HBase深入分析之RegionServer
原文链接 http://www.binospace.com/index.php/hbase-in-depth-analysis-of-the-regionserver/?utm_source=tuicool
HBase深入分析之RegionServer
所有的用户数据以及元数据的请求,在经过Region的定位,最终会落在RegionServer上,并由RegionServer实现数据的读写操作。本小节将重点介绍RegionServer的代码结构和功能,从实现细节上深入理解RegionServer对于数据的操作流程。
1 RegionServer概述
RegionServer是HBase集群运行在每个工作节点上的服务。它是整个HBase系统的关键所在,一方面它维护了Region的状态,提供了对于Region的管理和服务;另一方面,它与Master交互,上传Region的负载信息上传,参与Master的分布式协调管理。具体如图(1)所示。
图(1) RegionServer的整体功能图
HRegionServer与HMaster以及Client之间采用RPC协议进行通信。HRegionServer向HMaster定期汇报节点的负载状况,包括RS内存使用状态、在线状态的Region等信息,在该过程中RS扮演了RPC客户端的角色,而HMaster扮演了RPC服务器端的角色。RS内置的RpcServer实现了数据更新、读取、删除的操作,以及Region涉及到Flush、Compaction、Open、Close、Load文件等功能性操作。此时,RS扮演了RPC服务的服务端的角色。RS与Client之间的RPC是HBase最为核心的操作,其服务状况的好坏,直接反映了RS内部、以及它所依赖的HDFS服务质量的好坏,因此,该过程的RPC经常成为分析读写性能异常的突破口。
从RegionServer实现的功能上而言,除了与HMaster和Client之间的RPC通信之外,还包括如下几个重要的模块:
(1)依托ZookeeperWatcher进行的分布式信息共享与任务协调的工作。
MasterAddressTracker:捕获Master服务节点的变化。HBase使用多Master来解决Master单点故障的问题,主Master服务故障时,它与ZooKeeper的心跳延迟超过阈值,ZooKeeeper路径下的数据被清理,备Master上的ActiveMaserManager服务会竞争该Master路径,成为主Master。MasterAddresTracker是RS内部监听Master节点变化的追踪器。
ClusterStatusTracker:HBase集群状态追踪器。该选项可以标识当前集群的状态,及它的启动时间。该设置选项有利于集群中的各个工作节点(RS)统一执行启动和退出操作。
CatalogTracker:跟踪-ROOT-、.META.表的Region的状态。在HBase支持的-ROOT-、.META.、以及User Region三层树级目录结构中,-ROOT-、.META.表用来定位Region的位置,追踪-ROOT-表和.META.表对应Region的变化,可以时刻保证整个层次目录树的完整性。
SplitLogWorker:基于Region的HLog文件切分器。在RS宕机之后,RS上的保存的HLog文件,需要按照Region进行切分。HMaster会把这些文件作为任务放置到Zookeeper的splitlog路径下,RS上SplitLogWorker会尝试获取任务,对获取到的HLog文件按照Region进行分组,处理的结果保存到相应Region的recovered.edits目录下。
(2)Region的管理。
Region是HBase数据存储和管理的基本单位。Client从.META.表的查找RowKey对应的Region的位置,每个Region只能被一个RS提供服务,RS可以同时服务多个Region,来自不同RS上的Region组合成表格的整体逻辑视图。
图(2) Region与RS逻辑关系图
RS内涉及到提供的有关Region维护的服务组件有:
1) MemStoreFlusher,控制RS的内存使用,有选择性地将Region的MemStore数据写入文件。该组件可以有效地控制RS的内存使用,flush文件的速度在一定程度上可以反应HBase写服务的繁忙状况。
2) CompactSplitThread,合并文件清理不需要的数据,控制Region的规模。在Store内的文件个数超过阈值时,触发Compact合并文件操作,一是清理被删除的数据,二是多余版本的清理。在Region内的Store文件大小超过阈值,会触发Region的Split操作,一个Region被切分成两个Region。这两个操作都是在CompactSplitThread的各自的线程池中被触发。
3) CompactionChecker,周期性检查RS上的Region是否需要进行Compaction操作,确认需要进行Compaction操作的Region,提交给CompactSplitThread执行请求。
RS的内存的使用分为MemStore和BlockCache。其中MemStore提供写操作的缓存,而BlockCache是提供的读请求缓存。它们详细的内容会在后续章节中介绍。
(3)WAL的管理。
HBase对于数据的更新和删除操作默认先Append到HLog文件,然后再更新到RS对应的Region上,因此,由HLog文件在RS的处理方式,被称为Write-Ahead-Log。多个Region的更新删除操作会被相继写入同一个文件,出于以下的原因,HLog文件会被截断,然后创建新HLog文件继续当前的Append操作。
1) Append操作失败,避免因底层文件系统的文件异常,阻塞数据的操作。
2) 降低存储空间的开销。当HLog上记录的数据完全从MemStore写入HDFS,此时如果多个HLog文件,有利于筛选冗余的HLog文件,提高存储空间的效率。
3) 提高分布式HLog文件切分操作(Distributed Log Split)的效率。多个HLog文件就对应同样数目的LogSplit子任务,从而可以借助多个RS的SplitLogWorker组件快速完成HLog文件的切分,尽快恢复Region的服务。
在RS内,LogRoller定期刷新出一个新的HLog文件。
(4)Metrics
Metrics对外提供了衡量HBase内部服务状况的参数。RegionServer内Metrics包含了内存使用、Region服务状况、Compaction、blockCache等一系列标识服务状况的参数。HBase Metrics继承Hadoop Metrics的实现,目前支持文件、Ganglia、以及数据流等多种输出方式,可以针对输出的Metrics信息灵活构建监控系统。
(5)HttpServer
RS内置了一个Jetty Web Server,用来对外提供RS的访问页面。访问页面目前支持实时Metrics信息查询、日志查询、线程的Dump、修改日志级别等操作。
2 RegionServer的启动过程分析
RegionServer服务由org.apache.hadoop.hbase.regionserver.HRegionServer类提供。该类实现了四个接口,分别是HRegionInterface,RegionServerServices,HBaseRPCErrorHandler和Runnable。其中,HRegionInterface定义了RS对外提供的RPC访问接口,通过RPCServer内置的Handler来处理请求;RegionServerServices定义了基于RS内部的服务信息接口,例如onlineRegions增、删、查接口,以及获取HLog、文件系统等接口;HBaseRPCErrorHandler定义了RPCServer异常状态检测处理接口;Runnable是Java库中的线程接口,实现该接口意味着RegionServer生命周期会运行在run()的函数体内。
RegionServer是一个独立的服务,有一个main函数在启动时被调用,main函数内通过HRegionServerCommandLine的反射机制在JVM内动态加载RegionServer实现类,并按照args解析参数情况,决定启动或者关闭RS服务。
public class HRegionServer implements HRegionInterface,
HBaseRPCErrorHandler,Runnable, RegionServerServices {
... //成员变量定义和成员函数实现
public static void main(String[] args) throws Exception {
...
Configuration conf = HBaseConfiguration.create();
@SuppressWarnings("unchecked")
Class<? extends HRegionServer> regionServerClass = (Class<? extends HRegionServer>) conf
.getClass(HConstants.REGION_SERVER_IMPL, HRegionServer.class);//获取RegionServer对应的类
new HRegionServerCommandLine(regionServerClass).doMain(args);//创建RegionServer实例并启动
}
...
}
初始化与执行过程包括:
(1)构造HRegionServer实例,初始化变量和对象。这涉及到以下重要变量初始化:
protected volatile boolean stopped = false;//关闭Server的标识,关闭过程中会置成ture
private boolean stopping = false;//关闭Region过程的标识,是进入stopped之前的状态
protected volatile boolean fsOk;//文件系统状态标识,false表示文件系统不可用
private final ConcurrentSkipListMap<byte[], Boolean> regionsInTransitionInRS =
new ConcurrentSkipListMap<byte[], Boolean>(Bytes.BYTES_COMPARATOR);//RS内处于迁移过程中的Region,其中true表示在open,false表示在close
protected final Map<String, HRegion> onlineRegions =
new ConcurrentHashMap<String, HRegion>();//RS内正在服务的Region
protected final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();//修改onlineRegions对象的读写锁
protected final int threadWakeFrequency;//工作线程服务周期间隔
private final int msgInterval;//向Master汇报心跳,收集Metrics间隔
private final long maxScannerResultSize;//Scanner执行next返回的数据量阈值,默认设置是Long.MAX_VALUE
private int webuiport = -1;//webServer的端口号
private final long startcode;//HRegiongServer初始化的时间,取自系统时间
private ServerName serverNameFromMasterPOV;//标识Server的名字
private final int rpcTimeout;//定义到HMaster之间的rpc超时时间
在RS上重要的对象列表,如表1所示。
表1RegionServer重要对象的解释
| 对象名 | 对应类名 | 功能描述 |
|---|---|---|
| hbaseMaster | HMasterRegionInterface | RS向HMaster汇报信息,提供的RPC客户端 |
| rpcServer | RpcServer | RS内的Rpc服务器 |
| leases | Leases | 维护客户访问的租约 |
| compactSplitThread | CompactSplitThread | RS内执行Compact和Split功能组件 |
| cacheFlusher | MemStoreFlusher | 负责将Region的MemStore写入文件 |
| compactionChecker | Chore | 定期检查Region的Compaction过程 |
| hlog | HLog | 接收Write-Ahead-Log |
| hlogRoller | LogRoller | 定期开启新的HLog文件 |
(2)监听服务组件的初始化与执行。
这个过程初始化以ZooKeeperWatcher为基础的服务,例如监听Master服务节点的MasterAddressManager,标识HBase集群状态的ClusterStatusTracker,以及元数据(-ROOT-, .META.)变化的监听器。启动这些服务可以保证整个集群信息协调一致。
(3)RS服务组件的初始化与执行。
这个过程是初始化compactSplitThread,cacheFlusher,compactionChecker,以及Leases。
(4)尝试连接HMaster,注册RS到HMaster。
(5)周期性收集Metrics和向Master发送心跳。
3 Store相关
Region是RS上的基本数据服务单位,用户表格由1个或者多个Region组成,根据Table的Schema定义,在Region内每个ColumnFamily的数据组成一个Store。每个Store内包括一个MemStore和若干个StoreFile(HFile)组成。如图(3)所示。本小节将介绍Store内的MemStore、StoreFile(HFile)的内部结构与实现。
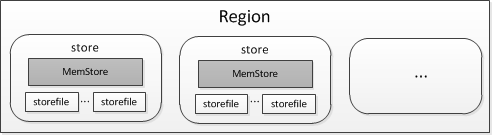
图(3) Region-Store结构图
3.1 MemStore原理与实现分析
MemStore是一个内存区域,用以缓存Store内最近一批数据的更新操作。对于Region指定的ColumnFamily下的更新操作(Put、Delete),首先根据是否写WriteAheadLog,决定是否append到HLog文件,然后更新到Store的MemStore中。显然,MemStore的容量不会一直增长下去,因此,在每次执行更新操作时,都会判断RS上所有的MemStore的内存容量是否超过阈值,如果超过阈值,通过一定的算法,选择Region上的MemStore上的数据Flush到文件系统。更详细的处理流程图如图(4)。
图(4) 更新操作的流程图
MemStore类内的重要的成员变量:
volatile KeyValueSkipListSet kvset;//内存中存放更新的KV的数据结构 volatile KeyValueSkipListSet snapshot;//Flush操作时的KV暂存区域 final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();//Flush操作与kvset之间的可重入读写锁 final AtomicLong size;//跟踪记录MemStore的占用的Heap内存大小 TimeRangeTracker timeRangeTracker;//跟踪记录kvset的最小和最大时间戳 TimeRangeTracker snapshotTimeRangeTracker;//跟踪记录snapshot的最小和最大时间戳 MemStoreLAB allocator;//实际内存分配器
注意 KeyValueSkipListSet是对于jdk提供的ConcurrentSkipListMap的封装,Map结构是<KeyValue,KeyValue>的形式。Concurrent表示线程安全。SkipList是一种可以代替平衡树的数据结构,默认是按照Key值升序的。对于ConcurrentSkipListMap的操作的时间复杂度平均在O(logn),设置KeyValue. KVComparator比较KeyValue中Key的顺序。
写入MemStore中的KV,被记录在kvset中。根据JVM内存的垃圾回收策略,在如下条件会触发Full GC。
内存满或者触发阈值。
内存碎片过多,造成新的分配找不到合适的内存空间。
RS上服务多个Region,如果不对KV的分配空间进行控制的话,由于访问的无序性以及KV长度的不同,每个Region上的KV会无规律地分散在内存上。Region执行了MemStore的Flush操作,再经过JVM GC之后就会出现零散的内存碎片现象,而进一步数据大量写入,就会触发Full-GC。图(5)显示这种假设场景的内存分配过程。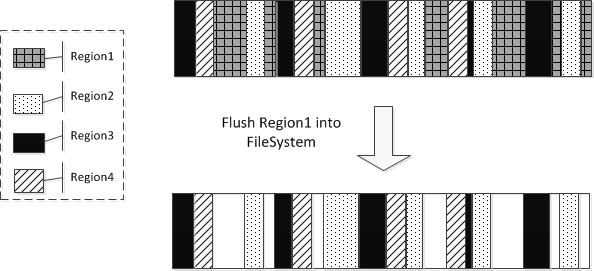
图(5) 无处理状态下MemStore内存分配图
为了解决因为内存碎片造成的Full-GC的现象,RegionServer引入了MSLAB(HBASE-3455)。MSLAB全称是MemStore-Local Allocation Buffers。它通过预先分配连续的内存块,把零散的内存申请合并,有效改善了过多内存碎片导致的Full GC问题。
MSLAB的工作原理如下:
在MemStore初始化时,创建MemStoreLAB对象allocator。
创建一个2M大小的Chunk数组,偏移量起始设置为0。Chunk的大小可以通过参数hbase.hregion.memstore.mslab.chunksize调整。
当MemStore有KeyValue加入时,maybeCloneWithAllocator(KeyValue)函数调用allocator为其查找KeyValue.getBuffer()大小的空间,若KeyValue的大小低于默认的256K,会尝试在当前Chunk下查找空间,如果空间不够,MemStoreLAB重新申请新的Chunk。选中Chunk之后,会修改offset=原偏移量+KeyValue.getBuffer().length。chunk内控制每个KeyValue大小由hbase.hregion.memstore.mslab.max.allocation配置。
空间检查通过的KeyValue,会拷贝到Chunk的数据块中。此时,原KeyValue由于不再被MemStore引用,会在接下来的JVM的Minor GC被清理。
注意 设置chunk的默认大小以及对于KeyValue大小控制的原因在于,MSLAB虽然会降低内存碎片造成的Full-GC的风险,但是它的使用会降低内存的利用率。如果超过一定大小的KeyValue,此时该KeyValue空间被回收之后,碎片现象不明显。因此,MSLAB只解决小KV的聚合。
MSLAB解决了因为碎片造成Full GC的问题,然而在MemStore被Flush到文件系统时,没有reference的chunk,需要GC来进行回收,因此,在更新操作频繁发生时,会造成较多的Young GC。
针对该问题,HBASE-8163提出了MemStoreChunkPool的解决方案,方案已经被HBase-0.95版本接收。它的实现思路:
创建chunk池来管理没有被引用的chunk,不再依靠JVM的GC回收。
当一个chunk没有引用时,会被放入chunk池。
chunk池设置阈值,如果超过了,则会放弃放入新的chunk到chunk池。
如果当需要新的chunk时,首先从chunk池中获取。
根据patch的测试显示,配置MemStoreChunkPool之后,YGC降低了40%,写性能有5%的提升。如果是0.95以下版本的用户,可以参考HBASE-8163给出patch。
思考 通过MemStore提供的MSLAB和MemStoreChunkPool给出的解决方案,可以看出在涉及到大规模内存的Java应用中,如何有效地管理内存空间,降低JVM GC对于系统性能造成的影响,成为了一个研究热点。整体上来说,一是设置与应用相适应的JVM启动参数,打印GC相关的信息,实时监控GC对于服务的影响;二是从应用程序设计层面,尽可能地友好地利用内存,来降低GC的影响。
在ChunkPool就是帮助JVM维护了chunk信息,并把那些已经不再MemStore中的数据的chunk重新投入使用。这样就可以避免大量的YGC。
3.2 MemStore参数控制原理与调优
对于任何一个HBase集群而言,都需要根据应用特点对其系统参数进行配置,以达到更好的使用效果。MemStore作为更新数据的缓存,它的大小及处理方式的调整,会极大地影响到写数据的性能、以及随之而来的Flush、Compaction等功能。这种影响的原因在于以下两个方面。
RS全局的MemStore的大小与Region规模以及Region写数据频度之间的关系。
过于频繁的Flush操作对于读数据的影响。
这其中涉及到的可调整的参数如下表。
表MemStore相关的配置参数
| 参数名称 | 参数含义 | 默认值 |
|---|---|---|
| hbase.regionserver.global.memstore.upperLimit | RS内所有MemStore的总和的上限/Heap Size的比例,超过该值,阻塞update,强制执行Flush操作。 | 0.4 |
| hbase.regionserver.global.memstore.lowerLimit | 执行Flush操作释放内存空间,需要达到的比例。 | 0.35 |
| hbase.hregion.memstore.flush.size | 每个MemStore占用空间的最大值,超过该值会执行Flush操作。 | 128MB |
| hbase.hregion.memstore.block.multiplier | HRegion的更新被阻塞的MemStore容量的倍数。 | 2 |
| hbase.hregion.preclose.flush.size | 关闭Region之前需要执行Flush操作的MemStore容量阈值。 | 5MB |
对于上述参数理解:
(1)RS控制内存使用量的稳定。
例如,假设我们的RS的内存设置为10GB,按照以上参数的默认值,RS用以MemStore的上限为4GB,超出之后,会阻塞整个RS的所有Reigon的请求,直到全局的MemStore总量回落到正常范围之内。
以上涉及到cacheFlusher在MemStore总量使用超过上限时,选择Region进行Flush的算法,由MemStoreFlusher.flushOneForGlobalPressure()算法实现。算法的处理流程如下。
关键的数据结构:
SortedMap<Long,HRegion> regionsBySize = server.getCopyOfOnlineRegionsSortedBySize();//从RS上获取在线的Region,以及它们在MemStore上使用量,并按照MemStore使用量作为Key,降序。 Set excludedRegions = new HashSet();//记录尝试执行Flush操作失败的Region … HRegion bestFlushableRegion = getBiggestMemstoreRegion( regionsBySize, excludedRegions, true);//选出storefile个数不超标、当前MemStore使用量最大的Region HRegion bestAnyRegion = getBiggestMemstoreRegion( regionsBySize, excludedRegions, false);//选出当前MemStore使用量最大的Region
步骤1:RS上在线的Region,按照当前MemStore的使用量进行排序,并存储在regionsBySize中。
步骤2:选出Region下的Store中的StoreFile的个数未达到hbase.hstore.blockingStoreFiles,并且MemStore使用量最大的Region,存储到bestFlushableRegion。
步骤3:选出Region下的MemStore使用量最大的Region,存储到bestAnyRegion对象。
步骤4:如果bestAnyRegion的memstore使用量超出了bestFlushableRegion的两倍,这从另外一个角度说明,虽然当前bestAnyRegion有超过blockingStoreFiles个数的文件,但是考虑到RS内存的压力,冒着被执行Compaction的风险,也选择这个Region作为regionToFlush,因为收益大。否则,直接选择bestFlushableRegion作为regionToFlush。
步骤5:对regionToFlush执行flush操作。如果操作失败,regionToFlush放入excludedRegions,避免该Region下次再次被选中,然后返回步骤2执行,否则程序退出。
(2)设置两个limit,尽可能减少因为控制内存造成数据更新流程的阻塞。
当RS的MemStore使用总量超过(Heap*hbase.regionserver.global.memstore.lowerLimit)的大小时,同样会向cacheFlusher提交一个Flush请求,并以(1)中Region选择算法,对其进行Flush操作。与(1)不同,这个过程中RS不会阻塞RS的写请求。
因此,在生产环境中,我们肯定不希望更新操作被block,一般会配置(upperLimit –lowerlimit)的值在[0.5,0.75]之间,如果是应用写负载较重,可以设置区间内较大的值。
3.3 StoreFile—HFile
该节请参考:HFile文件格式与HBase读写
3.4 Compaction对于服务的影响
该小节请参考:深入分析HBase Compaction机制
本系列文章属于Binos_ICT在Binospace个人技术博客原创,原文链接为http://www.binospace.com/index.php/hbase-in-depth-analysis-of-the-regionserver/,未经允许,不得转载。