Kylin(Extreme OLAP Engine for Big Data)
概述
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。最初于2014年10月1日开源,并于同年11月加入Aapche孵化器项目,并在一年后的2015年11月顺利毕业成为Apache顶级项目,是eBay全球贡献至Apache软件基金会(ASF)的第一个项目,也是全部由在中国的华人团队整体贡献至Apache的第一个项目。
在eBay,已经上线两个生产环境平台,有着诸多的应用,包括用户行为分析、点击分析、商户分析、交易分析等应用,最新的Streaming分析项目也已经上线。目前在eBay平台上最大的单个cube包含了超过1000亿的数据,90%查询响应时间小于1.5秒,95%的查询响应时间小于5秒。同时Apache Kylin在eBay外部也有很多的用户,包括京东、美团、百度地图、网易、唯品会、Expedia、Expotional等很多国内外公司也已经在实际环境中使用起来,把Apache Kylin作为他们大数据分析的基础之一。
在构建生态系统方面:一个应用很难单独的存在与一个企业中,不管是商业产品还是开源项目。从一开始,Kylin就定下了只关注核心功能,尽可能与整个产业链中的其它产品,项目及公司进行合作的方向。比如在前端展现方面和Tableau(Tableau helps people see and understand data)进行充分合作,在存储方面依靠HBase等。Apache Kylin的生态圈图从第一版到现在没有太多的变化,只是增加了更多的朋友,例如Apache Zeppelin等,随着新版架构的改进,整个项目将与Spark,Kafka, Excel/PowerBI, Docker等形成更好的互补和整合,积极融入整个大数据生态圈并打造自己的生态系统。
在eBay,已经上线两个生产环境平台,有着诸多的应用,包括用户行为分析、点击分析、商户分析、交易分析等应用,最新的Streaming分析项目也已经上线。目前在eBay平台上最大的单个cube包含了超过1000亿的数据,90%查询响应时间小于1.5秒,95%的查询响应时间小于5秒。同时Apache Kylin在eBay外部也有很多的用户,包括京东、美团、百度地图、网易、唯品会、Expedia、Expotional等很多国内外公司也已经在实际环境中使用起来,把Apache Kylin作为他们大数据分析的基础之一。
1.1 Kylin是什么
(1) 可扩展超快的OLAP分析引擎
Kylin设计于减少在Hadoop百亿级别数据行下的查询延迟。
(2) 基于Hadoop的ANSI SQL(美国国家标准化组织(ANSI))
Kylin为Hadoop提供标准SQL支持大部分查询功能。
(3) 交互式查询能力
用户可以通过Kylin与Hadoop数据进行低延迟交互,在同一数据集下比HIVE的查询效率高。
(4) MOLAP Cube(多维立方体)
MOLAP即基于多维数组的存储模型,也是最原始的OLAP,但需要对数据进行预处理才能形成多维结构。在Kylin中用户可以定义数据模型,并且对超过数百亿行的数据集进行预构建。关于数据立方体,维度与OLAP相关概念可参考:http://my.oschina.net/yjwxh/blog/629122
(5) 与BI工具无缝集成
Kylin提供了与BI工具例如Tableau的集成。与微软Excel的集成也将会支持。
(6) 其他一些亮点
a) 任务的管理与监控
b) 压缩与编码的支持
c) 增量更新
d) 与hbase协调处理来降低查询延迟
e) 基于HyperLogLog的Distinct Count近似算法
f) 提供简单的WEB界面来管理,构建,监控和查询cubes
g) 项目及立方体级别的访问控制安全
h) 支持LDAP集成
1.2 Kylin生态

(1) Kylin 核心:Kylin OLAP引擎的基础框架包含:元数据引擎、查询引擎、任务引擎以及存储引擎。它也包含了一个提供客户端请求的REST服务端。
(2) 扩展:基于插件机制的功能与特色的扩展。
(3) 集成:生命周期管理支持任务计划、ETL、监控和告警系统的集成。
(4) 用户界面:允在Kylin核心之上扩展的第三方用户界面。
(5) 驱动:JDBC/ODBC支持不同的工具和产品例如Tableau。
二 Kylin安装部署
2.1 安装需求
Hadoop2.14+, Hive:0.13+, HBase0.98+, JDK1.7+。
通常来说Kylin安装在Hadoop客户端机器上。可以作为样例使用,或者为那些想要集成kylin服务的web站点服务。场景描述如下
对于一般用例来说,上图中的应用指的是Kylin web端,包含了一个web界面用于cube的创建,查询以及其他管理操作。Kylin web也启动一个查询引擎用于查询cube, 一个构建引擎用于构建cubes,,这两个引擎与hadoop组件交互,例如hive和hbase。
Kylin启动: kylin.sh start
访问kylin web客户端 ADMIN/KYLIN 
三 kylin使用指南
3.1 使用样例cube快速开始
执行kylin提供的sample.sh脚本,在hive、hbase生成相应的数据表 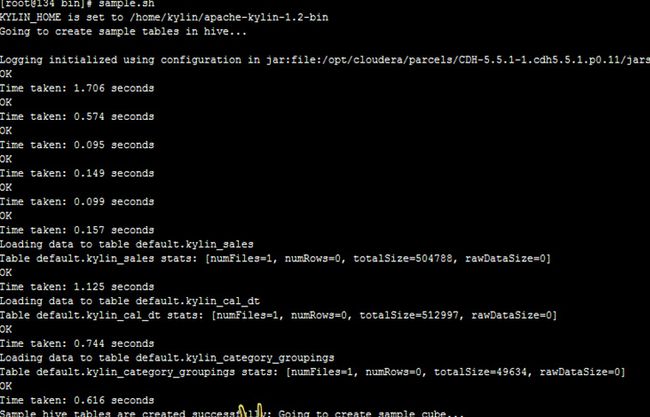
通过hive shell客户端测试数据库表是否生成:

检测是否在hbase生成相关元数据信息表:
表已经生成,重启kylin,清除缓存。重新登录kylin web端,并选择learn_kylin工程。
登录执行cube Actions=>Build
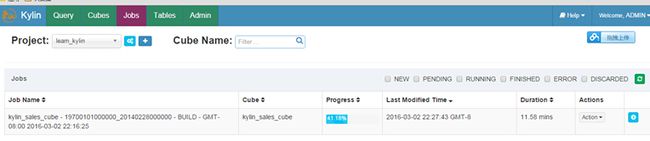
当cube build完成100%后,在Query下执行查询操作,查询语句:
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt
查询所有时间:2.25秒
使用hive直接查询所用时间:54s
使用spark sql查询所用时间:首次17s, 之后10-11s左右。6个节点 8g/节点内存
通过比较发现,kylin的查询效率还是很高的。
四 在Zeppelin中集成Kylin
4.1 配置Zeppelin Interpreter
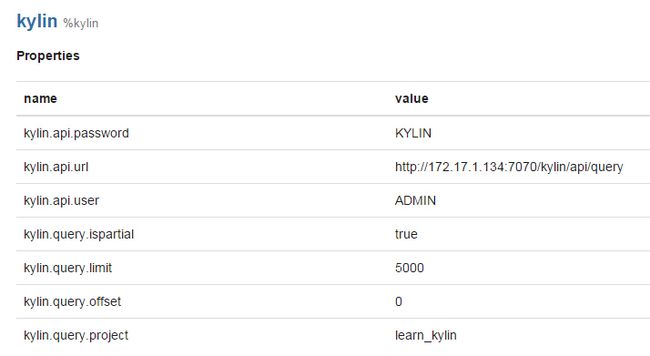
4.2 创建新的notebook测试kylin