【优化】bigpipe技术
一、什么是bigpipe
Bigpipe是Facebook工程师提出了一种新的页面加载技术。
BigPipe是一个重新设计的基础动态网页服务体系。大体思路是,分解网页成叫做Pagelets的小块,然后通过Web服务器和浏览器建立管道并管理他们在不同阶段的运行。这是类似于大多数现代微处理器的流水线执行过程:多重指令管线通过不同的处理器执行单元,以达到性能的最佳。虽然BigPipe是对现有的服务网络基础过程的重新设计,但它却不需要改变现有的网络浏览器或服务器,它完全使用PHP和JavaScript来实现。
二、Bigpipe思想及原理
要利用该Web服务器和浏览器之间的并行性,BigPipe首先分解网页成多个可调用的Pagelets。正如流水线微处理器划分一个指令的生命周期为(如“取指令”,“指令解码”,“执行”,“写回寄存器”等)多个阶段,BigPipe的页面生成过程分为以下几个阶段:
1. 请求解析:Web服务器解析和完整性检查的HTTP请求。
2. 数据获取:Web服务器从存储层获取数据。
3. 标记生成:Web服务器生成的响应的HTML标记。
4. 网络传输:响应从Web服务器传送到浏览器。
5. CSS的下载:浏览器下载网页的CSS的要求。
6. DOM树结构和CSS样式:浏览器构造的DOM文档树,然后应用它的CSS规则。
7. JavaScript中下载:浏览器下载网页中JavaScript引用的资源。
8. JavaScript执行:浏览器的网页执行JavaScript代码。
前三个阶段执行,由Web服务器,最后四个阶段是由浏览器执行。每个Pagelet必须经过所有这些阶段顺序,但BigPipe在不同的阶段使几个Pagelets同时执行。
(Facebook主页的Pagelets,每个矩形对应一个Pagelet。)
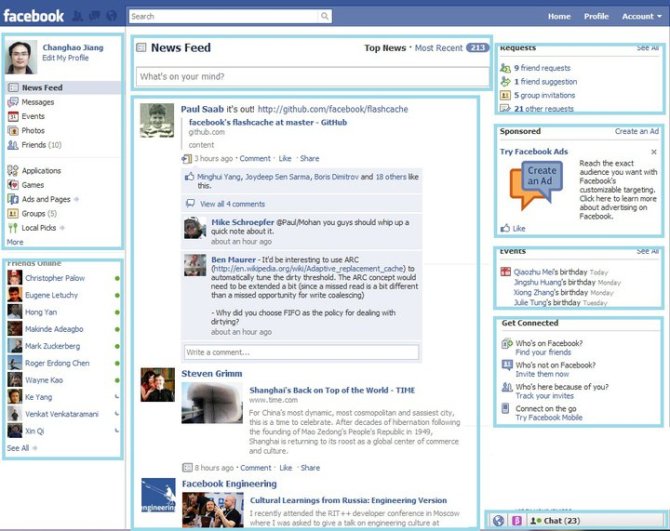
上面的图片使用Facebook主页为例子来说明如何将网页是分解成Pagelets。该主页包括几个Pagelets:“作者Pagelet”,“导航Pagelet”,“新闻动态Pagelet”,“请求框Pagelet”,“广告pagelet”,“朋友推荐”和“联系”等他们是相互独立的。当“导航Pagelet”显示给用户,“新闻动态Pagelet”仍然可以在服务器上正在生成。
在BigPipe,一个用户请求的生命周期是这样的:在浏览器发送一个HTTP请求到Web服务器。在收到的HTTP请求,并在上面进行一些全面的检查,网站服务器立即发回一个未关闭的HTML文件,其中包括一个HTML 标签和标签的开始标签。标签包括BigPipe的JavaScript库来解析Pagelet以后收到的答复。在标签,有一个模板,它指定了页面的逻辑结构和Pagelets占位符。例如:

渲染后的第一个反应到客户端,Web服务器继续一个接一个生成Pagelets只要一个Pagelet生成,他将立即刷新到客户端在一个JSON编码的对象,包括所有的CSS,JavaScript的pagelet,它的HTML内容,以及一些元数据所需的资源。例如:

在客户端在收到Pagelet通过“onPageletArrive”发出的指令,BigPipe的JavaScript库将首先下载它的CSS资源;在CSS资源被下载完成后,BigPipe将在Pagelet的标记HTML显示它的innerHTML。多个Pagelets的CSS可在同一时间下载,它们可以根据其各自CSS的下载完成情况来确认显示顺序。在BigPipe中,JavaScript资源的优先级低于CSS和页面内容。因此,BigPipe不会在所有Pagelets显示出来之前下载任何Pagelet中的JavaScript。然后,所有Pagelets的JavaScript异步下载。最后Pagelet的JavaScript初始化代码根据其各自的下载完成情况来确定执行顺序。
这种高度并行系统的最终结果是,多个Pageletsr的不同执行阶段同时进行。例如,浏览器可以正在下载三个Pagelets CSS的资源,同时已经显示另一Pagelet内容,与此同时,服务器也在生成新的Pagelet。从用户的角度来看,页面是逐步呈现的。最开始的网页内容会更快的显示,这大大减少了用户的对页面延时的感知。如果您要自己亲眼看到区别,你可以尝试以下连结: 传统模式和BigPipe。第一个链接是传统模式单一模式显示页面。第二个链接是BigPipe管道模式的页面。如果您的浏览器版本比较老,网速也很慢,浏览器缓存不佳,哪么两页之间的加截时间差别将更加明显。
三、实现细节
具体实现如下:当用户访问该页面 时,在第一个flush 的Response 内容中,返回大部分的HTML 代码,包括完整的<heaad>标签,和一个未封闭的<body>,其中<head>标签中有需要导入的文件的路 径,如一些公共的css 文件和BigPipe.js 文件,<body>标签有页面的主要布局,第二块flush 的内容为一段js脚本,处理BigPipe 对象的生成,以及js 和css 文件的路径和字符串的映射
var bigPipe = new bigPipe(); bigPipe.setResourceMap({ aaaaa:{ “name”: “js/list1.js”, “type”: “js”, “src”: “js/list1.js” } );
setResourceMap(json)为 BigPipe 中的函数,功能是设置文件的映射。”aaaaa”应该是在服务器随即生成的五位字符串,name表示文件名称,type 为文件的类型,可以是”js”或”css”,”src”为文件的路径。在下面的页面中,就可以使用”aaaaa”来替代”js/list1.js”了,减 少了复杂性。接下来flush 的是每一个pagelet 的内容了,例如:
<script type=”text/javascript” > bigPipe.onPageletArrive({ id:”list1″, content:”this is list 1 <\/br><img src =\”img13.jpg\” \/>”, css:["eeeee"], js:["aaaaa"], “resource_map”:{ aaaaa:{ “name”: “js/list1.js”, “type”: “js”, “src”: “js/list1.js” } , “eeeee”: { “name”: “css/list1.css”, “type”: “css” “src”: “css/list1.css” } } }); </script>
onPageletArrive(json_arrive) 也是BigPipe 的函数,功能是动态添加页面的内容和加载pagelet 所需的文件,函数的参数为json 格式的数据。其参数含义是:“id”用来寻找pagelet 标签;“ content ”是html 页面内容,在找到对应的pagelet 的标签之后,将content 内动态添加到html 页面中;“css”为该Pagelet 所需的css 文件,这里的css 文件可能在之前导入过了;“js”为该pagelet 所需的js 文件,同样,有可能在之前的pagelet已经导入过了。在函数实现过程中,因为js 文件是最后加载的,可以把这些js 的路径存入到一个数组当中(去掉重复的),在最后一起加载。resource_map”为该pagelet 所单独需要加载的js 和css 文件,同样也是json 格式的,结构与前面的setResource()中的参数一样。最后flush 的是
</body> </html>
即为最后的标签。
四、结论
经过上面的讨论,我们可以发现,使用BigPipe 技术优化页面可以有四个好处:
1. 减少页面的加载时间
2. 使页面分步输出,改善用户体验
3. 使页面结构化,提高可读性,更加便于维护
4. 每个pagelet 都是相互独立的,如果有一个pagelet 的内容不能加载,并不会影响其他的pagelet 的内容显示。