抓取分析网页批量下载评书(2)之分析下载地址
书接 《抓取分析网页批量下载评书(1)之搜索有声小说》,本篇主要介绍如何分析有声读物每集的链接地址,本文希望阅读者根据文章就能自己写出程序,所以写的比较详细,大家见谅,闲言少叙,咱们直奔主题。
一、咱们随便找一本评书进入其详细页,我们要获得评书的简介和剧集列表两部分内容,具体页面如下:
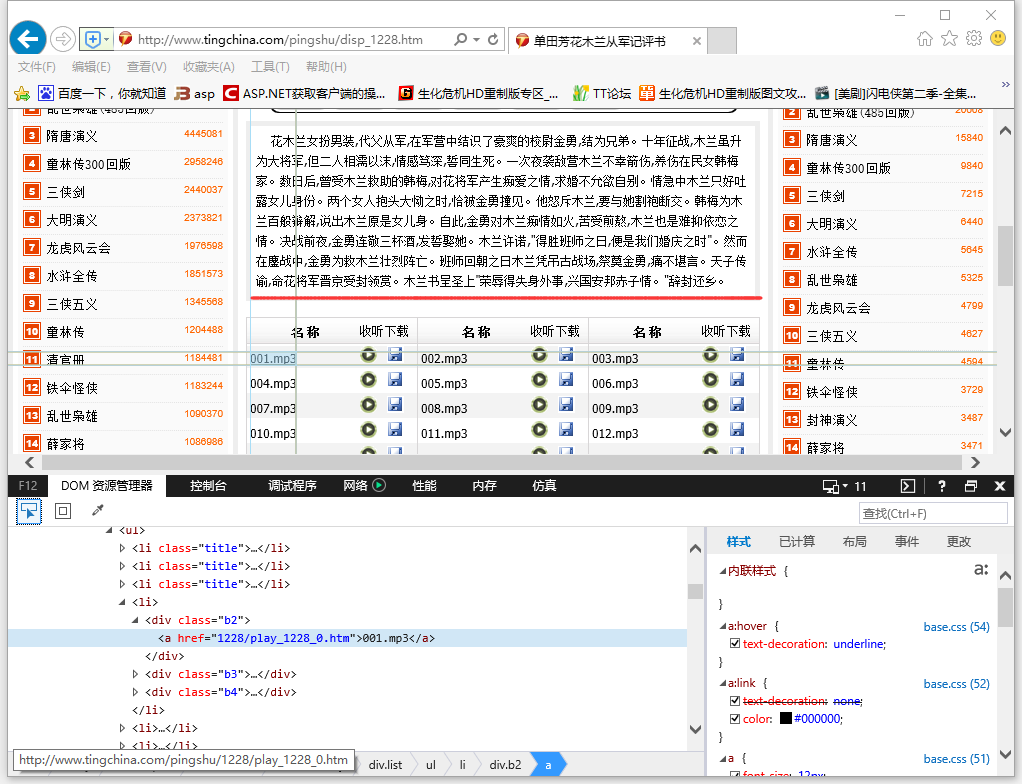
分析一下Html代码,简介是包含在<div class="book02 padding5 line5">简介内容</div>中,但需要注意,里包含了br、script等html标签,所以抓取内容后,需要清除一下html标签。
另外有一点需要注意,由于简介中可能含有div,所以正则表达式用贪婪模式或非贪婪模式都可能出现无法正确匹配,所以要保证唯一性,注意下面粗体的部分。
获取简介的正则表达式:
<div class=""book02 padding5 line5"">(?<Summary>[\s\S]*?)</div>\r\n<div class=""js[\d]*"">
PS:使用IE开发人员工具(F12)时发现一个问题,它会对代码进行整理,所以你看到内容有可能不是网页的真实内容,如下面两幅图

title,href的顺序不一样,Chrome中显示的是实际代码顺序。
具体的正则表达式:
<div class=""b2""><a href=""(?<SubPath>[\d\w]*)/play_[\d]*_(?<Number>[\d]*).htm""(\s*title=""[\s\S]*?.mp3"")*>(?<Title>[\s\S]*?).mp3</a></div>
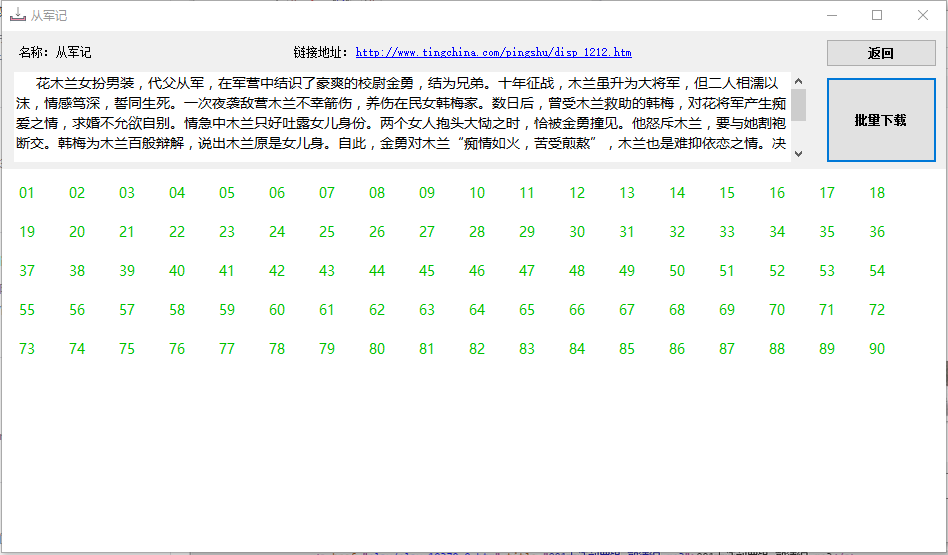
二、评书下载界面如下 :
三、主要的代码
Sound.cs
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
using
System; using System.Collections.Generic; using System.Linq; using System.Text; namespace psDownload { /// <summary> /// 有声读物类 /// </summary> public class Sound { /// <summary> /// 编号 /// </summary> public int ID { set; get; } /// <summary> /// 标题 /// </summary> public string Title { set; get; } /// <summary> /// 演播者 /// </summary> public string Performer { set; get; } /// <summary> /// 详细页网址 /// </summary> public string Url { set; get; } /// <summary> /// MP3的下载地址 /// </summary> public string DownUrl { set; get; } /// <summary> /// 状态 0:等待下载 1:下载成功 -1:下载失败 /// </summary> public int Status { set; get; } /// <summary> /// 错误详情 /// </summary> public string Error { set; get; } } } |
C# Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 |
//评书的名称、详细页网址、所属分类、文件输出路径 private string _title = "" , _url = "" , _category = "" , _outpath = "" ; //评书集数列表,Sound是一个自己写的类。 private List<Sound> _list = new List<Sound>(); public frmDetail( string Title, string Url, string OutPath) { InitializeComponent(); this ._title = Title; this ._url = Url; this ._outpath = OutPath; //获取评书所属的分类,后面需要用到,其实从上一个窗体传过来也行。 Match match = Regex.Match(Url, @ "http://www.tingchina.com/(?<Category>[\w]*)/disp_[\d]*.htm" , RegexOptions.IgnoreCase | RegexOptions.Multiline); if (match.Success) { this ._category = match.Groups[ "Category" ].Value; } } private void frmDetail_Load( object sender, EventArgs e) { this .Text = this ._title; this .lbl_Title.Text = this ._title; this .llbl_Url.Text = this ._url; //发送异步请求,获取评书的详细信息和剧集列表 HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create( this ._url); req.Timeout = 15 * 1000 ; req.Method = "GET" ; req.BeginGetResponse( new AsyncCallback(ResponseCallBack), req); } /// <summary> /// http异步请求的回调函数,分析网页,获得评书的简介、剧集列表等信息 /// </summary> /// <param name="result"></param> public void ResponseCallBack(IAsyncResult result) { string Html = "" ; HttpWebRequest req = (HttpWebRequest)result.AsyncState; try { using (HttpWebResponse response = (HttpWebResponse)req.EndGetResponse(result)) { Stream resStream = response.GetResponseStream(); StreamReader sr = new StreamReader(resStream, Encoding.GetEncoding( "GB2312" )); Html = sr.ReadToEnd(); } } catch (Exception ex) { if (IsDisposed || ! this .IsHandleCreated) return ; this .Invoke( new Action(() => { MessageBox.Show( "抓取网页出现异常,原因:" + ex.Message); })); return ; } //动态生成Label控件所需的字体 Font font = new Font( "微软雅黑" , 10F, System.Drawing.FontStyle.Regular, System.Drawing.GraphicsUnit.Point, (( byte )( 134 ))); //获取评书的简介 Match ms_Summary = Regex.Match(Html, @ "<div class=""book02 padding5 line5"">(?<Summary>[\s\S]*?)</div>\r\n<div class=""js[\d]*"">" , RegexOptions.IgnoreCase | RegexOptions.Multiline); if (ms_Summary.Success) { if (IsDisposed || ! this .IsHandleCreated) return ; this .Invoke( new Action(() => { this .txt_Summary.Text = ClearHtml(ms_Summary.Groups[ "Summary" ].Value); })); } //正则表达式分析网页,获取评书的剧集。 MatchCollection ms = Regex.Matches(Html, @ "<div class=""b2""><a href=""(?<SubPath>[\d\w]*)/play_[\d]*_(?<Number>[\d]*).htm""(\s*title=""[\s\S]*?.mp3"")*>(?<Title>[\s\S]*?).mp3</a></div>" , RegexOptions.IgnoreCase | RegexOptions.Multiline); if (ms.Count > 0 ) { //最大宽度 int MaxWidth = 0 ; this ._list.Clear(); foreach (Match m in ms) { Sound sound = new Sound(); sound.ID = int .Parse(m.Groups[ "Number" ].Value); sound.Title = m.Groups[ "Title" ].Value; sound.Url = "http://www.tingchina.com/" + this ._category + "/" + m.Groups[ "SubPath" ].Value + "/play_" + m.Groups[ "SubPath" ].Value + "_" + m.Groups[ "Number" ].Value + ".htm" ; this ._list.Add(sound); //获取字体的大小,找到最宽的那个条记录 Size size = TextRenderer.MeasureText(m.Groups[ "Title" ].Value, font); if (size.Width > MaxWidth) { MaxWidth = size.Width; } } if (IsDisposed || ! this .IsHandleCreated) return ; this .Invoke( new Action(() => { //循环动态生成查询结果. foreach (Sound sound in _list) { Panel pnl = new Panel(); Label lbl = new Label(); lbl.Name = "lbl_" + sound.ID.ToString(); lbl.Text = sound.Title; lbl.Tag = sound.Url; lbl.Cursor = System.Windows.Forms.Cursors.Hand; lbl.Margin = new System.Windows.Forms.Padding( 15 , 0 , 0 , 10 ); lbl.ForeColor = System.Drawing.Color.FromArgb((( int )((( byte )( 0 )))), (( int )((( byte )( 192 )))), (( int )((( byte )( 0 ))))); lbl.Font = font; lbl.Width = MaxWidth; lbl.Click += new EventHandler(lbl_Click); pnl.Controls.Add(lbl); PictureBox pic = new PictureBox(); pic.Name = "pic_" + sound.ID.ToString(); pic.Left = lbl.Width; pic.Top = 3 ; pic.SizeMode = PictureBoxSizeMode.Zoom; pic.Height = 16 ; pic.Width = 16 ; pnl.Name = "pnl_" + sound.ID.ToString(); pnl.Tag = sound; pnl.Controls.Add(pic); pnl.AutoSize = true ; this .fpnl_Content.Controls.Add(pnl); Application.DoEvents(); } this .btn_Download.Enabled = true ; this .btn_Download.ForeColor = Color.Black; this .btn_Download.Text = "批量下载" ; this .btn_Download.Focus(); })); } else { if (IsDisposed || ! this .IsHandleCreated) return ; this .Invoke( new Action(() => { MessageBox.Show( "分析网页失败,请检查。" ); })); } } /// <summary> /// 清除字符串中HTML控制字符 /// </summary> /// <param name="s">要清除的字符串</param> /// <returns></returns> public static string ClearHtml( string s) { if (s == null ) return null ; return HtmlDecode(Regex.Replace(s, @ "(<[^>]+>)|[\r\n]" , "" , RegexOptions.IgnoreCase | RegexOptions.Singleline)); } private static string HtmlDecodeMatchEvaluator(Match m) { switch (m.Value) { case "<" : return "<" ; case ">" : return ">" ; case "&" : return "&" ; case """ : return "\""; case " " : return "\u0020" ; default : return m.Value; } } /// <summary> /// HTML解码 /// </summary> /// <param name="s"></param> /// <returns></returns> private static string HtmlDecode( string s) { return Regex.Replace(s, "(<)|(>)|(&)|(")|( )" , new MatchEvaluator(HtmlDecodeMatchEvaluator), RegexOptions.Singleline | RegexOptions.IgnoreCase); } |
未完待续...
作者: 相信的勇气
出处: http://www.newrain.cn/article/detail/15
本文为博主原创文章,欢迎转载分享但请注明出处及链接,否则将其追究法律责!
勤奋的男人和爱笑的女人,运气一般都不会太差。