XML解析(二),DOM解析XML
上篇文章向大家介绍了SAX解析XML,为了这篇文章理解起来更加方便,所以还没看过SAX解析XML文章的,请戳这【XML解析(一)】SAX解析XML ,这次给大家带来XML解析系列之DOM解析XML
一、概述
DOM,擦,这什么鬼,肯定又是什么东西的简称了,没错,DOM是Document Object Model的简称,翻译过来就是文档对象模型,是W3C组织推荐的处理可扩展标志语言的标准编程接口,它以面向对象的方式描述了文档模型,所以有一个名词叫对象树,也叫文档树。借用百度的一张图片描述一下这个文档树
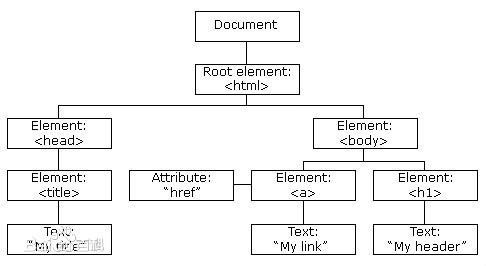
关于这个文档树,有几个名词需要知道:
节点(Node):XML中的每个成分都是节点
- 文档节点:即图中的:Document
- 每个标签是一个原元素节点即:Element
- XML元素标签之间的为文本节点:TextNode
- 每个XML元素节点的属性为属性节点:Attribute
xml常见的节点类型
- Node : DOM最基本的数据类型
- Element:常见的元素节点
- Attr:代表元素的属性
- Text:元素或者Att的值(内容)
- Document:代表整个XML文档
细心看过SAX解析XML那篇文章的朋友可能发现了在那篇文章中没少出现标签,节点,文档的字眼,其实这些名词是借用DOM的。OK,对于DOM如要需要了解更多请google或者百度一下,下面我们看看DOM解析XML的优缺点:
DOM解析优点:
- 整个文档树在内存中,便于操作;
- 可以修改,删除、重新排列XML;
- 可以随机访问任何一个节点,访问效率高。
DOM解析的缺点:
- 占用内存大,占用资源多
- 解析速度慢
DOM解析适用场合:
- 需多次访问这些数据;
- 对解析效率要求不高;
- 硬件资源充足(内存、CPU)。
二、DOM解析XML实战
DOM解析XML步骤很简单,基本就两步,我们只需要知道DOM的层次结构及很实用DOM的一些重要的方法就可以使用DOM解析XML了
为了方便,这里先给出项目的目录结构,在文章结束后会将本Demo的代码帖上
目录结构:
解析步骤:
- 解析XML文件得到Document对象
- 操作Document对象的一系列方法取出我们关心的数据
DOM的一些常用的方法:
- Document.getDocumentElement():返回xml文档的根元素
- Element.getAttribute():获取属性值
- Element.getChildNodes():返回孩子节点集
- Element.getFirstChild():返回第一个孩子节点,通常是TextNode
- Element.getLastChild():得到最后一个孩子节点
- …
ps:DOM 相关的API的一些方法基本见名知义,在使用的时候可以查看相应的API文档或者借助Eclipse等IDE的提示选择相应的方法使用。
OK,知道了DOM解析XML的步骤及方法,我们新建一个Android项目开始学习一下DOM解析过程
新建一个Android项目DomParseXmlDemo,为了和SAX解析做个比较,我们还是来通过解析的users.xml来练习一下DOM解析。
1、 新建一个xml文件,users.xml
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="1">
<name>毕向东</name>
<password>bxd123</password>
</user>
<user id="2">
<name>韩顺平</name>
<password>hsp123</password>
</user>
<user id="3">
<name>马士兵</name>
<password>msb123</password>
</user>
</users>2、同样新建一个User类,User.java
package com.example.domparsexmldemo;
public class User{
private long id;
private String name;
private String password;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
3、简单将解析的步骤封装到一个工具类XmpParseUtils.java中,新建一个方法:
第一步:加载xml资源,得到XML的Document对象
// 1. 加载XML资源,这里和SAX一样,也可以是File或者Uri
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("users.xml");
// 2. 得到文档构建工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 3. 通过构建工厂生产构建类
DocumentBuilder newDocumentBuilder = factory.newDocumentBuilder();
// 4. 那这个构建类将XML资源解析得到Document对象
Document doc = newDocumentBuilder.parse(is);上面的代码基本上是一个模板代码,只是xml路径会不同,这里得到了Document的对象,完成了解析步骤的第一步,接下来完成第二步
第二步:操作Doc,解析相应的数据
// 得到根节点
Element root = doc.getDocumentElement();
// 根据指定的标签名称得到相应的节点集合
NodeList userNodes = root.getElementsByTagName("user");
for(int i=0;i<userNodes.getLength();i++){
// 依次解析每个user节点
Element userElement = (Element) userNodes.item(i);
// 获取user节点的属性
int id = Integer.valueOf(userElement.getAttribute("id"));
User user = new User();
user.setId(id);
// 接下来解析子元素
NodeList childNodes = userElement.getChildNodes();
for(int j=0;j<childNodes.getLength();j++){
Node childNode = childNodes.item(j);
if(childNode.getNodeType() == Node.ELEMENT_NODE){ // 判断是不是元素节点
String nodeName = childNode.getNodeName(); // 得到节点名称
String value = childNode.getFirstChild().getNodeValue(); // 得到第一个子节点的值,这里为TextNode
if("name".equals(nodeName)){ // 如果当前的节点为name,那么它的值就是user的name
user.setName(value);
}else if("password".equals(nodeName)){ // 如果当前的节点为password,那么它的值就是user的password
user.setPassword(value);
}
}
}
users.add(user);
}注释写的很详细,大家有没有注意到Element.getElementsByTagName(String tagName)方法,这个方法简直和html中document的一模一样,只不过这里的Document没有和html的document的getElementById()和getElementsByName()方法,这是因为xml和html不一样,xml标签,属性等系统没有赋予特殊的含义,都是自己定义的,是一种数据格式,而html的id或class属性被赋予了特殊含义,所以xml自然没有那两个方法了,呵呵
OK,万事具备,只差测试了,下面是见证奇迹的时刻
同样是使用Android的单元测试,关于Android的单元测试,和上篇【XML解析(一)】SAX解析XML一样,只需要改一下目标包名,这里就不多说了,有疑问的参考【XML解析(一)】SAX解析XML 这篇文章。
测试结果:
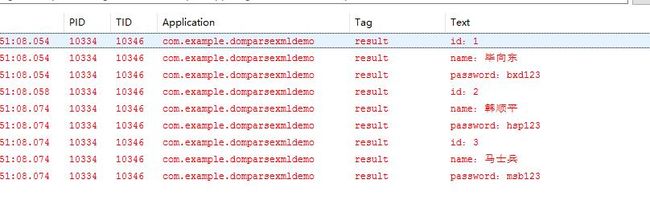
可以看到,这里我们使用DOM同样完成了XML的解析,到这里我们学会了DOM解析XML,对比一下SAX解析,发现DOM解析更加简单,原理无非拿到根节点,然后依次解析子节点,遍历循环,调用相应方法,没有事件触发,而我们只需要掌握XML DOC文档树的层次结构,然后解析相应xml的时候,对比着xml的内容,我们就可以操作DOC API相应的方法解析出相应数据了。
总结:DOM解析XML相对于SAX解析XML更加简单,掌握XML DOC文档树结构是掌握DOM解析XML的重中之重,可以说掌握了XML文档树结构,DOM解析XML就非常简单了,简单地调用一些方法即可。
上面这篇文章由于个人理解及学习笔记总结,如果有理解错的地方,欢迎大家指出,与君共勉,大家一起进步。