大型网站系统学习笔记
大型网站及其架构演进过程
(一)网站初建
作为一个交易网站,需要具备的最基本三个功能:(1) 用户:用户注册、用户管理、信息维护……(2) 商品:商品展示、商品管理……(3) 交易:创建交易、交易管理……如果基于JAVA用单机技术,即一台服务器来构建应用,示意图大概会如下所示
各个功能模块之间通过JVM内部方法调用来进行交互,而应用和服务器则通过JDBC进行访问
(二)单机负载告警,数据库与应用分离
网站对外服务后,访问量会不断增大,对服务器的负载持续升高,首先我们考虑从结构上进行优化:把数据库与应用从一台机器分到两台
与之前的差别,我们只需把应用的配置中数据库的访问地址从一个地址迁移到另一个地址进行,对开发、部署、测试影响不大。
调整能够缓解当前系统的压力,但随着访问量继续增大,我们的系统还需继续演进
(三)应用服务器负载告警,让应用服务器走向集群
应用服务器压力增大,我们把应用从单机变为集群的方式来进行优化
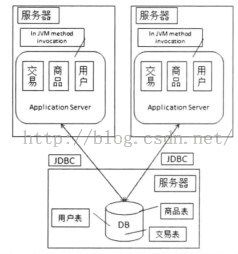
如上图所示,应用服务器从一台变为两台,而它们之间没有直接交互,都是依赖与数据库对外提供服务,但我们有两个问题亟待解决:
(1)用户对两个应用服务器访问的选择问题:
- 通过DNS解决:是在DNS服务器中为同一个主机名配置多个IP地址,在应答DNS查询时,DNS服务器对每个查询将以DNS文件中主机记录的IP地址按顺序返回不同的解析结果,将客户端的访问引导到不同的机器上去,使得不同的客户端访问不同的服务器。但它的缺点很明显:
②
不支持高可靠性,DNS负载均衡技术没有考虑容错。如果后台的某台Web服务器出现故障,DNS服务器仍然会把DNS 请求分配到这台故障服务器上,导致不能响应客户端。
- 通过负载均衡硬件设备来解决
- 通过nginx等WebSever实现负载均衡如:
-
upstream myServer {
server 127.0.0.1:9090 down;
server 127.0.0.1:8080 weight=2;
server 127.0.0.1:6060;
server 127.0.0.1:7070 backup;
}proxy_pass http://myServer;
(2) 解决应用服务器变为集群后的Session问题:Session通过游览器与服务器会话产生,它往往是保存在单机上的。
而对于上图,如果用户第一次访问网站,请求落到了左边的服务器,那么Session就创建在左边的服务器上,如果不做处理,就不能保存用户请求每次都落在存有其session会话信息的同一服务器上。针对此问题,我们来看看几种解决方案:
1. Session Sticky(滞粘会话)
当Web服务器变成多台时,保存同一个会话请求在同一服务器上处理,要做到这一点,需要负载均衡器能够根据每次请求的会话标识来进行请求转发
如使用nginx的ip_hash,此时nginx必须为最前端服务器,否则nginx得不到正确的ip,也不能根据ip做hash;同时nginx后端也不能有其它方式的负载均衡,否则请求又会被再次分流,客户端的请求就很难定位到同一Session应用服务器上了
upstream backend {server 127.0.0.1:8080 ;server 127.0.0.1:9090 ;ip_hash;}
针对nginx此点,我们可以使用
pstream_hash这个第三方模块,
假如前端是squid,他会将ip加入x_forwarded_for这个http_header里,用upstream_hash可以用这个头做因子,将请求定向到指定的后端。再通过
hash $http_x_forwarded_for;
这样就改成了利用x_forwarded_for这个头作因子,在nginx新版本中可支持读取cookie值,所以也可以改成:
hash $cookie_jsessionid;
使用Session Sticky有如下几个问题:
① 如果有一台服务器宕机或者重启,那么这台机器上的会话数据会丢失。
②负载均衡器变为一个有状态的节点,要将会话保存到具体Web服务器的映射,内存消耗会更大,容灾方面会更麻烦
2. Session Replication
如果把Session Styicky 比喻成我们将碗筷(会话数据)放在特定饭店(服务器),然后每次吃饭都去那家饭店,那Session Replication可以比喻成在每个饭店里都存放一套餐具,这样就可以自己根据每家饭店的拥挤情况自由选择饭店了。
而我们要做的就是在每次任一服务器产生会话数据时,将数据复制到其他服务器中。但这样会引发一些问题:
① 同步Session数据造成了网络带宽的额外开销,只要Session数据有变化,就需要将数据同步到所有其他机器中,机器数越多,同步带来的带宽开销就越大
② 如果整个集群的Session数很多的话(很多人同时访问网站)每台机器用于保存Session数据的内容占用会很严重
3. Session数据集中存储
将Session数据集中存储起来,然后不同web服务器从同一地方获取Session,而存储session的具体方式,可以使用数据库、NOSQL技术或其他分布式存储系统。它的问题有:
① 读写Session数据引发网络操作,这相对于本机数据读取来说,就存在时延和不稳定性。
② 如果集中存储Session的机器或者集群出现问题,就会影响我们的应用
4. cookie based
将Session信息存放到Cookie中,这样不会依赖与外部系统,也没有写入Session数据的网络时延和不稳定性。但Cookie的长度有限制,这样也会限制了Session的长度,同时可能存在被盗取的安全性问题
(四)数据读压力大,采用读写分离
主库负责读写,从库只提供读服务。
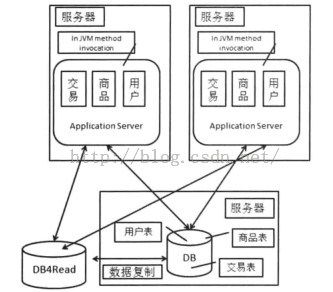
读写分离主要带来的是数据复制问题,
对于数据复制的实现,不同数据库都有相应的内置实现,如mysql的Master-Slave配置,我们主要考虑的是时延问题,如果用户修改了信息,但用户即时查看时,获取到的是从库中尚未更新的数据,就会让用户觉得自己没有修改成功。
(五)读写分离后再遇瓶颈,数据库垂直拆分
专库专用,数据垂直拆分,把数据库与应用从一台机器分到两台,如下图所示
![]()
但垂直拆分可能存在如下问题:
①需配置多个数据源
②分布式事务性能降低
③多表连接查询等操作变得困难
(六)垂直拆分后再遇瓶颈,单表数据水平拆分
![]()
专库专用,数据垂直拆分,把数据库与应用从一台机器分到两台,如下图所示
但垂直拆分可能存在如下问题:
①需配置多个数据源
②分布式事务性能降低
③多表连接查询等操作变得困难
(六)垂直拆分后再遇瓶颈,单表数据水平拆分
但水平拆分可能存在问题:
①sql查询路由问题
②主键不能重复的保证机制
③分页排序等获取问题
①sql查询路由问题
②主键不能重复的保证机制
③分页排序等获取问题