C++常见容器概述
以前的11个容器分别是
deque,list,queue,priority_queue,stack,vector,map,multimap,set,multiset,bitset
C++11新增:
array,forward_list,unordered_map,unordered_multimap,unordered_set,unordered_multiset
这里只挑常用的讲解。部分容器只作列表,没作讲述,持续更新。
以下内容只做大概的讲述,详情用法参考英文文档 http://www.cplusplus.com/reference/s 或者中文文档 http://classfoo.com/ccby/article/oC7Qu#sec_HL85sR
1.deque
deque双向队列是一种双向开口的连续线性空间(虽说是连续性存储空间,但这种连续性只是表面上的,实际上它的内存是动态分配的,它在堆上分配了一块一块的动态储存区,每一块动态存储去本身是连续的,deque自身的机制把这一块一块的存储区虚拟地连在一起。),可以高效的在头尾两端插入和删除元素,deque在接口上和vector非常相似。
deque的实现比较复杂,内部会维护一个map(注意!不是STL中的map容器)即一小块连续的空间,该空间中每个元素都是指针,指向另一段(较大的)区域,这个区域称为缓冲区,缓冲区用来保存deque中的数据。因此deque在随机访问和遍历数据会比vector慢。
如果只是平时使用deque的话,可能就想不到其内部实现细节了。下面的图片展示deque的内部结构设计:
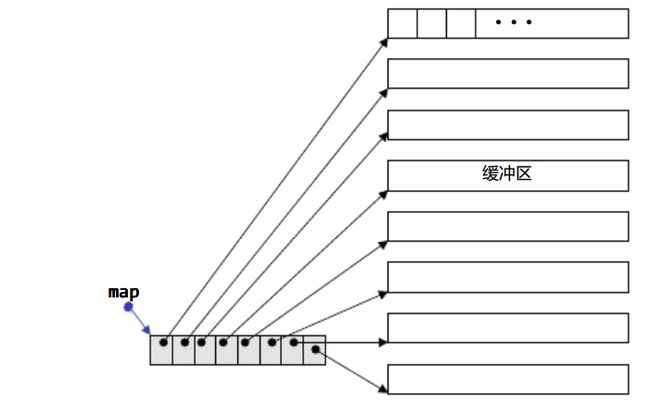
可以看到,deque拥有一个bitmap结构(称之为map),map中每一个元素指向一块连续的内存块,后者才是真正存储deque元素的地方,因为每个块都是固定大小的,但是每个块之间不要求是连续的,所以扩充空间的时候,就没有vector那样的副作用了。
鉴于deque的特殊设计,其迭代器也需要特殊设计,deque的iterator的设计结构如图:
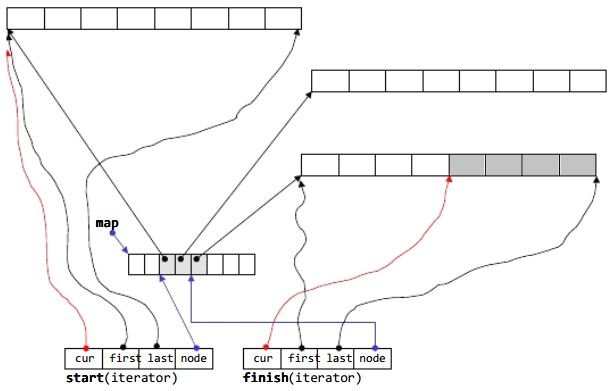
迭代器内部维护了四个指针,分别为cur, first, last, node,具体在后面进行介绍。
deque的迭代器的设计,主要是让其看起来像一个random access iterator,因此源码主要各种operator的重载。内部结构分为四个指针,分别为cur, first, last, node。
在某一个时刻,迭代器肯定指向某个具体元素,而这个元素位于N段连续内存块中的某一块,其中node指向map结构中的一个节点(这个节点指向当前的内存块),first指向当前内存块的起始位置,cur指向当前内存块中的特定元素节点,last指向当前内存块的末尾位置,一图抵千言,还是看图来的明白:
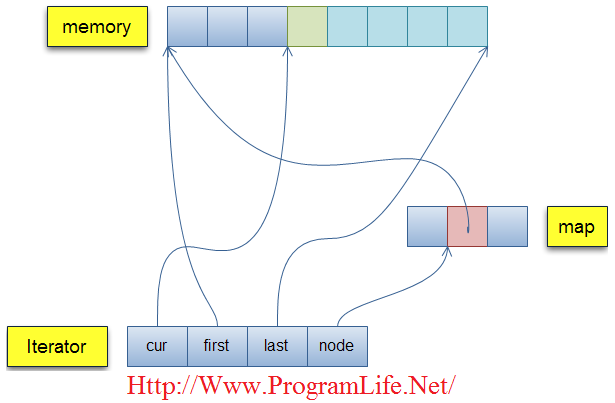
[堆1]
...
[堆2]
...
[堆3]
每个堆保存好几个元素,然后堆和堆之间有指针指向,看起来像是list和vector的结合品,不过确实也是如此 deque可以让你在前面快速地添加删除元素,或是在后面快速地添加删除元素,然后还可以有比较高的随机访问速度. vector是可以快速地在最后添加删除元素,并可以快速地访问任意元素 list是可以快速地在所有地方添加删除元素,但是只能快速地访问最开始与最后的元素
另外要注意一点。对于deque和vector来说,尽量少用erase(pos)和erase(beg,end)。因为这在中间删除数据后会导致后面的数据向前移动,从而使效率低下。
它首次插入一个元素,默认会动态分配512字节空间,当这512字节空间用完后,它会再动态分配自己另外的512字节空间,然后虚拟地连在一起。deque的这种设计使得它具有比vector复杂得多的架构、算法和迭代器设计。它的性能损失比之vector,是几个数量级的差别。所以说,deque要慎用.
deque在开始和最后添加元素都一样快,并提供了随机访问方法,像vector一样使用[]访问任意元素,但是随机访问速度比不上vector快,因为它要内部处理堆跳转。deque也有保留空间.另外,由于deque不要求连续空间,所以可以保存的元素比vector更大,这点也要注意一下.还有就是在前面和后面添加元素时都
不需要移动其它块的元素,所以性能也很高。
以下情形,最好采用deque:
1)需要在两端插入和删除元素。
2)无需引用容器内的元素。
3)要求容器释放不再使用的元素。
2.list
list是双向循环链表,,每一个元素都知道前面一个元素和后面一个元素。在STL中,list和vector一样,是两个常被使用的容器。和vector不一样的是,list不支持对元素的任意存取。list中提供的成员函数与vector类似,不过list提供对表首元素的操作push_front、pop_front,这是vector不具备的。和vector另一点不同的是,list的迭代器不会存在失效的情况,他不像vector会保留备份空间,在超过容量额度时重新全部分配内存,导致迭代器失效;list没有备份空间的概念,出入一个元素就申请一个元素的空间,所以它的迭代器不会失效。
3.queue
队列是一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。在队列这种数据结构中,最先插入在元素将是最先被删除;反之最后插入的元素将最后被删除,因此队列又称为“先进先出”(FIFO—first in first out)的线性表。
4.priority_queue
5.stack
c++stack(堆栈)是一个容器的改编,它实现了一个先进后出的数据结构(FILO)
6.vector
vector是STL中最常见的容器,它是一种顺序容器,支持随机访问。vector是一块连续分配的内存,从数据安排的角度来讲,和数组极其相似,不同的地方就是:数组是静态分配空间,一旦分配了空间的大小,就不可再改变了;而vector是动态分配空间,随着元素的不断插入,它会按照自身的一套机制不断扩充自身的容量。
vector的扩充机制:按照容器现在容量的一倍进行增长。vector容器分配的是一块连续的内存空间,每次容器的增长,并不是在原有连续的内存空间后再进行简单的叠加,而是重新申请一块更大的新内存,并把现有容器中的元素逐个复制过去,然后销毁旧的内存。这时原有指向旧内存空间的迭代器已经失效,所以当操作容器时,迭代器要及时更新。
详情见 http://blog.csdn.net/saya_/article/details/49178021
7.map
C++中map容器提供一个键值对容器,map与multimap差别仅仅在于multiple允许一个键对应多个值。map是一类关联式容器,它是模板类。关联的本质在于元素的值与某个特定的键相关联,而并非通过元素在数组中的位置类获取。它的特点是增加和删除节点对迭代器的影响很小,除了操作节点,对其他的节点都没有什么影响。对于迭代器来说,不可以修改键值,只能修改其对应的实值。
map的功能:
1.自动建立Key - value的对应。key 和 value可以是任意你需要的类型,但是需要注意的是对于key的类型,唯一的约束就是必须支持<操作符。
2.根据key值快速查找记录,查找的复杂度基本是Log(N),如果有1000个记录,最多查找10次,1,000,000个记录,最多查找20次。
3.快速插入Key - Value 记录。
4.快速删除记录
5.根据Key 修改value记录。
6.遍历所有记录。
8.multimap
9.set
关于set,必须说明的是set关联式容器。set作为一个容器也是用来存储同一数据类型的数据类型,并且能从一个数据集合中取出数据,在set中每个元素的值都唯一,而且系统能根据元素的值自动进行排序。应该注意的是set中数元素的值不能直接被改变。C++ STL中标准关联容器set, multiset, map, multimap内部采用的就是一种非常高效的平衡检索二叉树:红黑树,也成为RB树(Red-Black Tree)。RB树的统计性能要好于一般平衡二叉树,所以被STL选择作为了关联容器的内部结构。
看下面的代码
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> s;
s.insert(2);
s.insert(1);
auto it=s.begin();
*it = 2;//error,不能修改值
for (auto x : s)
cout << x << endl;
return 0;
}
在set中查找是使用二分查找,也就是说,如果有16个元素,最多需要比较4次就能找到结果,有32个元素,最多比较5次。那么有10000个呢?最多比较的次数为log10000,最多为14次,如果是20000个元素呢?最多不过15次。看见了吧,当数据量增大一倍的时候,搜索次数只不过多了1次,多了1/14的搜索时间而已。你明白这个道理后,就可以安心往里面放入元素了。
10.multiset
11.bitset
有些程序要处理二进制位的有序集,每个位可能包含的是0(关)或1(开)的值。位是用来保存一组项或条件的yes/no信息(有时也称标志)的简洁方法。标准库提供了bitset类使得处理位集合更容易一些。注意下面的看不懂可以去我开头推荐的网址,查看使用例子。
- (constructor)
- Construct bitset (public member function) //构造bitset.. 格式 bitset<长度> 名字
- applicable operators
- Bitset operators (functions) //可以直接对bitset容器进行二进制操作,如 ^,|,~,<<,>>等等
- operator[]
- Access bit (public member function) //可以用如数组形式的赋值。bitset<4> b; b[0]=1;
- set
- Set bits (public member function)//默认将容器中所有值赋为1,也可以将特定的位置赋给特定的值
- 如 bitset<4> b; b.set(); //1111. b.set(2,0) // 1011.
- reset
- Reset bits (public member function) //默认将容器中所有值赋值为0,也可以将特定位置赋特定的值
- flip
- Flip bits (public member function)//默认将容器中的数取反,1变0,0变1,也可以将特定位置取反bitset<4> b(string ("0001")); b.file(2); // 0101; b.file(); //1010
- to_ulong
- Convert to unsigned long integer (public member function) //将容器的值转化成10进制的数
- to_string
- Convert to string (public member function) //将容器累的值转为字符串
- count
- Count bits set (public member function) //统计容器中1的个数
- size
- Return size (public member function) //容器的大小
- test
- Return bit value (public member function) //返回每个位置上的数
- any
- Test if any bit is set (public member function) //容器的值>0返回真,反之。
- none
- Test if no bit is set (public member function) //和any取反。容器的值==0返回真。反之
下面转载一篇博客,原址是 http://blog.chinaunix.net/uid-24790746-id-252685.html
1.定义一个unsigned long型的副本
例:
unsigned long tmp = 1111;
bitset<32> bitvec(tmp);
那么把bitvec对象给cout出来是:00000000000000000000000000001111吗?
答案显示是不对的,前几天我马虎了,原来bitset类的构造函数把tmp的十进制值给转换到了二进制(10001010111),所以
bitvec输出是:00000000000000000000010001010111。
如果想让tmp直接输出00000000000000000000000000001111的话,那么只需将tmp更改为十六进制0xf即可(unsgined long tmp = 0xf)。
2.定义一个string型的副本
例:
string str("1111");
bitset<32> bitvec(str);
那么bitvec对象cout出来就是:00000000000000000000000000001111。
好了,我前几天遇到的问题出来了,现在拿string型的副本来讨论,现在bitset里面到底是怎么存储str对象的字符串字面值呢??
bitvec对象里面存储的是00000000000000000000000000001111,
还是11110000000000000000000000000000呢?
还没遇到这个模糊问题的时候,我用cout输出bitvec对象的值,跟我用for循环从bitvec对象的第0位输出到第31位的结果竟然是不一样的。。
当执行:cout << bitvec; //result = 00000000000000000000000000001111;
当执行:
for (unsigned int ix = 0; ix != 32; ++ix)
{
cout << bitvec[ix];
}
//result = 11110000000000000000000000000000
现在已经很清楚的知道,bitvec对象是把string对象里面的值先转换成二进制值,然后再倒过来存储。
用1111可能看得不是很清楚,
那么现在:
string str("1010");
bitset<32> bitvec(str);
通过上面那个for循环输出的结果是:01010000000000000000000000000000,
这样看起来就比较直观了。一般平时要输出bitset对象时,都是用cout输出,因为cout已经重载了各种各样的运算符,用for循环输出只是为了更加深入的去理解bitset罢了。
#include <iostream>
#include <bitset>
/*顺便提一下,这里为什么不直接使用"using namespace std;"比较简便了,因为这样对于比较大的程序来
说不是很好的习惯,因为使用这句话虽然简便了,但是这样导致把std命名空间的所有标准库函数都引进到程序文件里,这样如
果以后程序涉及到同名函数名或变量名,将会出现难以调试的错误*/
using std::cout;
using std::endl;
using std::bitset;
int main()
{
bitset<32> bitvec("1010");
//1.
cout << bitvec;
cout << endl;
//2.
for (int ix = 0; ix != bitvec.size(); ++ix)
{
cout << bitvec[ix];
}
cout << endl;
//3.
for (int ix = bitvec.size() - 1; ix != -1; --ix)
{
cout << bitvec[ix];
}
cout << endl;
/*
00000000000000000000000000001010
01010000000000000000000000000000
00000000000000000000000000001010
*/
return 0;
}
12.forward_list
13.unordered_map
14.unordered_multimap
15.unordered_set
16.unordered_multiset