epoll 内核分析
1、epoll和select/poll的内核区别
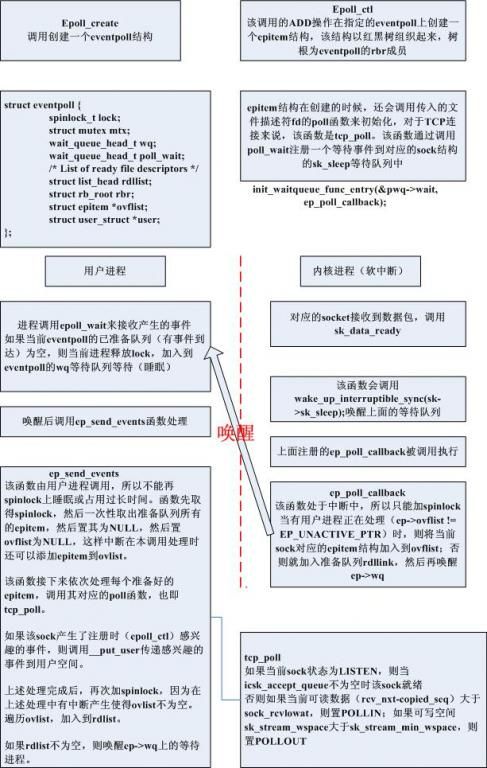
epoll的设计思路,是把select/poll单个的操作拆分为1个epoll_create+多个epoll_ctrl+一个epoll_wait。
epoll系统 调用:
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
epoll_wait是异步(一般是这样使用非阻塞方式)获取io事件的接口。避免了轮训耗费。
select/poll的缺点在于:
1)文件描述符列表以及消息内容,需要在内核空间和用户空间之间拷贝
2)每次调用时要重复地扫描文件描述符。
3)每次在调用开始时,要把当前进程放入各个文件描述符的等待队列。在调用结束后,又把进程从各个等待队列中删除。
在实际应用中,select/poll监视的文件描述符可能会非常多,如果每次只是返回一小部分,那么,这种情况下select/poll显得不够高效。
2、epoll文件描述符
epoll机制实现了自己特有的文件系统eventpoll filesystem
/* File callbacks that implement the eventpoll file behaviour */
static const struct file_operations eventpoll_fops = {
.release = ep_eventpoll_release,
.poll = ep_eventpoll_poll
};
epoll_create创建一个属于该文件系统的文件,然后返回其文件描述符。
struct event poll 保存了epoll文件节点的扩展信息,该结构保存于file结构体的private_data域中,每个epoll_create创建的epoll描述符都分配一个eventpoll 结构体。
定义如下:
/*
* This structure is stored inside the "private_data" member of the file
* structure and rapresent the main data sructure for the eventpoll
* interface.
*/
struct eventpoll {
/* Protect the this structure access,可用于中断上下文 */
spinlock_t lock;
/*
* This mutex is used to ensure that files are not removed
* while epoll is using them. This is held during the event
* collection loop, the file cleanup path, the epoll file exit
* code and the ctl operations.用户进程上下文中
*/
struct mutex mtx;
/* Wait queue used by sys_epoll_wait() */
wait_queue_head_t wq;
/* Wait queue used by file->poll() */
wait_queue_head_t poll_wait;
/* List of ready file descriptors */
struct list_head rdllist;
/* RB tree root used to store monitored fd structs */
struct rb_root rbr;
/*
* This is a single linked list that chains all the "struct epitem" that
* happened while transfering ready events to userspace w/out
* holding ->lock.
*/
struct epitem *ovflist;
/* The user that created the eventpoll descriptor */
struct user_struct *user;
};
2、epoll的监听项处理
epoll_ctl接口把监听项(包含套接字,属于socket filesystem)加入该epoll描述符。
每个添加的待监听对应于一个epitem结构体,该结构体已红黑树的结构组织,eventpoll结构中保存了树的根节点(rbr成员)。
把有监听事件到来的套接字的该结构以双向链表组织起来,链表头也保存在eventpoll中(rdllist成员)。
/*
* Each file descriptor added to the eventpoll interface will
* have an entry of this type linked to the "rbr" RB tree.
*/
struct epitem {
/* RB tree node used to link this structure to the eventpoll RB tree */
struct rb_node rbn;
/* List header used to link this structure to the eventpoll ready list */
struct list_head rdllink;
/*
* Works together "struct eventpoll"->ovflist in keeping the
* single linked chain of items.
*/
struct epitem *next;
/* The file descriptor information this item refers to */
struct epoll_filefd ffd;
/* Number of active wait queue attached to poll operations */
int nwait;
/* List containing poll wait queues */
struct list_head pwqlist;
/* The "container" of this item */
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
struct list_head fllink;
/* The structure that describe the interested events and the source fd */
struct epoll_event event;
};
epoll_create的调用很简单,就是创建一个epollevent的文件,并返回文件描述符。
(1)添加监听项
epoll_ctl用来添加,删除以及修改监听项。
/*
* The following function implements the controller interface for
* the eventpoll file that enables the insertion/removal/change of
* file descriptors inside the interest set.
*/
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
int error;
struct file *file, *tfile;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
DNPRINTK(3, (KERN_INFO "[%p] eventpoll: sys_epoll_ctl(%d, %d, %d, %p)/n",
current, epfd, op, fd, event));
error = -EFAULT;
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
goto error_return;
/* Get the "struct file *" for the eventpoll file */
error = -EBADF;
file = fget(epfd);
if (!file)
goto error_return;
/* Get the "struct file *" for the target file */
tfile = fget(fd);
if (!tfile)
goto error_fput;
/* The target file descriptor must support poll */
error = -EPERM;
if (!tfile->f_op || !tfile->f_op->poll)
goto error_tgt_fput;
/*
* We have to check that the file structure underneath the file descriptor
* the user passed to us _is_ an eventpoll file. And also we do not permit
* adding an epoll file descriptor inside itself.
*/
error = -EINVAL;
if (file == tfile || !is_file_epoll(file))
goto error_tgt_fput;
/*
* At this point it is safe to assume that the "private_data" contains
* our own data structure.
*/
ep = file->private_data;
mutex_lock(&ep->mtx);
/*
* Try to lookup the file inside our RB tree, Since we grabbed "mtx"
* above, we can be sure to be able to use the item looked up by
* ep_find() till we release the mutex.
*/
epi = ep_find(ep, tfile, fd);
error = -EINVAL;
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tfile, fd);
} else
error = -EEXIST;
break;
case EPOLL_CTL_DEL:
if (epi)
error = ep_remove(ep, epi);
else
error = -ENOENT;
break;
case EPOLL_CTL_MOD:
if (epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_modify(ep, epi, &epds);
} else
error = -ENOENT;
break;
}
mutex_unlock(&ep->mtx);
error_tgt_fput:
fput(tfile);
error_fput:
fput(file);
error_return:
DNPRINTK(3, (KERN_INFO "[%p] eventpoll: sys_epoll_ctl(%d, %d, %d, %p) = %d/n",
current, epfd, op, fd, event, error));
return error;
}
添加监听事件到epoll文件描述符(对应的结构为 eventpoll )
/*
* Must be called with "mtx" held.
*/
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
{
int error, revents, pwake = 0;
unsigned long flags;
struct epitem *epi;
struct ep_pqueue epq;
/* 不允许超过最大监听个数*/
if (unlikely(atomic_read(&ep->user->epoll_watches) >=
max_user_watches))
return -ENOSPC;
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
/* Item initialization follow here ... */
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
/* Initialize the poll table using the queue callback */
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
/*
* Attach the item to the poll hooks and get current event bits.
* We can safely use the file* here because its usage count has
* been increased by the caller of this function. Note that after
* this operation completes, the poll callback can start hitting
* the new item.
*/
revents = tfile->f_op->poll(tfile, &epq.pt);
/*
* We have to check if something went wrong during the poll wait queue
* install process. Namely an allocation for a wait queue failed due
* high memory pressure.
*/
error = -ENOMEM;
if (epi->nwait < 0)
goto error_unregister;
/* Add the current item to the list of active epoll hook for this file */
spin_lock(&tfile->f_ep_lock);
list_add_tail(&epi->fllink, &tfile->f_ep_links);
spin_unlock(&tfile->f_ep_lock);
/*
* Add the current item to the RB tree. All RB tree operations are
* protected by "mtx", and ep_insert() is called with "mtx" held.
*/
ep_rbtree_insert(ep, epi);
/* We have to drop the new item inside our item list to keep track of it */
spin_lock_irqsave(&ep->lock, flags);
/* If the file is already "ready" we drop it inside the ready list */
if ((revents & event->events) && !ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
/* Notify waiting tasks that events are available */
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irqrestore(&ep->lock, flags);
atomic_inc(&ep->user->epoll_watches);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&psw, &ep->poll_wait);
DNPRINTK(3, (KERN_INFO "[%p] eventpoll: ep_insert(%p, %p, %d)/n",
current, ep, tfile, fd));
return 0;
error_unregister:
ep_unregister_pollwait(ep, epi);
/*
* We need to do this because an event could have been arrived on some
* allocated wait queue. Note that we don't care about the ep->ovflist
* list, since that is used/cleaned only inside a section bound by "mtx".
* And ep_insert() is called with "mtx" held.
*/
spin_lock_irqsave(&ep->lock, flags);
if (ep_is_linked(&epi->rdllink))
list_del_init(&epi->rdllink);
spin_unlock_irqrestore(&ep->lock, flags);
kmem_cache_free(epi_cache, epi);
return error;
}
1)init_poll_funcptr函数注册poll table回调函数。
2)调用tfile的poll函数,并且poll函数的第2个参数为poll table(这是epoll机制中唯一对监听套接字调用poll时第2个参数不为NULL的时机)。
(2)注册等待函数到等待队列
ep_ptable_queue_proc函数的作用是注册等待函数,并添加到指定的等待队列,所以在第一次调用后,该信息已经存在了,无需在poll函数中再次调用了。
/*
* This is the callback that is used to add our wait queue to the
* target file wakeup lists.
*/
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
/* 为监听套接字注册一个等待回调函数,在唤醒时调用*/
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
那么该poll函数到底是怎样的呢,这就要看我们在传入到epoll_ctl前创建的套接字的类型(socket调用)。
对于创建的tcp套接字来说,可以按照创建流程找到其对应得函数是tcp_poll。
tcp_poll的功能:
1)如果poll table回调函数存在(ep_ptable_queue_proc),则调用它来等待。注意这只限第一次调用,在后面的poll中都无需此步
2)判断事件的到达。注册tcp_poll到等待队列(sock成员的sk_sleep),等待队列在对应的IO事件中被唤醒。
(3)等待队列唤醒后的处理函数
当等待队列被唤醒时会调用相应的等待回调函数,前面看到我们注册的是函数ep_poll_callback。
该函数可能在中断上下文中调用。
/*
* This is the callback that is passed to the wait queue wakeup
* machanism. It is called by the stored file descriptors when they
* have events to report.
*/
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
DNPRINTK(3, (KERN_INFO "[%p] eventpoll: poll_callback(%p) epi=%p ep=%p/n",
current, epi->ffd.file, epi, ep));
/* 对eventpoll的spinlock加锁,因为是在中断上下文中*/
spin_lock_irqsave(&ep->lock, flags);
/* 没有事件到来
* If the event mask does not contain any poll(2) event, we consider the
* descriptor to be disabled. This condition is likely the effect of the
* EPOLLONESHOT bit that disables the descriptor when an event is received,
* until the next EPOLL_CTL_MOD will be issued.
*/
if (!(epi->event.events & ~EP_PRIVATE_BITS))
goto out_unlock;
/*
* If we are trasfering events to userspace, we can hold no locks
* (because we're accessing user memory, and because of linux f_op->poll()
* semantics). All the events that happens during that period of time are
* chained in ep->ovflist and requeued later on.
*/
if (unlikely(ep->ovflist != EP_UNACTIVE_PTR)) {
if (epi->next == EP_UNACTIVE_PTR) {
epi->next = ep->ovflist;
ep->ovflist = epi;
}
goto out_unlock;
}
/* If this file is already in the ready list we exit soon */
if (ep_is_linked(&epi->rdllink))
goto is_linked;
/* 加入ready queue*/
list_add_tail(&epi->rdllink, &ep->rdllist);
is_linked:
/*
* Wake up ( if active ) both the eventpoll wait list and the ->poll()
* wait list.
*/
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
out_unlock:
spin_unlock_irqrestore(&ep->lock, flags);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&psw, &ep->poll_wait);
return 1;
}
分成2个队列:
1)在epoll_wait调用中使用的eventpoll的等待队列,用于判断是否有监听套接字可用
2)对应于每个套接字的等待队列sk_sleep,用于判断每个监听套接字上事件,该队列唤醒后调用ep_poll_callback,在该函数中又调用wakeup函数来唤醒前一种队列,来通知epoll_wait调用进程。
(4)回调处理函数处理事件
ep_poll函数是在epoll_wait中调用的等待函数,其等待被ep_poll_callback唤醒,然后调用ep_send_events来把到达事件copy到用户空间,然后epoll_wait才返回。
代码如下:
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res, eavail;
unsigned long flags;
long jtimeout;
wait_queue_t wait;
/*
* Calculate the timeout by checking for the "infinite" value ( -1 )
* and the overflow condition. The passed timeout is in milliseconds,
* that why (t * HZ) / 1000.
*/
jtimeout = (timeout < 0 || timeout >= EP_MAX_MSTIMEO) ?
MAX_SCHEDULE_TIMEOUT : (timeout * HZ + 999) / 1000;
retry:
spin_lock_irqsave(&ep->lock, flags);
res = 0;
if (list_empty(&ep->rdllist)) {
/*
* We don't have any available event to return to the caller.
* We need to sleep here, and we will be wake up by
* ep_poll_callback() when events will become available.
*/
init_waitqueue_entry(&wait, current);
wait.flags |= WQ_FLAG_EXCLUSIVE;
__add_wait_queue(&ep->wq, &wait);
for (;;) {
/*
* We don't want to sleep if the ep_poll_callback() sends us
* a wakeup in between. That's why we set the task state
* to TASK_INTERRUPTIBLE before doing the checks.
*/
set_current_state(TASK_INTERRUPTIBLE);
if (!list_empty(&ep->rdllist) || !jtimeout)
break;
if (signal_pending(current)) {
res = -EINTR;
break;
}
spin_unlock_irqrestore(&ep->lock, flags);
jtimeout = schedule_timeout(jtimeout);
spin_lock_irqsave(&ep->lock, flags);
}
__remove_wait_queue(&ep->wq, &wait);
set_current_state(TASK_RUNNING);
}
/* Is it worth to try to dig for events ? */
eavail = !list_empty(&ep->rdllist);
spin_unlock_irqrestore(&ep->lock, flags);
/*
* Try to transfer events to user space. In case we get 0 events and
* there's still timeout left over, we go trying again in search of
* more luck.
*/
if (!res && eavail &&
!(res = ep_send_events(ep, events, maxevents)) && jtimeout)
goto retry;
return res;
}
(5)拷贝事件的同步操作
ep_poll_callback函数调用ep_send_events函数需要同步操作,因为他们都要操作ready queue。
eventpoll中包含2种类型的锁:
1)mtx,一个mutex类型,是对该描述符操作的基本同步锁,可以睡眠;
2)lock,一个spinlock类型,不允许睡眠,所以用在ep_poll_callback中,注意mtx不能用于此。
注意由于ep_poll_callback函数中会涉及到对eventpoll的ovflist和rdllist成员的访问,所以在任意其它地方要访问时都要先加mtx锁,在加lock锁。
ep_send_events 代码:
static int ep_send_events(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents)
{
int eventcnt, error = -EFAULT, pwake = 0;
unsigned int revents;
unsigned long flags;
struct epitem *epi, *nepi;
struct list_head txlist;
INIT_LIST_HEAD(&txlist);
/*
* We need to lock this because we could be hit by
* eventpoll_release_file() and epoll_ctl(EPOLL_CTL_DEL).
*/
mutex_lock(&ep->mtx);
/*
* Steal the ready list, and re-init the original one to the
* empty list. Also, set ep->ovflist to NULL so that events
* happening while looping w/out locks, are not lost. We cannot
* have the poll callback to queue directly on ep->rdllist,
* because we are doing it in the loop below, in a lockless way.
*/
spin_lock_irqsave(&ep->lock, flags);
list_splice(&ep->rdllist, &txlist);
INIT_LIST_HEAD(&ep->rdllist);
ep->ovflist = NULL;
spin_unlock_irqrestore(&ep->lock, flags);
/*
* We can loop without lock because this is a task private list.
* We just splice'd out the ep->rdllist in ep_collect_ready_items().
* Items cannot vanish during the loop because we are holding "mtx".
*/
for (eventcnt = 0; !list_empty(&txlist) && eventcnt < maxevents;) {
epi = list_first_entry(&txlist, struct epitem, rdllink);
list_del_init(&epi->rdllink);
/*
* Get the ready file event set. We can safely use the file
* because we are holding the "mtx" and this will guarantee
* that both the file and the item will not vanish.
*/
revents = epi->ffd.file->f_op->poll(epi->ffd.file, NULL);
revents &= epi->event.events;
/*
* Is the event mask intersect the caller-requested one,
* deliver the event to userspace. Again, we are holding
* "mtx", so no operations coming from userspace can change
* the item.
*/
if (revents) {
if (__put_user(revents,
&events[eventcnt].events) ||
__put_user(epi->event.data,
&events[eventcnt].data))
goto errxit;
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS;
eventcnt++;
}
/*
* At this point, noone can insert into ep->rdllist besides
* us. The epoll_ctl() callers are locked out by us holding
* "mtx" and the poll callback will queue them in ep->ovflist.
*/
if (!(epi->event.events & EPOLLET) &&
(revents & epi->event.events))
list_add_tail(&epi->rdllink, &ep->rdllist);
}
error = 0;
errxit:
spin_lock_irqsave(&ep->lock, flags);
/*
* During the time we spent in the loop above, some other events
* might have been queued by the poll callback. We re-insert them
* inside the main ready-list here.
*/
for (nepi = ep->ovflist; (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
/*
* If the above loop quit with errors, the epoll item might still
* be linked to "txlist", and the list_splice() done below will
* take care of those cases.
*/
if (!ep_is_linked(&epi->rdllink))
list_add_tail(&epi->rdllink, &ep->rdllist);
}
/*
* We need to set back ep->ovflist to EP_UNACTIVE_PTR, so that after
* releasing the lock, events will be queued in the normal way inside
* ep->rdllist.
*/
ep->ovflist = EP_UNACTIVE_PTR;
/*
* In case of error in the event-send loop, or in case the number of
* ready events exceeds the userspace limit, we need to splice the
* "txlist" back inside ep->rdllist.
*/
list_splice(&txlist, &ep->rdllist);
if (!list_empty(&ep->rdllist)) {
/*
* Wake up (if active) both the eventpoll wait list and the ->poll()
* wait list (delayed after we release the lock).
*/
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irqrestore(&ep->lock, flags);
mutex_unlock(&ep->mtx);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&psw, &ep->poll_wait);
return eventcnt == 0 ? error: eventcnt;
}
ep_send_events操作步骤如下:
1)加mtx锁
2)读取ready queue:
但是中断会写这个成员,所以要加spinlock;但是接下来的工作会sleep,所以在整个loop都加spinlock显然会阻塞ep_poll_callback函数,从而阻塞中断,这是个很不好的行为,也不可取。于是epoll中在eventpoll中设置了另一个成员ovflist。在读取ready queue前,我们设置该成员为NULL,然后就可以释放spinlock了。为什么这样可行呢,因为对应的,在ep_poll_callback中,获取spinlock后,对于到达的事件并不总是放入ready queue,而是先判断ovflist是否为EP_UNACTIVE_PTR。
代码如下:
if (unlikely(ep->ovflist != EP_UNACTIVE_PTR)) {
/* 进入此处说明用用户进程在调用ep_poll_callback,所以把事件加入ovflist中,而不是ready queue中*/
if (epi->next == EP_UNACTIVE_PTR) {/* 如果此处条件不成立,说明该epi已经在ovflist中,所以直接返回*/
epi->next = ep->ovflist;
ep->ovflist = epi;
}
goto out_unlock;
}
所以在此期间,到达的事件放入了ovflist中。当loop结束后,函数接着遍历该list,添加到ready queue中,最后设置ovflist为EP_UNACTIVE_PTR,
这样下次中断中的事件可以放入ready queue了。最后判断是否有其他epoll_wait调用被阻塞,则唤醒。
3、epoll内核处理优点
1)用户传入的信息保存在内核中了,无需每次传入
2)事件监听机制不在是 整个监听队列,而是每个监听套接字在有事件到达时通过等待回调函数异步通知epoll,然后再返回给用户。
epoll在内核中的同步机制图如下: