Java注解(3)-源码级框架
转载请注明本文出自远古大钟的博客(http://blog.csdn.net/duo2005duo),谢谢支持!
介绍
前面文章(Java注解(2)-运行时框架 )介绍的运行时框架是在虚拟机运行程序时使用反射技术搭建的框架;而源码级框架是在javac编译源码时,生成框架代码或文件。因为源码级别框架发生过程是在编译期间,所以并不会过多影响到运行效率。因此,搭建框架时候应该优先考虑使用源码级别框架。
注解处理器
注解处理器能够在编译源码期间扫描java代码中的注解,并且根据相关注解动态生成相关的文件。之后在程序运行时就可以使用这些动态生成的代码。值得注意的是,注解处理器运行在跟最终程序不同的虚拟机,也就是说,编译器为注解处理器开启了另外一台虚拟机来运行注解处理器。
步骤
要为工程添加一个注解处理器,需要以下几步
实现AbstractProcessor
package com.example;
public class ProcessorA extends AbstractProcessor {
...
}生成注解处理器jar
对于eclipse,
jar的目录结构如下
MyProcessor.jar
- com
- example
- ProcessorA.class
- META-INF
- services
- javax.annotation.processing.ProcessorMETA-INF中的文件需要自己手动创建,其中文件javax.annotation.processing.Processor里写明需要运行的处理器的类名,如
com.example.ProcessorA
com.example.ProcessorB
com.example.ProcessorC
com.example.ProcessorAndSoOn选中需要生成jar的工程,右击–>Export–>JarFile,如下图
对于Android studo
1.注解器模块配置如下
apply plugin: 'java'
sourceCompatibility = JavaVersion.VERSION_1_7
targetCompatibility = JavaVersion.VERSION_1_7
dependencies {
compile 'com.google.auto.service:auto-service:1.0-rc2'
}2.Android studio会自动生成为javax.annotation.processing.Processor,只需为注解器添加@AutoService注解,这样就可以自动生成META-INF内的文件,如下
@AutoService(Processor.class)
public class ProcessorA extends AbstractProcessor{
...
}指定注解器jar
这步主要是让编译器在编译时知道某些jar包是注解器jar,下面分命令行,eclipse和AndroidStudio三种情况分别介绍
- 命令行的方式
javac -processorpath 注解处理器.jar 目标程序.java- eclipse的配置
第一步
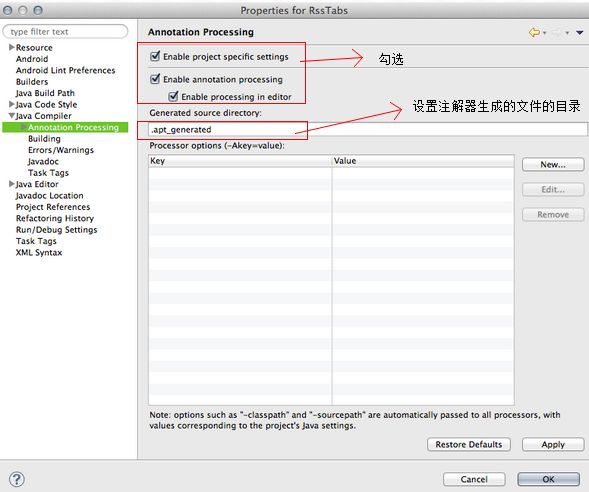
第二步

- Android studio配置
工程的build.gradle:
dependencies {
// 其他classpath
classpath 'com.neenbedankt.gradle.plugins:android-apt:1.8' //添加apt插件
}模块的build.gradle:
applying plugin: 'com.android.application'
apply plugin: 'com.neenbedankt.android-apt' //使用apt插件
dependencies {
apt '注解处理器.jar' //注解处理器
compile '关于处理器生成文件的调用包.jar' //API包
}
注解处理器接口
注解处理一般均需要重写以下四个方法
public class ProcessorA extends AbstractProcessor {
//这个方法主要是获取工具类
public synchronized void init(ProcessingEnvironment env){ }
//这个方法里面写处理的过程,输入参数annotations是getSupportedAnnotationTypes()的子集,即是工程代码中所有注解集合与getSupportedAnnotationTypes()的交集,RoundEnvironment env代表这一轮扫描后的结果,返回true则表示消费完此次扫描,此轮扫描注解结束
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment env) { }
//返回需要处理的注解的类的getCanonicalName()集合
public Set<String> getSupportedAnnotationTypes() { }
//返回SourceVersion.latestSupported()即可
public SourceVersion getSupportedSourceVersion() { }
}PS:java7之后,getSupported***()方法可以用一下注解代替
@SupportedSourceVersion(SourceVersion.latestSupported())
@SupportedAnnotationTypes({
AnnotationA.class.getCanonicalName(),AnnotationB.class.getCanonicalName(),
})
public class ProcessorA extends AbstractProcessor {
...
}打印日志
注解处理器的打印日志全部应该交由Messager处理,并且需要在打印错误时利用异常抛出来终止处理器
Messager messager=processingEnv.getMessager()
//打印非error级别log
messager.printMessage(Kind.NOTE,message);
//打印error时抛出异常来中断注解处理器
messager.printMessage(Kind.ERROR,error);
throw new RuntimeException(error);扫描处理流程
注解处理器对工程代码的扫描是多次的,可以注意到AbstractProcessor的process()方法的输入参数有一个是RoundEnvironment,这个代表一次扫描的结果。
影响注解处理器执行顺序与逻辑的地方有三处
1.javax.annotation.processing.Processor中的书写顺序决定注册处理器的执行顺序
假设该文件中定义如下:
package.ProcessorB
package.ProcessorA那么编译器每一轮扫描会先执行处理器ProcessorB,再执行处理器ProcessorA
2.AbstractProcessor中processor()方法的返回值决定是否要终结当前轮的处理
按照1中注册的顺序,假如ProcessorB中的process()方法返回true,则表示消费完这轮的注解扫描,将不再执行ProcessorA,只有当返回false时,才会接下来执行ProcessorB
3.没有输出文件跟输入文件时扫描结束
假设按照1中的注册顺序,ProcessorB中的process()方法返回true,并且ProcessorB在第一轮扫描会生成按文件GenerateB.java,则将在第三轮扫描后结束注解处理,过程如下
| 过程 | 输入文件 | 输出文件 |
|---|---|---|
| 第一轮 | 原工程 | GenerateB.java |
| 第二轮 | GenerateB.java | 无 |
| 第三轮 | 无 | 无 |
第三轮时编译器发现没有输出文件也没有输入文件,处理结束
PS:每个注解处理器在整个过程中都保持同一个实例
分包机制
注解处理器会生成一些代码文件,我们会写一些API调用这些代码。所以,源码级框架除了写注解处理器外,还要写一个API包。另外,由于源码级别的注解并不需要模块划分时候应该将注解处理器跟API分成两个模块来写,有利于缩小编译后体积。(以下简称其所在的包分别是处理器包 跟 API包 )
处理器包使用周期与API包不同:
- 处理器包:注解处理器只需要在目标工程编译时候执行,运行时不需要
- API包:API包因为会被目标工程运行时调用,所以在目标工程编译时和运行时都是需要的
由于这些不同,处理器包跟API包在工程中有不同的引用形式,如下
dependencies {
apt '处理器包'//注解处理器包,只存在编译时
compile 'API包' //API包,编译时跟编译后都存在
}语言模型包的使用
Mirror
注解处理器因为操作的是源码,所以需要用到JAVA语言模型包,javax.lang.model及其子包都是Java的语言模型包。这个包是采用了Mirror设计,Java是一种可以自描述的语言,其反射机制就是一种自描述,传统的反射机制将自描述与其他操作合并在一起,Mirror机制将自描述跟其他操作隔离,自描述部分是Meta level,其他部分是Base level
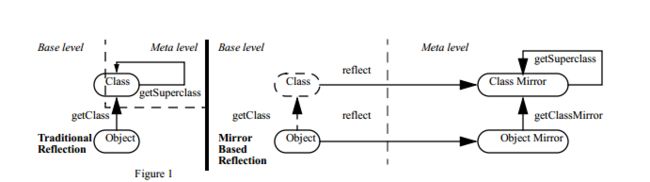
转化
Element代表语言元素,比如包,类,方法等,但是Element并没有包含自身的信息,自身信息要通过Mirror来获取,每个Element都指向一个TypeMirror,这个TypeMirror里有自身的信息。通过下面获方法取Element中的Mirror
TypeMirror mirror=element.asType() TypeMirror类型是DeclaredType或者TypeVariable时候可以转化成Element
Types types=processingEnvironment.getTypeUtils()
Element element=types.asElement(typeMirror)获取类型
获取Element或者TypeMirror的类型都是通过getKind()获取类型,但是返回值虽然不同,但是都是枚举。
ElementKind element.getKind()
TypeKind typeMirror.getKind()针对具体类型,要避免用instanceof,因为即使同一个类getKind()也有不同的结果。比如TypeElemnt的getKind()返回结果可以是枚举,类,注解,接口四种。
源码中移动
比如一个类里面有方法,成员变量等,这个类相对于方法跟成员变量就是外层元素,而成员变量和方法相对于类就是内层元素。
Element是代表源码的类,源码中移动到其他位置必须是用Element,比如移动到当前元素的外层元素TypeElement
public static TypeElement findEnclosingTypeElement( Element e ){
while( e != null && !(e instanceof TypeElement) ) {
e = e.getEnclosingElement();//通过getEnclosingElement()获取外层元素
}
return TypeElement.class.cast( e );
}也可以使用getEnclosedElements()获取当前Element内层的所有元素。
类继承树结构中移动
TypeMirror是用来反应类本身信息的类,在继承树移动必须用到TypeMirror,比如查找某个类的父类
Types typeUtils = processingEnv.getTypeUtils();
while (!typeElement.toString().equals(Object.class.getName())) {
TypeMirror typeMirror=element.getSuperclass();
element = (TypeElement)typeUtils.asElement(typeMirror);
}处理MirroredTypeException
编译器使用注解处理器来处理目标代码时候,目标源码还没有编译成字节码,所以任何指向目标源码字节码的代码都会发生MirroredTypeException。最常见的例子见下面
//已经编译的三方jar:
@Retention(RetentionPolicy.SOURCE)
@interface What{
Class<?> value()
}//源码:
@What(A.class)
public class A{}//注解处理器
public ProcessorA extends AbstractProcessor{
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
...
What what=typeElementA.getAnnotation(What.class);
Class<?> clazz=what.value(); //这里将有MirroredTypeException
...
}
}注解处理器之所有MirroredTypeException,是因为此时类A还没有被编译成字节码,所以A.class不存在,解决这个问题需要异常,利用异常我能获取类A的名字等信息,但是却得不到A.class,如下
public ProcessorA extends AbstractProcessor{
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
...
What what=typeElementA.getAnnotation(What.class);
try {
Class<?> clazz=what.value(); //这里将有MirroredTypeException
}catch(MirroredTypeException mte){
TypeMirror classTypeMirror = mte.getTypeMirror();
TypeElement classTypeElement = (TypeElement)Types.asElement(classTypeMirro);
//获取canonicalName
String canonicalName= classTypeElement.getQualifiedName().toString();
//获取simple name
String simpleName = classTypeElement.getSimpleName().toString();
}
...
}
}例子
//TODO