Hadoop MapReduce基于新API的WordCount程序运行过程分析
Hadoop MapReduce基于新API的WordCount程序运行过程分析
一、 新的WordCount分析(源码详见hadoop-1.2.1版本中的WordCount.java)
1)Map过程
我们知道map方法需要处理的是一条一条的K-V对(这些K-V对是经由MapReduce计算框架对欲处理的大数据进行分片处理等一系列操作得到并传递给map方法的,这一分片处理过程是mapreduce框架的InputFormat自动完成的,具体细节令外再讲解),编写算法处理传递过来的K-V对才是map方法需要关注的工作。 “map方法的所属静态类”需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。
首先分析public void map(Object key, Text value, Context context)方法的参数具体类型,通过在map方法中添加两句把key值和value值输出到控制台的语句,可以发现map方法的参数value存储的是文本文件中的一行(以回车符为行结束标记),而参数key为“该行的首字母相对于文本文件的首地址的偏移量”。
然后算法使用StringTokenizer类将每一行拆分成为一个个的单词,并将<word,1>作为map方法的结果输出,其余的工作都交有MapReduce框架处理。
2)Reduce过程
Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。Map过程输出<key,values>中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,所以reduce方法只要遍历values并求和,即可得到某个单词的总次数。
3)执行MapReduce任务
在MapReduce中,由Job对象负责管理和运行一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。此处设置了使用TokenizerMapper完成Map过程中的处理和使用IntSumReducer完成Combine和Reduce过程中的处理。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。任务的输出和输入路径则由命令行参数指定,并由FileInputFormat和FileOutputFormat分别设定。完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务。
二、WordCount处理过程-实例讲解
本节将对WordCount进行更详细的讲解。详细执行步骤如下:
1)将大文件拆分成多个数据分片splits,这里由于测试用的文件较小,所以每个文件为一个split,然后,RecordReader类则是实际的用来加载数据分片并把数据分片split转换为适合map方法读取的一个个键值对<K,V>,并一个个的传送给map方法。这一步由MapReduce框架的RecordReader类自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。

2)RecordReader类将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如下图所示。

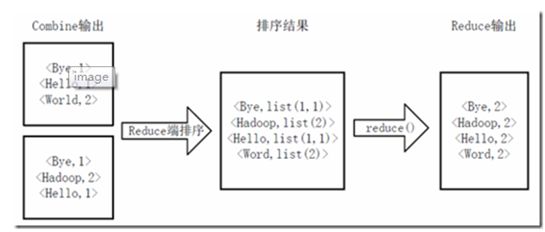
3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如下图所示。
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如下图所示。
WordCount.java 源码:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
三、MapReduce-新旧API改变
Hadoop自从版本0.20.0起,MapReduce Release 0.20.0的API包括了一个全新的Mapreduce Java API,有时候也称为上下文对象。新的API类型上不兼容以前的API,所以,以前的应用程序需要重写才能使新的API发挥其作用。
新的API和旧的API之间有下面几个明显的区别:
1. 新API倾向于使用抽象类,而不是接口,因为这更容易扩展。例如,你可以添加一个方法(用默认的实现)到一个抽象类而不需修改类之前的实现方法。在新的API中,Mapper和Reducer是抽象类。
2. 新API是在org.apache.hadoop.mapreduce包(和子包)中的。之前版本的API则是放在org.apache.hadoop.mapred中的。
3. 新API广泛使用context object(上下文对象),并允许用户代码与MapReduce系统进行通信。例如,MapContext基本上充当着JobConf的OutputCollector和Reporter的角色。
4. 新API同时支持"推"和"拉"式的迭代。在这两个新老API中,键/值记录对被推mapper中,但除此之外,新的API允许把记录从map()方法中拉出,这也适用于reducer。"拉"式的一个有用的例子是分批处理记录,而不是一个接一个。
5. 新API统一了配置。旧的API有一个特殊的JobConf对象用于作业配置,这是一个对于Hadoop通常的Configuration对象的扩展。在新的API中,这种区别没有了,所以作业配置通过Configuration来完成。作业控制的执行由Job类来负责,而不是JobClient,它在新的API中已经荡然无存。
6. 使用MapReduce新版客户端API提交MapReduce Job需要使用 org.apache.hadoop.mapreduce.Job 类。
JavaDoc给出新API中job的配置以下使用范例:
// Create a new Job
Job job = new Job(new Configuration());
job.setJarByClass(MyJob.class);
// Specify various job-specific parameters
job.setJobName("myjob");
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
//配置输入,输出参数
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true); //提交job到mapreduce框架并执行
从方法名可以看出,MapReduce Job是通过调用Job类的waitForCompletion方法提交到MapReduce框架运行的,而实际上这个方法又调用了Job类的submit方法。submit方法完成全部的提交工作。
submit方法创建一个JobSubmitter实例并通过该实例完成提交工作, 创建JobSubmitter实例需要准备两个参数:
一个是代表所用文件系统的FileSystem实例,另一个是封装了与MapReduce框架通信的具体协议的ClientProtocol实例。使用这两个实例,JobSubmitter在与集群通信时就不需要关心集群的具体细节,因而其代码可以写成具有一定的通用性。JobSubmitter具体的提交过程与编写客户端程序无关,这里不深入分析。
不过,这里有必要分析FileSystem实例和ClientProtocol实例的创建过程。FileSystem实例和ClientProtocol实例均取自Job的一个私有属性Cluster cluster,Cluster类接受一个封装了客户端程序提供的配置信息的Configuration对象后被实例化,在Cluster实例化的过程中,Cluster的FileSystem属性和ClientProtocal属性得以确定,其中FileSystem属性由ClientProtocal属性确定。因此,这里的关键问题是:ClientProtocal属性怎么确定?Cluster使用线程上下文类加载器寻找所有实现了ClientProtocolProvider这个抽象类的类,对于找到的类依次实例化并传递客户端程序提供的配置信息作为参数调用其 create方法,直到从返回值获得一个ClientProtocol实例的引用或者遍历结束。若获得引用,这个被赋值给ClientProtocal属性;否则输出出错信息并返回。
可见,客户端程序通过改变传入的配置信息能够改变使用的MapReduce目标。实际上,基于Yarn的MapReduce正是以这种方式被客户端程序访问的。