hadoop——linux下伪分布式环境搭建
1.准备Linux环境
1.0 设置虚拟机ip
点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only(也可以选桥接模式,具体看用处) ->修改subnet ip 设置网段:192.168.1.0 子网掩码:255.255.255.0 -> apply -> ok
回到windows –> 打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet1 -> 属性 -> 双击IPv4 -> 设置windows的IP:192.168.1.110 子网掩码:255.255.255.0 -> 点击确定
在虚拟软件上 –My Computer -> 选中虚拟机 -> 右键 -> settings -> network adapter -> host only -> ok
1.1修改主机名
# vim /etc/sysconfig/network NETWORKING = yes
HOSTNAME = itcast01 ###1.2修改IP
两种方式:
第一种:通过Linux图形界面进行修改
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.1.119 子网掩码:255.255.255.0 网关:192.168.1.1 -> apply
第二种:修改配置文件方式
# vim /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE="eth0"
BOOTPROTO="static" ###
HWADDR="00:0C:29:3C:BF:E7"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"
IPADDR="192.168.1.10" ###
NETMASK="255.255.255.0" ###
GATEWAY="192.168.1.1" ###
1.3修改主机名和IP的映射关系
# vim /etc/hosts
加入这一行内容:
192.168.1.10 itcast011.4关闭防火墙
查看防火墙状态
service iptables status
关闭防火墙
service iptables stop
查看防火墙开机启动状态
chkconfig iptables --list
关闭防火墙开机启动
chkconfig iptables off
1.5重启Linux
reboot2.安装JDK
2.1上传
使用FileZilla 拖拽到root目录下
2.2解压jdk
创建文件夹
# mkdir /usr/java解压
# tar -zxvf jdk-7u79-linux-i586.tar.gz -C /usr/java/
2.3将java添加到环境变量中
修改配置文件
# vim /etc/profile在文件最后添加
export JAVA_HOME=/usr/java/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin(linux中目录分隔使用“:”)
刷新配置
# source /etc/profile3.安装Hadoop
(资源路径:archive.apache.org/dist/ Apache所有的资源)
3.1上传hadoop安装包
3.2解压hadoop安装包
# mkdir /itcast解压到/itcast/目录下
# tar -zxvf hadoop-2.2.0.tar.gz -C /itcast /
-z:gzip文件 -x: extract 释放 -c:创建 -v:显示解压过程的详情 -f:file -C:要解压到的目录 3.3修改配置文件(5个)
第一个:hadoop-env.sh
在27行修改
export JAVA_HOME=/usr/java/jdk1.7.0_79保存并退出指令:shift+zz :ZZ
第二个:core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://itcast01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/cloud/hadoop-2.2.0/tmp</value>
</property>
</configuration>第三个:hdfs-site.xml
<configuration>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>第四个:mapred-site.xml.template
需要重命名:mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 通知框架以后MR使用YARN上 -->
<property> <name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>第五个:yarn-site.xml
<configuration>
<!—NodeManager获取数据的方式是shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!—YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>itcast01</value>
</property>
</configuration>3.4将hadoop添加到环境变量
# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_79
export HADOOP_HOME=/cloud/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
更新配置:
source /etc/profile3.5格式化HDFS(namenode)
(第一次使用时要格式化)
# hadoop namenode –format (已过时)
# hdfs namenode –format (用这个)3.6启动hadoop
在/itcast/hadoop-2.4.1/sbin目录下
先启动HDFS:
sbin/start-dfs.sh再启动YARN
sbin/start-yarn.sh (有个小问题:需要多次输入密码) 或者一次启动所有的脚本 ./start-all.sh (也过时了)
3.7验证是否启动成功
使用jps命令(查看当前正在运行的进程)验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
http://192.168.1.10:50070 (HDFS管理界面)
在这个文件中添加linux主机名和IP的映射关系
C:\Windows\System32\drivers\etc\hosts
192.168.1.110 itcast
http://192.168.1.10:8088 (MR管理界面)
上传文件到hdfs :
hadoop fs -put /root/jdk-7u79-linux-i586.gz hdfs://itcast01:9000/jdk
从hdfs下载文件:
hadoop fs -get hdfs://itcast01:9000/jdk /home/jdk1.7
---------------------------------------------
在hadoop/mapreduce目录下创建word.txt文本文档 :
vim words
运行hadoop-mapreduce-examples-2.4.1.jar 这个示例文档来统计words.txt文档的词数:
hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount hdfs://itcast01:9000/words 在浏览器查看上传的文件:
hdfs://itcast01:9000/wcouthdfs文件下载
使用: hadoop fs -get hdfs://itcast01:9000/wcout/ /home/jdk1.9 命令将这个文件下载到/home/jdk1.9目录下
统计结果:
hello 5
jerry 1
kitty 1
tom 2
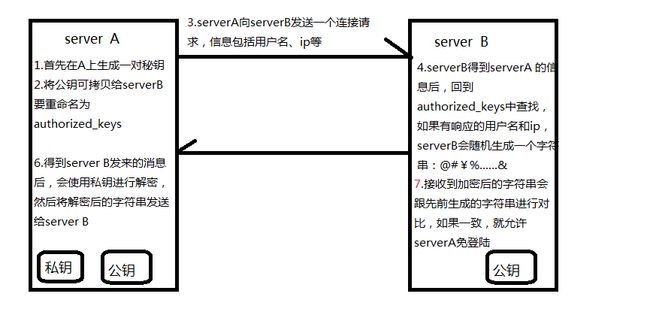
world 14.配置ssh免登陆
生成ssh免登陆密钥
- cd ~,进入到我的root目录( root == ~ )
cd .ssh/
ssh -keygen -t rsa (四个回车)
- 执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
- 将公钥拷贝到要免登陆的机器上
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
或 ssh-copy-id -i itcast01