机器学习:线性判别分析LDA
定义:线性判别式分析(Linear discriminant analysis),又称为Fisher线性判别(Fisher linear discriminant)。
原理:将带上标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近。更多见机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)
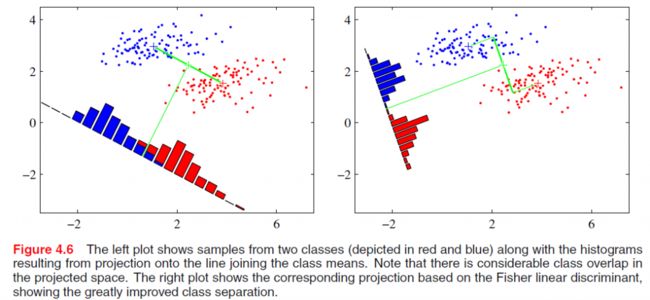
红色的方形的点为0类的原始点、蓝色的方形点为1类的原始点,经过原点的那条线就是投影的直线,从图上可以清楚的看到,红色的点和蓝色的点被原点明显的分开了,这个数据只是随便画的,如果在高维的情况下,看起来会更好一点。下面来推导一下二分类LDA问题的公式:
假设用来区分二分类的直线(投影函数)为:
![]()
LDA分类的一个目标是使得不同类别之间的距离越远越好,同一类别之中的距离越近越好,所以我们需要定义几个关键的值。
类别i的原始中心点为:(Di表示属于类别i的点)
类别i投影后的中心点为:
![]()
衡量类别i投影后,类别点之间的分散程度(方差)为:

最终我们可以得到一个下面的公式,表示LDA投影到w后的损失函数:

分类目标:使得类别内的点距离越近越好(集中),类别间的点越远越好。
主要方法:最大化类间均值,最小化类内方差。即,通过调整权重向量组件,可选择一个投影方向,最大化地类别分离性。
我们定义一个投影前的各类别分散程度的矩阵,这个矩阵看起来有一点麻烦,其实意思是,如果某一个分类的输入点集Di里面的点距离这个分类的中心店mi越近,则Si里面元素的值就越小,如果分类的点都紧紧地围绕着mi,则Si里面的元素值越更接近0.

带入Si,将J(w)分母化为:

![]()
同样的将J(w)分子化为:
![]()
这样损失函数可以化成下面的形式:

这样就可以用最喜欢的拉格朗日乘子法了,但是还有一个问题,如果分子、分母是都可以取任意值的,那就会使得有无穷解,我们将分母限制为长度为1(这是用拉格朗日乘子法一个很重要的技巧,在下面将说的PCA里面也会用到,如果忘记了,请复习一下高数),并作为拉格朗日乘子法的限制条件,带入得到:

这样的式子就是一个求特征值的问题了。
对于N(N>2)分类的问题,我就直接写出下面的结论了:

这同样是一个求特征值的问题,我们求出的第i大的特征向量,就是对应的Wi了。
-------------------------------------------------------------------------------PCA与LDA的区别:
主成分分析(PCA)与LDA有着非常近似的意思。
LDA的输入数据是带标签的,而PCA的输入数据是不带标签的,所以PCA是一种unsupervised learning(无监督学习)。
LDA通常来说是作为一个独立的算法存在,给定了训练数据后,将会得到一系列的判别函数(discriminate function),之后对于新的输入,就可以进行预测了。而PCA更像是一个预处理的方法,它可以将原本的数据降低维度,而使得降低了维度的数据之间的方差最大(也可以说投影误差最小)。