围太大了,我们需要继续进行精确定位,缩小范围。
点击特征区间,会出现我们之前找到的特征码范围。
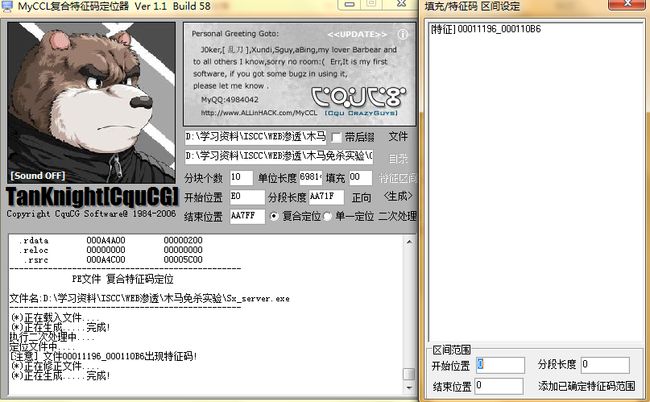
可以看出: 00011196_000110B6就是文件名本身,意思是这个范围就是整个分块本身,非常大,接下来我们要重复上面的过程继续一次定位及二次定位。
右键点击重新复合定位。

接下来的步骤就有点像是算法中的递归,这次的范围缩小了,我们以:
0001_00011196_000110B6
这个范围作为原始文件的大小,注意看开始位置和结束位置。
这次的搜索范围被集中到:00011196_000110B6。或者也可以理解为0001_00011196_000110B6这个文件现在相当于原始文件了,我们从这个范围中继续搜索特征码。
我们继续通过实践验证我们的观点。重新修改分块数目为10,点击生成。

注意到,这次生成的文件列表中。第一个文件就是0000_00011196_00001B45,即直接从00011196这个位置开始了。
打开第一个文件:0000_00011196_00001B45。
我们先观察一下E0的位置

可以看到,还是之前说的原理,起始地址之前的数据是被保留的。只是从我们指定的起始位置开始分块。
现在我们直接定位到00012CDB位置,也就是第二个文件的开始位置。
可以看到,这次分块的行为模式和之前的原理上是一样的。
现在,为了加深映像,让我们再打开倒数第二个文件:0008_0001EBBE_00001B45。
并定位到00020703的位置,也即最后一个文件结束的位置。

再打开最后一个文件:0009_00020703_00001B4A,定位到2224C,也即一开始指定的结束位置。

可以看到在结束位置2224C之后的内容也依然存在。也就说MyCCL对于我们指定的范围外的数据不做任何处理,只会对我们指定的范围内的数据进行切块。
我研究到这里的时候,就有一个疑问了,那这样要是木马病毒有复合特征怎么办呢?即在第一次的切块搜索中搜索出了2处以上的特征码位置,我们选择其中一处缩小范围,进行进一步的搜索,然后MyCCL只在我们指定的范围内进行切块,那这个范围外的那一处特征码就将一直存在了,那我们第二轮切块中每一个文件不就都会查出有病毒了吗?
带着这个疑问,我们重新做一次实验,在第一轮切块搜索的的时候模拟出有两处特征码,即手工删掉2个文件(和杀软杀掉本质上是一样的)
- 重新打开MyCCL,生成10个切块,并删掉第二个文件0001_00011196_000110B6
- 点击”二次处理”,重新生成10个文件,在提示是否要继续搜索特征码的对话框中点确认,这次删除第九个文件:0008_00088690_000110B6
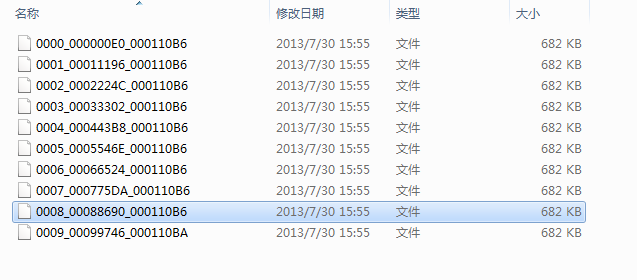
- 删除后,再次点击二次处理,让MyCCL发现又有一个文件不在了,即又找到了一个特征码位置。
结束后,右边显示共找到了两处特征码位置。
- 选择第一处位置:00011196_000110B6,右键,继续复合特征码查找。

注意这个时候的起始位置和结束位置就是第二文件的范围,点击生成。
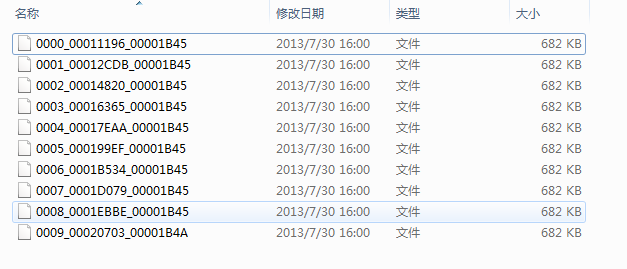
- 我们来打开第一个文件:0000_00011196_00001B45。其他的位置我们都了解了,现在关键是第九个文件的位置0008_00088690_000110B6是我们要重点关注的。
先定位到00088690的位置。
可以看到,和我们的理论猜想一样,这块内容被填充了00,和”二次处理时”要把之前找到的特征码位置填充00的思想是一样的,为了不影响本次的范围内切块搜索。要反范围外的特征码位置填充00,其他位置就保持不变。
搞清楚了以上几点后,我们就可以以此类推,不断递归的缩小范围,直到能把特征码的范围缩小到20字节一下,基本就差不多了。
国内外的杀软一般是根据一些字符组合来判断是否是病毒,在20字节一下基本能帮组我们对特征码进行定位判断。
顺便介绍个在线测试病毒的网站http://www.virscan.org/。国内外流行的杀毒引擎都在里面了。杀软的话推荐用COMODO,很好用,性能也很好,我一直在用这款。