在 Yarn 上 安装 Spark 0.9.0
今天在自己的Yarn cluster 上搭建了Spark 0.9.0,这里粗要地记录一下主要步骤。 详细的步骤主要参照了以下两篇blog,在此对两位作者表示感谢!
-Apache Spark学习:将Spark部署到Hadoop 2.2.0上: http://dongxicheng.org/framework-on-yarn/build-spark-on-hadoop-2-yarn/
-spark0.9分布式安装:http://blog.csdn.net/myboyliu2007/article/details/18990277
1、下载Spark 0.9.0 binary: http://mirror.bit.edu.cn/apache/incubator/spark/spark-0.9.0-incubating/spark-0.9.0-incubating-bin-hadoop2.tgz
下载后可以直接使用,省去了编译等过程。另外,该版本可以直接运行在Yarn上
2、下载 Scala 2.10.3://www.scala-lang.org/files/archive/scala-2.10.3.tgz
下载后需要在所有node上面解压Scala,然后将SCALA_HOME加入PATH
export SCALA_HOME=/opt/scala-2.10.3
export PATH=$PATH:$SCALA_HOME/bin
3、在Spark master 上安装配置Spark(参考spark0.9分布式安装)
4、在其它Spark worker上面安装配置Spark:
把Spark master 上安装配置好的Spark文件夹copy到每一个Spark worker上,然后配置必要的环境变量
5、从Master节点上启动Spark cluster:
$ ./sbin/start-all.sh
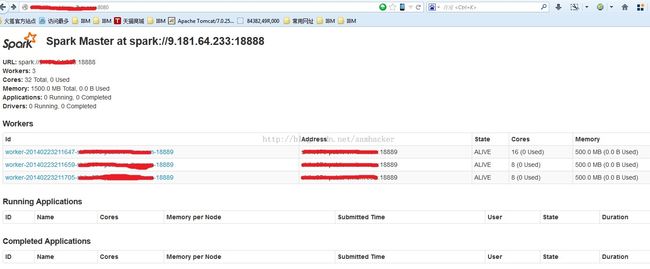
6、通过网页查看Spark cluster状态(http默认端口为8080):
7、测试一(本地模式)
命令: ./bin/run-example org.apache.spark.examples.SparkPi local
运行结果(部分截图):

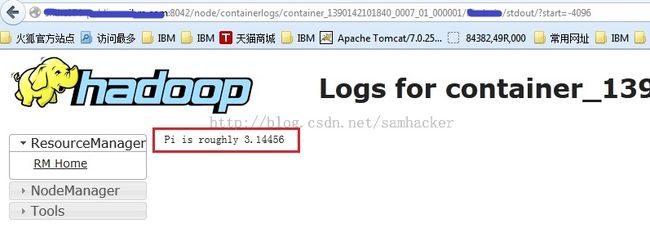
8、测试二(运行在Yarn上)
执行脚本:
#! /bin/bash
export YARN_CONF_DIR=/opt/hadoop-2.2.0/etc/hadoop
export SPARK_JAR=./assembly/target/scala-2.10/spark-assembly_2.10-0.9.0-incubating-hadoop2.2.0.jar \
bin/spark-class org.apache.spark.deploy.yarn.Client \
--jar examples/target/scala-2.10/spark-examples_2.10-assembly-0.9.0-incubating.jar \
--class org.apache.spark.examples.SparkPi \
--args yarn-standalone \
--num-workers 3 \
--master-memory 385m \
--worker-memory 385m \
--worker-cores 1
运行结果(从Yarn的web GUI上面可以看到job的output):