【CV】ICCV2015_Learning Temporal Embeddings for Complex Video Analysis
Learning Temporal Embeddings for Complex Video Analysis
Note here: it's a review note on novel work from Feifei-Li's group about video representations, published on ICCV2015.
Link: http://www.cv-foundation.org/openaccess/content_iccv_2015/html/Ramanathan_Learning_Temporal_Embeddings_ICCV_2015_paper.html
Motivation:
- Labeled video data is short for learning video representations, we need an unsupervised way.
- Context(temporal structure) is significant for video representations.
Proposed model:
- give one query frame, we can predict corresponding context representations(embeddings) of it through this model.
- Pipline:
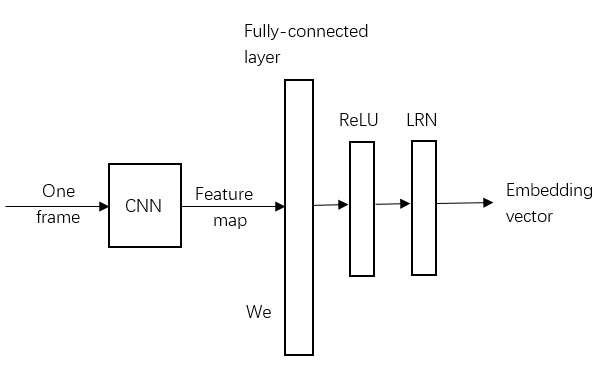
\(f_{vj}(s_{vj};w_{e})\): embedding function
(\(W_{e}\) is the only parameter here we need to train for)
- Training:
\(h_{vj}=\frac{1}{2T}\sum_{t=1}^T(f_{vj+t}+f_{vj-t})\): context vector
Unsupervised learning objective (SVM Loss):
\(J(W_{e})=\sum_{v\in V}\sum_{S_{vj\in V},S\neq S_{vj}}max(0,1-(f_{vj}-f_{\_})\cdot h_{vj})\)
(\(f_{vj}\) is the embedding of frame \(S_{vj}\))
(\(f_{\_}\) is a negative frame which is not highly relevant to \(S_{vj}\))
(\(h_{vj}\) is the context embedding of frame \(S_{vj}\))
We’ll go further into the choosing of negative frames and context range later.
Intuition:
This model momorizes the context of specific frame. It utilizes the spatial appearance of the frame to form an embedding vector, which infers its context information.
Spatial feature learned from CNN \(\xrightarrow{\;\;\;W_{e}\;\;projection\;\;\;}\) Temporal feature embeds context
(\(W_{e}\) memorizes the temporal pattern during training)
With the temporal structure, even though some frames are not appearance similar, they can also be near in the feature space as long as they share similar context. Like following:

There’re two takeaways in the training process:
- Multi-resolution sampling: it’s hard to decide a generic context range(T), for videos own different paces, some may be quick while some are slow. This paper proposed a multi-resolution sampling strategy, instead of only sampling the context with same frame gap, it sampling with various gap lengths. That’s a trade-off between semantic relatedness and visual variaty.
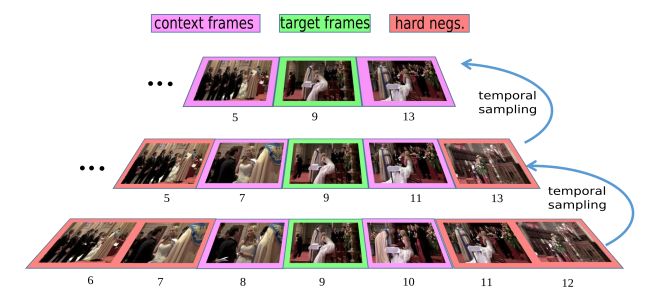
- Hard Negative: choosing of negative samples are important for a robust model. It’s natural to come up with sampling negative frames in other videos and context frames from the same video, but this may cause the model overfit for some video-specific, less sementic properties, like lighting, camera characteristics and background. As a result, this paper also samples negative frames that are out of context range from the same video to avoid this problem.