Druid at Pulsar
作者:Xiaoming Zhang
A glance of Pulsar and druid
Pulsar is anopen source project of eBay and it includes two parts, pulsar pipeline andpulsar reporting. Pulsar pipeline is a streaming framework which willdistribute more than 8 billion events every day and pulsar reporting is in responseof storing, querying and visualizing these data. Druid is part of pulsarreporting.
This paper willhave an introduction and a little deep dive of druid and show you the role itis playing at pulsar reporting.
Druid components introduction
Druid is an open source project which is ananalytics data store designed for business intelligence (Online analyticalprocessing) queries on event data.
Druid Skills (From official website):
1. Sub-Second Queries.
Support multidimensional filtering, aggression and is ableto target the very data to do query.
2. Real time Ingestion
Support streaming data ingestion and offers insightson events immediately after they occur
3. Scalable
Able to deal with trillions of events for total,millions events for each second
4. Highly Available
SaaS (Software as a service), need to be up all the timeand Scale up and down will not lose data
5. Designed for Analytics
Supports a lot of filters, aggregators and query types, is ableto plugging in new functionality.
Supports approximate algorithms for cardinality estimation,and histogram and quantile calculations.
Glance at Druid Structure of Pulsarreporting:

Receiveabout 10 Billion events per day and the peak traffic is about 200k/s.
Eachmachine at our cluster is with 128GB memory and for each historical nodes, diskis more than 6 TB.
Druid ata glance:
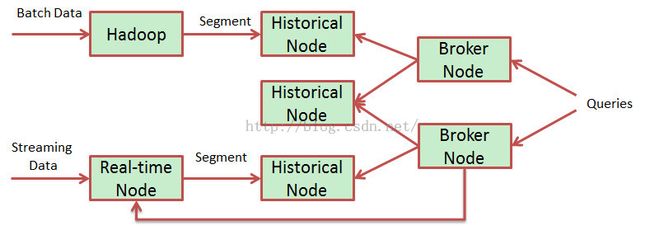
Briefintroduction to all nodes:
Real-time
Real-timenode index the coming data and these indexed data are able to queryimmediately. Real-time nodes will build up data to segments and after a periodof time the segment will handover to historical node.
Anexample of real-time segment: 2015-11-18T06:00:00.000Z_2015-11-18T07:00:00.000Z,which will be stored at the folder of the scheme you defined. All segments arestored like the above format.
Here isthe segment information at My SQL:
Id |dataSource | created_date | start | end | partitioned | version | used |payload pulsar_event_2014-09-15T05:00:00.000-07:00_2014-09-15T06:00:00.000-07:00_2014-09-15T05:00:00.000-07:00_1| pulsar_event | 2014-09-15T09:37:30.231-07:00 | 2014-09-15T05:00:00.000-07:00| 2014-09-15T06:00:00.000-07:00 | 1 | 2014-09-15T05:00:00.000-07:00 | 0 | {"dataSource":"pulsar_event","interval":"2014-09-15T05:00:00.000-07:00/2014-09-15T06:00:00.000-07:00","version":"2014-09-15T05:00:00.000-07:00","loadSpec":{"type":"hdfs","path":"hdfs://xxxx/20140915T050000.000-0700_20140915T060000.000-0700/2014-09-15T05_00_00.000-07_00/1/index.zip"},"dimensions":"browserfamily,browserversion,city,continent,country,deviceclass,devicefamily,eventtype,guid,js_ev_type,linespeed,osfamily,osversion,page,region,sessionid,site,tenant,timestamp,uid","metrics":"count","shardSpec":{"type":"linear","partitionNum":1},"binaryVersion":9,"size":60096778,"identifier":"pulsar_event_2014-09-15T05:00:00.000-07:00_2014-09-15T06:00:00.000-07:00_2014-09-15T05:00:00.000-07:00_1"}
For real-timeconfig:
A Druidingestion spec consists of 3 components:
{
"dataSchema": {...} #specify the incoming datascheme
"ioConfig": {...} #specify the data come andgo
"tuningConfig": {...} #some detail parameters
}
Realtime nodes do not need too much space as the segment will be deleted after handover successfully.
Historical Node
Historicalnodes load up historical segments and expose them for querying.
Historicalnodes keep constant connection to zk, and they do not connect to each otherdirectly. So zk environment is very important and if zk environment get into problems,historical cluster will lose nodes.
Whenquerying historical nodes, it will check the local disk (cache) for theinformation of the segment, otherwise it will turn to ZK to get the informationof the segment, which includes the where the segment is stored and how todecompress and process. After this, it will announce to zk that the segment isassociated with this node.

Theconfig of historical is not complex, and you may have a reference here: http://druid.io/docs/0.8.1/configuration/historical.html
Glanceat the resource of historical node of our QA environment (40 machines and weset cache expiration time to 30 days):
| Filesystem |
Size |
Used |
Avail |
Use% |
Mounted |
| /dev/sda1 |
49G |
15G |
31G |
33% |
/ |
| tmpfs |
127G |
0 |
127G |
0% |
/dev/shm |
| /dev/sda3 |
494G |
199M |
469G |
1% |
/data |
| /dev/sdb |
1.1T |
167G |
878G |
16% |
/data01 |
| /dev/sdc |
1.1T |
167G |
878G |
16% |
/data02 |
| /dev/sdd |
1.1T |
167G |
878G |
16% |
/data03 |
| /dev/sde |
1.1T |
167G |
878G |
16% |
/data04 |
| /dev/sdf |
1.5T |
168G |
1.2T |
13% |
/data10 |
Coordinator Node
Coordinator nodes are responsible to assignnew segments to historical nodes, which is done by creating an ephemeral ZKentry. In general, coordinator node is responsible for loading new, droppingold, manage replica and balance segment.
Coordinator runs periodically and it willassesses the cluster before taking action, which is based on rules defined byuser.
Rules set at coordinator:

CleanJobs
Losehistorical nodes
Themissing node will not be forgotten immediately and there will be a transitional data structure to represent a period of time. In this period,if we can start the historical again, the segments will not be reassigned.
Balance Segment
Determine the historical node with theutilization. Move segments from the highest to the lowest if the percentageexceeds the threshold.
Broker Node
Used to query real-time and historical andmerge the result.
Query process:
Cache
LRU is the strategy and broker is able tostore the result of per segment.
Query can be break to cache level and domerge.
Memcached is supported.
Real-time nodes are not cached as it isalways changing.
Indexing service
Used to create(or destroy) Druid Segments. Usually it is used to re-index historical data.
This partwe did not used that much and we had done some tests on this component, whichshowed that this part is not that impeccable.
An indexjob pic
Theoverlord node is responsible for accepting tasks, coordinating taskdistribution, creating locks around tasks, and returning statuses to callers
Middlemanager node is a worker node that executes submitted tasks
Peons runa single task in a single JVM. Middle Manager is responsible for creating Peonsfor running tasks.
Deep Dive intoDruid – the way that makes druid fast
General Storage strategy
Pre-aggregation/roll up
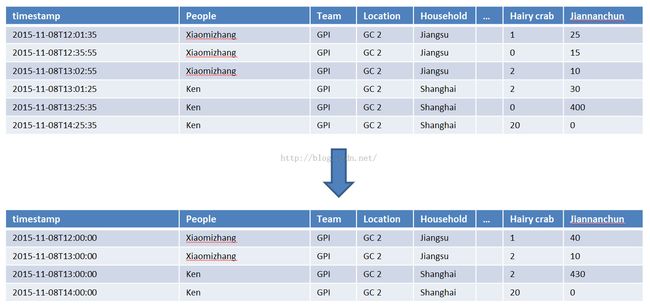
And the table ismade up by three things:

Partition Data
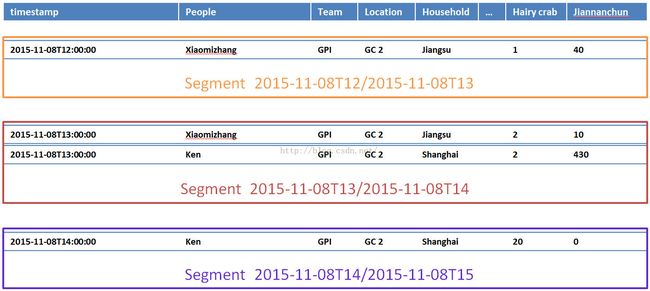
Immutable blocksof data called “segments” which is a fundamental storage unit in druid and nocontention between reads and writes
Column based storage
Druid scans/loadsonly what you need:

Columncompression – dictionaries
Create ids
• Xiaomizhang -> 0, Ken -> 1
‣ Store
• people -> [0 0 0 1 1 1]
• team -> [0 0 0 0 0 0]
Bitmap indices

‣ Xiaomizhang ->[0, 1, 2] -> [111000]
‣ Ken -> [3, 4, 5] -> [000111]
Fast and flexiblequeries
Thesummary of the structure of a segment:
1. Dictionary that encodes column values
{
"xiaomizhang": 0,
"Ken": 1
}
2. Column data
[0, 0, 1, 1]
3. Bitmaps - one for each unique value of thecolumn
value="xiaomizhang": [1,1,0,0]
value="Ken": [0,0,1,1]
Segmentdata Components
1. Version.bin
4 bytesrepresenting the current segment version as an integer
2. meta.smoosh
A filewith metadata (filenames and offsets) about the contents of theother smoosh files
3. xxxx.smoosh
There aresome number of these files, which are concatenated binary data
Thesmoosh files house individual files for each of the columns in the data
All aboveyou may know from the website or the QCon by druid team.
Then followingis:
Druid bug - Lessonspaid for with blood
1. Tryto restart coordinator and historical at the same time.
Once wedid this, and finally, we found that the historical nodes are living dead. Thethread of historical nodes are exits while from the log, they are not doinganything – because they do not receive any tasks from coordinator.
From thebasic knowledge of druid, we know that the components of druid are not isolate,they dependent on each other and cannot start druid components as a randomorder.

2. Tryto consume slc and phx kafka at the same real-time instance.
Kafka at slcand phx cluster is the same, the same data format, the same topic. Just for HA,we have to use two kafka clusters.
We had struggledat this for more than one month. We just knew something was wrong, but we didnot know what that is. We were luckyenough to have the druid contributor debug for us and he told us it is a druidbug.
3. Tryto use uppercase name
Recentlywe found that some real-time nodes did hand over segments but they are notdeleted. So the real-time nodes’ space was getting smaller and smaller, finallywe found a lot of segments were failed.
From logwe could not get anything that may help us to debug. Just ken casually saidthat except the name was uppercase, I did not find anything is weird, which remindedme that I had saw the druid google group posts and somebody told it is a druidbug.
4. Tryto use -9
Maybe itis a lower version of druid and in recent version of druid we did not find thiserror. Once we found that druid isunable to start again and from the log, the only information we get is thatdruid is unable to read the data as the format is not right.
Stopdruid forcibly will get unpredictable problem. But from our experience, if stopthe thread for more than 10 minutes, the thread is still there, it is able tostop the thread forcibly.My guessing is that the local diskIO is completed; maybe some network connection is not stopped.
Druid monitor anddaily issues
Pipeline trafficmonitor:
Reporting trafficmonitor
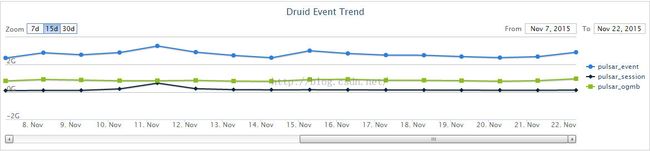
Comparewith metric calculator
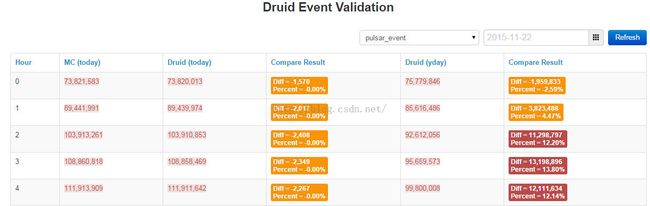
Druid hourlymonitor:
A jobrunning hourly to query the segments which are registered at My SQL:
With somany tools, we found problems such as:
Disk Full
1. Zookeeper disk full, which is alwayscaused by log. As time goes by, the log of zookeeper becomes larger and larger.Need to pay attention to both
2. Druid disk full. This happens morefrequent than 1. Real-time nodes handover fail and the segments are stored atthe very real-time node and usually each segment of druid is quite large, itwill be several MB for each data scheme and for each hour. If real-timehandover fail for a long period of time, the real-time node will be out ofspace and fail to consume
3. Druid disk full by druid temp files. Thishappens after we setup druid for more than half a year. Pay attention to thisparameter a druid startup file: -Djava.io.tmpdir should give a relatively largevolume at this path.
ZK issue
1. ZK machine down. This happens quitefrequent and most time we need to take other team's effort to make it recover.Bind cnames again and use fabric script to config the machines.
2. ZK machine OOM. We found this issue justlast week and we have run druid more than half a year. Usually we set druid todelete segments which are kept at druid for one or two months.One scheme is there all time long, because we forgot to clean the outdated data If we keep all the segments, the large traffic of our pipeline willcrash our druid cluster
Druid issue
1. Handover fails. Hand over need thecooperation of real time nodes, historical nodes, coordinator nodes and HDFScluster. Coordinator and HDFS are less likely to get into problems and if wefind hand over fail, we should check if all historical machines are healthy,last time we found historical nodes dead at a large scale and handover fail.
2. GC strategy. We tuning the parameters ofG1GC for some times and finally we choose not to set the parameters of G1. G1will automatically doing jobs for us such as the volume of each generationchange, if we setup a solid number, G1 will not be that efficiency.
3. HDFS path. It is OK to change the HDFSfile path. But once it is changed, please shutdown the cluster and re-configall things. And more, segments are recorded by My SQL. All segments'information is recorded including their dimensions’ types, schemes and HDSFpath. Please change the HDFS path manually.
4. Cachevolume. Both real-time and historical nodes have this setting. Segmentsassigned to a Historical node are first stored on the local file system (in adisk cache) and then served by the Historical node. These locations definewhere that local cache resides. Please set them properly.
Druid installationnotes:
1. Hadooppath should create or change
2. MySQL for segment setup
3. Real-timeand Historical path should change to the large space
4. Makethe user have the right to do things
5. Kafkagroup should be a new one
6. Installjava if needed
7. Ifprod machines unable to visit internet, copy all dependencies to the maven repoof prod machines
Links to refer:
Druidofficial website: http://druid.io/
DruidGoogle group: https://groups.google.com/forum/#!forum/druid-user