基于Theano的深度学习(Deep Learning)框架Keras学习随笔-06-激活函数
原地址:http://blog.csdn.net/niuwei22007/article/details/49208643可以查看更多文章
激活函数也是神经网络中一个很重的部分。每一层的网络输出都要经过激活函数。比较常用的有linear,sigmoid,tanh,softmax等。Keras内置提供了很全的激活函数,包括像LeakyReLU和PReLU这种比较新的激活函数。
一、激活函数的使用
常用的方法在Activation层中可以找到。看代码。
from keras.layers.core import Activation, Dense
model.add(Dense(64))
model.add(Activation('tanh'))
等价于:
model.add(Dense(64, activation='tanh')) #此处’tanh’是一个字符串
我们也可以将一个Theano function作为激活函数传递给activation,如下:
deftanh(x):
return theano.tensor.tanh(x)
model.add(Dense(64, activation=tanh)) #此处tanh是函数
model.add(Activation(tanh))
二、常用的激活函数
- softmax: 在多分类中常用的激活函数,是基于逻辑回归的。
- Softplus:softplus(x)=log(1+e^x),近似生物神经激活函数,最近出现的。
- Relu:近似生物神经激活函数,最近出现的。
- tanh:双曲正切激活函数,也是很常用的。
- sigmoid:S型曲线激活函数,最常用的。
- hard_sigmoid:基于S型激活函数。
- linear:线性激活函数,最简单的。
2001年,神经科学家Dayan、Abott从生物学角度,模拟出了脑神经元接受信号更精确的激活模型。模型图如下:

该模型的曲线变化特点有:单侧抑制,相对宽阔的兴奋边界,稀疏激活性(这个是重点,红框中的状态完全没有激活)。
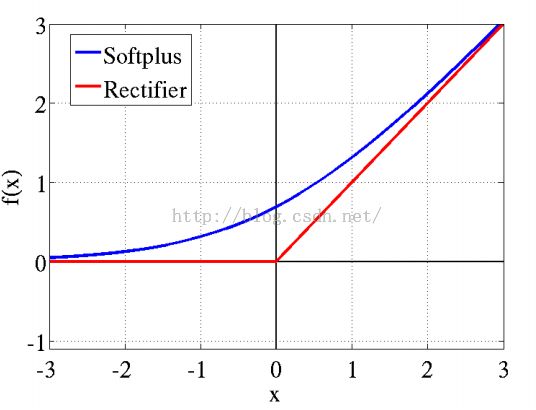
其中softplus和relu就是近似生物神经激活函数,图像如上图。Softplus具有新模型的前两点,却没有稀疏激活性。因而,校正函数max(0,x)成了近似符合该模型的最大赢家。
虽然稀疏性有很多优势。但是,过分的强制稀疏处理,会减少模型的有效容量。即特征屏蔽太多,导致模型无法学习到有效特征。对比大脑工作的95%稀疏性来看,现有的计算神经网络和生物神经网络还是有很大差距的。然而ReLu只有负值(如上图)才会被稀疏掉,即引入的稀疏性是可以训练调节的,是动态变化的。只要进行梯度训练,网络可以向误差减少的方向,自动调控稀疏比率,保证激活链上存在着合理数量的非零值。【本部分摘自ReLu(Rectified Linear Units)激活函数】
三、复杂的激活函数
更复杂的激活函数,可以在keras.layers.advanced_activations中找到。就是开始提到的PReLU和LeakyReLU。这两个函数都是在ReLU的基础之上进行改进的。从相关实验来看,这些函数具有更好的准确度,但是训练时间需要更长,因为计算更复杂。
参考资料
- 官方教程
- ReLu(Rectified Linear Units)激活函数