Hadoop+eclipse运行MapReduce程序
前面,我们已经通过eclipse下安装Hadoop的插件配置好了基于Hadoop+eclipse的MapReduce开发环境。现在,我们在这个Hadoop+eclipse环境下运行MapReduce程序。
一、新建MapReduce项目
【 File】—>【new】->【Project】,选择【Map/Reduce Project】,单击下一步,设置项目名称为WordCount,确定。
在WordCount项目下,新建类,类名为WordCount,其程序内容为WordCount.java。
二、设置HDFS的输入文件
hadoop fs -mkdir input hadoop fs -copyFromLocal WordCount.txt input我将WordCount.java源程序的内容拷到了WordCount.txt内,并上传到Input中作为程序的输入。
三、配置eclipse的运行参数
对本项目右键->【run】->【Run Configurations】,单击中间的Arguments,并设置输入输出参数。在Program arguments栏中输入:
hdfs://master:9000/user/abc/input hdfs://master:9000/user/abc/output其中abc是用户名,根据自己的用户名调整,可以在web方式下输入地址:master:50070后查看相关信息。
本文中的master是在localhost上,因为master可以替换成localhost。
点击【Run】或对本项目->【Run As】->【Run on Hadoop】,运行MapReduce程序。
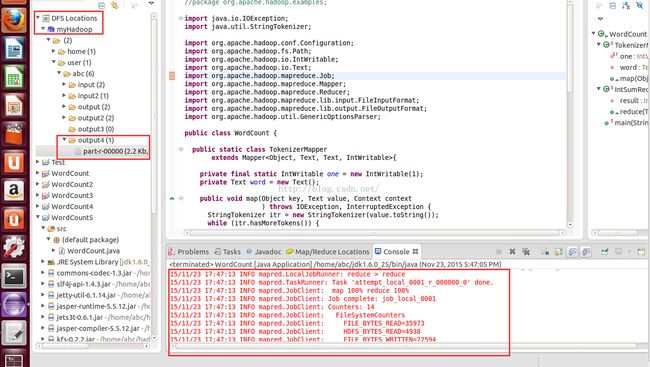
四、查看运行结果
点击【Run】后,eclipse的输出窗口中会显示,MapReduce程序运行的状态:
15/11/23 17:47:06 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
15/11/23 17:47:07 WARN mapred.JobClient: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
15/11/23 17:47:07 INFO input.FileInputFormat: Total input paths to process : 1
15/11/23 17:47:07 INFO mapred.JobClient: Running job: job_local_0001
15/11/23 17:47:07 INFO input.FileInputFormat: Total input paths to process : 1
15/11/23 17:47:07 INFO mapred.MapTask: io.sort.mb = 100
15/11/23 17:47:09 INFO mapred.JobClient: map 0% reduce 0%
15/11/23 17:47:11 INFO mapred.MapTask: data buffer = 79691776/99614720
15/11/23 17:47:11 INFO mapred.MapTask: record buffer = 262144/327680
15/11/23 17:47:11 INFO mapred.MapTask: Starting flush of map output
15/11/23 17:47:12 INFO mapred.MapTask: Finished spill 0
15/11/23 17:47:12 INFO mapred.TaskRunner: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
15/11/23 17:47:12 INFO mapred.LocalJobRunner:
15/11/23 17:47:12 INFO mapred.TaskRunner: Task 'attempt_local_0001_m_000000_0' done.
15/11/23 17:47:12 INFO mapred.LocalJobRunner:
15/11/23 17:47:12 INFO mapred.Merger: Merging 1 sorted segments
15/11/23 17:47:12 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 2723 bytes
15/11/23 17:47:12 INFO mapred.LocalJobRunner:
15/11/23 17:47:12 INFO mapred.JobClient: map 100% reduce 0%
15/11/23 17:47:13 INFO mapred.TaskRunner: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
15/11/23 17:47:13 INFO mapred.LocalJobRunner:
15/11/23 17:47:13 INFO mapred.TaskRunner: Task attempt_local_0001_r_000000_0 is allowed to commit now
15/11/23 17:47:13 INFO output.FileOutputCommitter: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://master:9000/user/abc/output4
15/11/23 17:47:13 INFO mapred.LocalJobRunner: reduce > reduce
15/11/23 17:47:13 INFO mapred.TaskRunner: Task 'attempt_local_0001_r_000000_0' done.
15/11/23 17:47:13 INFO mapred.JobClient: map 100% reduce 100%
15/11/23 17:47:13 INFO mapred.JobClient: Job complete: job_local_0001
15/11/23 17:47:13 INFO mapred.JobClient: Counters: 14
15/11/23 17:47:13 INFO mapred.JobClient: FileSystemCounters
15/11/23 17:47:13 INFO mapred.JobClient: FILE_BYTES_READ=35973
15/11/23 17:47:13 INFO mapred.JobClient: HDFS_BYTES_READ=4938
15/11/23 17:47:13 INFO mapred.JobClient: FILE_BYTES_WRITTEN=72594
15/11/23 17:47:13 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=2266
15/11/23 17:47:13 INFO mapred.JobClient: Map-Reduce Framework
15/11/23 17:47:13 INFO mapred.JobClient: Reduce input groups=0
15/11/23 17:47:13 INFO mapred.JobClient: Combine output records=114
15/11/23 17:47:13 INFO mapred.JobClient: Map input records=119
15/11/23 17:47:13 INFO mapred.JobClient: Reduce shuffle bytes=0
15/11/23 17:47:13 INFO mapred.JobClient: Reduce output records=0
15/11/23 17:47:13 INFO mapred.JobClient: Spilled Records=228
15/11/23 17:47:13 INFO mapred.JobClient: Map output bytes=3100
15/11/23 17:47:13 INFO mapred.JobClient: Combine input records=176
15/11/23 17:47:13 INFO mapred.JobClient: Map output records=176
15/11/23 17:47:13 INFO mapred.JobClient: Reduce input records=114
在eclipse的左上角DFS Locations下可以查看输入和输出结果,output下的part-r-00000即是WordCount程序的运行结果文件。
我这里因为多次运行,所以有多个output文件。
也可以在终端方式下查看运行结果:
hadoop fs -cat output/*
同时,在web方式下输入master:50070后进去查看运行结果也是可以的。
这次WordCount程序的运行结果为:
!= 1
"word 1
(IntWritable 1
(itr.hasMoreTokens()) 1
(otherArgs.length 1
+= 1
0 1
0; 1
1); 1
2) 1
: 2
<in> 1
<out>"); 1
= 8
? 1
Configuration(); 1
Context 1
Exception 1
GenericOptionsParser(conf, 1
IOException, 2
IntSumReducer 1
IntWritable 2
IntWritable(); 1
IntWritable(1); 1
IntWritable>{ 1
InterruptedException 2
Iterable<IntWritable> 1
Job(conf, 1
Mapper<Object, 1
Path(otherArgs[0])); 1
Path(otherArgs[1])); 1
Reducer<Text,IntWritable,Text,IntWritable> 1
StringTokenizer(value.toString()); 1
Text 2
Text(); 1
Text, 2
TokenizerMapper 1
WordCount 1
args) 1
args).getRemainingArgs(); 1
class 3
conf 1
context) 2
count"); 1
extends 2
final 1
import 12
itr 1
java.io.IOException; 1
java.util.StringTokenizer; 1
job 1
key, 2
main(String[] 1
map(Object 1
new 9
one 1
one); 1
org.apache.hadoop.conf.Configuration; 1
org.apache.hadoop.fs.Path; 1
org.apache.hadoop.io.IntWritable; 1
org.apache.hadoop.io.Text; 1
org.apache.hadoop.mapreduce.Job; 1
org.apache.hadoop.mapreduce.Mapper; 1
org.apache.hadoop.mapreduce.Reducer; 1
org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 1
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 1
org.apache.hadoop.util.GenericOptionsParser; 1
otherArgs 1
public 4
reduce(Text 1
result 1
result); 1
static 4
sum 1
throws 3
val 1
val.get(); 1
value, 1
values) 1
values,Context 1
void 3
word 1
wordcount 1
{ 8
} 4
Configuration 1
FileInputFormat.addInputPath(job, 1
FileOutputFormat.setOutputPath(job, 1
Job 1
String[] 1
System.exit(job.waitForCompletion(true) 1
if 1
job.setCombinerClass(IntSumReducer.class); 1
job.setJarByClass(WordCount.class); 1
job.setMapperClass(TokenizerMapper.class); 1
job.setOutputKeyClass(Text.class); 1
job.setOutputValueClass(IntWritable.class); 1
job.setReducerClass(IntSumReducer.class); 1
private 3
public 2
} 3
StringTokenizer 1
System.err.println("Usage: 1
System.exit(2); 1
context.write(key, 1
for 1
int 1
result.set(sum); 1
} 1
sum 1
while 1
} 1
context.write(word, 1
word.set(itr.nextToken()); 1