Alex 的 Hadoop 菜鸟教程: 第22课 分布式日志收集组件:flume
本教程的目的:
介绍一下概念
Event: 事件是从Flume agent发过来的一个数据流单元。事件从 Source 到 Channel 到 Sink。
Flume agen: 是一个jvm 进程。这个进程负责将外部的来源产生的Event转发到外部的目的地
Source: 负责消费有特殊格式的Event。这些Event会通过一个外部的来源(比如一个web服务器)传递给Source. 比如一个 AvroSource 用来接收由客户端或者在同一个流程上其他的Flume agent 发过来的 Avro Event (注意:flume的agent是可以一个接一个的串联起来的)
当Source接收到Event的时候,它会把Event存储到Channel(通道)里面。Channel被动的存储和保持Event直到Sink消费掉它
打个比方,有一种Channel叫 FileChannel,它使用文件系统来存储文件
Sink:用来从Channel中移除Event,并且把Event放到外部资源库,比如hdfs(这种Sink叫HDFSEventSink)。或者也可以继续把Event推送给在同一个流程中的下一个Source。
flume-ng — flume本身
flume-ng-agent — 把flume agent做成一个服务的脚本
flume-ng-doc — Flume 文档
测试一下
会输出帮助信息
介绍下 Logger Sink: 采用日志的形式来消费Event。日志级别为INFO
介绍下 Memory Channel : 使用内存来暂存Event
粘贴以下文本进example.conf并保存
如果没有错误的话,shell会保持监听状态,此时监听44444端口
这时去看之前监听的那个ssh窗口会打印出
然后重启flume
增加log4j.properties 到 src/main/resources 文件夹下,如果没有这个文件夹就自己建一个,并添加到 java build path 作为一个source folder 。
建立一个 FlumeLog.java
- flume 跟 hadoop 有什么关系
- 介绍flume的结构
- 介绍flume的安装
- 做一个简单的收集网络发送过来的文本(NetCat Source)并保存到日志文件(Logger Sink)的例子
flume 跟 hadoop 有什么关系
hadoop是一个分布式系统,跟hadoop配合的一般也是分布式系统,分布式系统带来的就是分布式日志,分布式日志带来1. 日志数量多 2. 日志数据量大, 所以无论是采集分布式的日志还是存储海量的日志到hadoop,都需要一个日志收集系统,这就是flume。不过其实关系也不是太大,日志方面没有太大需求的人其实可以跳过flume的学习
flume 结构
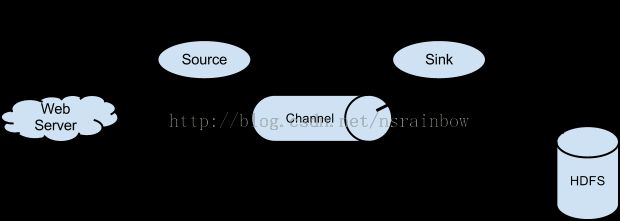
以下是一张解释flume如何工作的图
介绍一下概念
Event: 事件是从Flume agent发过来的一个数据流单元。事件从 Source 到 Channel 到 Sink。
Flume agen: 是一个jvm 进程。这个进程负责将外部的来源产生的Event转发到外部的目的地
Source: 负责消费有特殊格式的Event。这些Event会通过一个外部的来源(比如一个web服务器)传递给Source. 比如一个 AvroSource 用来接收由客户端或者在同一个流程上其他的Flume agent 发过来的 Avro Event (注意:flume的agent是可以一个接一个的串联起来的)
当Source接收到Event的时候,它会把Event存储到Channel(通道)里面。Channel被动的存储和保持Event直到Sink消费掉它
打个比方,有一种Channel叫 FileChannel,它使用文件系统来存储文件
Sink:用来从Channel中移除Event,并且把Event放到外部资源库,比如hdfs(这种Sink叫HDFSEventSink)。或者也可以继续把Event推送给在同一个流程中的下一个Source。
flume一般是这样用的
或者是这样的
安装 flume
flume有三个组件flume-ng — flume本身
flume-ng-agent — 把flume agent做成一个服务的脚本
flume-ng-doc — Flume 文档
$ yum install -y flume-ng flume-ng-agent flume-ng-doc
测试一下
$ flume-ng help
会输出帮助信息
使用flume
flume监听NetCat例子
Step1
介绍下 NetCat Source : 这个source会监听一个端口,然后把每行通过这个端口发过来的文本当做一个事件传给channel介绍下 Logger Sink: 采用日志的形式来消费Event。日志级别为INFO
介绍下 Memory Channel : 使用内存来暂存Event
$ vim /etc/flume-ng/conf/example.conf
粘贴以下文本进example.conf并保存
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
STEP 2 运行 flume
$ flume-ng agent --conf conf --conf-file /etc/flume-ng/conf/example.conf --name a1 -Dflume.root.logger=INFO,console
如果没有错误的话,shell会保持监听状态,此时监听44444端口
STEP 3 测试 flume
我们新打开一个ssh连接,然后使用curl 给 44444 端口发送一条测试文本:"hello world"$ curl -X GET http://localhost:44444?w=helloworld OK OK OK OK OK
这时去看之前监听的那个ssh窗口会打印出
14/07/04 11:39:12 INFO sink.LoggerSink: Event: { headers:{} body: 47 45 54 20 2F 3F 77 3D 68 65 6C 6C 6F 77 6F 72 GET /?w=hellowor }
14/07/04 11:39:12 INFO sink.LoggerSink: Event: { headers:{} body: 55 73 65 72 2D 41 67 65 6E 74 3A 20 63 75 72 6C User-Agent: curl }
14/07/04 11:39:12 INFO sink.LoggerSink: Event: { headers:{} body: 48 6F 73 74 3A 20 6C 6F 63 61 6C 68 6F 73 74 3A Host: localhost: }
14/07/04 11:39:12 INFO sink.LoggerSink: Event: { headers:{} body: 41 63 63 65 70 74 3A 20 2A 2F 2A 0D Accept: */*. }
14/07/04 11:39:12 INFO sink.LoggerSink: Event: { headers:{} body: 0D
以上是flume的最简单的例子,接下来介绍一个稍微复杂一点,但是真正实用的例子
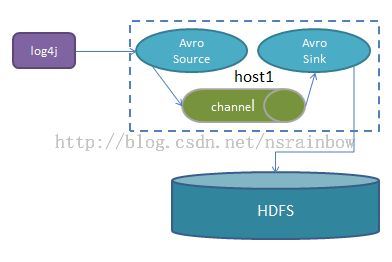
Flume 收集log4j日志文件并写入hdfs的例子
在这个例子中我们由本机将日志发送到host1上,并由host1上的flume将日志存储到hdfs上 。架构图
我们会用到 log4j的一个Appender FlumeAppender 这个插件,是由Flume开发的适用于log4j的Appender
step1
修改 /etc/flume-ng/conf/flume.conf 的内容为
# source, channel, sink definition agent.channels = mem-channel agent.sources = log4j-avro-source agent.sinks = hdfs-sink # Channel # Define a memory channel called mem-channel on agent agent.channels.mem-channel.type = memory # Source # Define an Avro source called log4j-avro-channel on agent and tell it # to bind to host1:12345. Connect it to channel mem-channel. agent.sources.log4j-avro-source.type = avro agent.sources.log4j-avro-source.bind = 192.168.1.126 agent.sources.log4j-avro-source.port = 12345 agent.sources.log4j-avro-source.channels = mem-channel # Sink # Define a logger sink that simply logs all events it receives # and connect it to the other end of the same channel. agent.sinks.hdfs-sink.type = hdfs agent.sinks.hdfs-sink.hdfs.path = hdfs://mycluster/flume/events/ agent.sinks.hdfs-sink.channel = mem-channel
然后重启flume
service flume-ng-agent restart
step2
在hdfs上建立flume要写的文件夹
sudo -u flume hdfs dfs -mkdir -p /flume/events/
step3
建立一个简单的maven项目叫 play-flume
pom.xml 的内容是
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.crazycake</groupId>
<artifactId>play-flume</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>play-flume</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.apache.flume.flume-ng-clients</groupId>
<artifactId>flume-ng-log4jappender</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}-${timestamp}</finalName>
<plugins>
<!-- compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5.1</version>
<inherited>true</inherited>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
<!-- jar -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<extensions>false</extensions>
<inherited>true</inherited>
</plugin>
</plugins>
</build>
</project>
增加log4j.properties 到 src/main/resources 文件夹下,如果没有这个文件夹就自己建一个,并添加到 java build path 作为一个source folder 。
log4j.properties 内容为
# Define the root logger with appender file
log4j.rootLogger = DEBUG, stdout, flume
# Redirect log messages to console
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
# Define the flume appender
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = host1
log4j.appender.flume.Port = 12345
log4j.appender.flume.UnsafeMode = false
log4j.appender.flume.layout=org.apache.log4j.PatternLayout
建立一个 FlumeLog.java
package org.crazycake.play_flume;
import org.apache.log4j.Logger;
public class FlumeLog {
public static void main(String[] args)
{
Logger logger = Logger.getLogger(App.class);
logger.info("hello world");
logger.info("My name is alex");
logger.info("How are you?");
}
}
step4
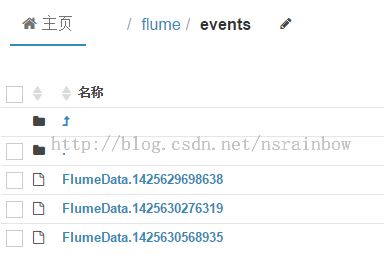
运行 FlumeLog.java ,然后等几秒钟就可以看到在 /flume/events 目录下生成的日志文件,不过是序列化成LongWritable 后的日志,无法直接查看
具体 LongWritable 是什么,究竟在怎么把 LongWritable 转化为文本读出来可以看相关的资料 [Hadoop源码解读](五)MapReduce篇之Writable相关类
你也可以用 HBaseSink 直接把日志写到Hbase里面,这样就更省事一点,再结合上 Phoenix 可以直接写SQL日志查出来,不过就丧失了 MapReduce 的特性,不过真的要做MapReduce也不是不可以,就自己写程序把日志导出来,再跑Map Reduce 就行了,具体的选择看应用场景决定,如果你只是查日志,那用Hbase就行了
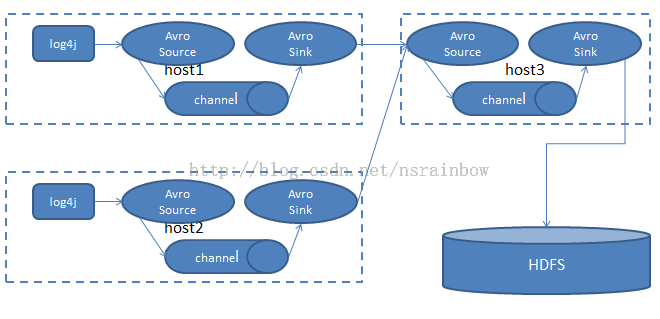
真实环境下的架构
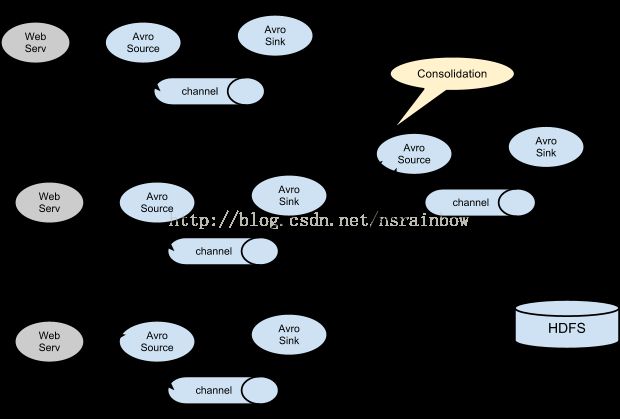
这个例子只是一个最简单的情况,真实环境的日志情况下,会有多台机器收集log4j生成的日志并统一存放到hdfs上。比如我们从host1 和 host2 上都收集日志,并通过其中一台机器的flume将日志保存到hdfs上。架构图
这样做的好处是
- 分散风险,提高容错率,因为flume本身有一个缓存机制,如果写入hdfs的flume出问题了,比如关机,或者升级,web服务器的日志还是可以收集,只是暂时先放在本机的硬盘上
- 缓解hdfs的写入压力,由于日志在各个层级被缓存了,并以一定的速度写入hdfs,这样不会造成hdfs的机器负载过大以致影响正常业务
参考资料
- http://flume.apache.org/FlumeUserGuide.html
- http://logging.apache.org/log4j/2.x/log4j-flume-ng/
- http://www.thecloudavenue.com/2013/11/using-log4jflume-to-log-application.html
- https://issues.apache.org/jira/browse/FLUME-2387