caffe 实战系列:如何写自己的数据层(以Deep Spatial Net为例)
一、前言
想写自己的层,首先必须得在caffe.proto中定义自己层的参数,以便于在proto配置文件中对参数进行配置啦什么的,其次你还要在caffe.proto声明你的层的参数是可选的,然后你得在caffe的include目录下添加你自己层的hpp头文件,以及在caffe的src下的layer目录下添加你自己的cpp实现文件。
本文以 https://github.com/tpfister/caffe-heatmap中所实现的data_heatma.cpp和data_heatmap.hpp为例介绍如何写自己的层。
二、具体做法
(1)首先需要在caffe.proto中声明自己所写的层使用参数是可选的:
比如,首先在下面红色的位置加入
HeatmapDataParameter
// Layer type-specific parameters. // // Note: certain layers may have more than one computational engine // for their implementation. These layers include an Engine type and // engine parameter for selecting the implementation. // The default for the engine is set by the ENGINE switch at compile-time. optional AccuracyParameter accuracy_param = 102; optional ArgMaxParameter argmax_param = 103; optional ConcatParameter concat_param = 104; optional ContrastiveLossParameter contrastive_loss_param = 105; optional ConvolutionParameter convolution_param = 106; optional DataParameter data_param = 107; optional DropoutParameter dropout_param = 108; optional DummyDataParameter dummy_data_param = 109; optional EltwiseParameter eltwise_param = 110; optional EmbedParameter embed_param = 137; optional ExpParameter exp_param = 111; optional FlattenParameter flatten_param = 135; optional HeatmapDataParameter heatmap_data_param = 140;// 加入自己层的参数 optional HDF5DataParameter hdf5_data_param = 112; optional HDF5OutputParameter hdf5_output_param = 113; optional HingeLossParameter hinge_loss_param = 114; optional ImageDataParameter image_data_param = 115; optional InfogainLossParameter infogain_loss_param = 116; optional InnerProductParameter inner_product_param = 117; optional LogParameter log_param = 134; optional LRNParameter lrn_param = 118; optional MemoryDataParameter memory_data_param = 119; optional MVNParameter mvn_param = 120; optional PoolingParameter pooling_param = 121; optional PowerParameter power_param = 122; optional PReLUParameter prelu_param = 131; optional PythonParameter python_param = 130; optional ReductionParameter reduction_param = 136; optional ReLUParameter relu_param = 123; optional ReshapeParameter reshape_param = 133; optional SigmoidParameter sigmoid_param = 124; optional SoftmaxParameter softmax_param = 125; optional SPPParameter spp_param = 132; optional SliceParameter slice_param = 126; optional TanHParameter tanh_param = 127; optional ThresholdParameter threshold_param = 128; optional TileParameter tile_param = 138; optional WindowDataParameter window_data_param = 129; }
因为我们是将参数定义在了V1LayerParameter层下面的,需要在\src\caffe\util下的upgrade_proto.cpp中加入如下几行代码,方便已经训练好的模型进行转换。
const char* UpgradeV1LayerType(const V1LayerParameter_LayerType type) {
switch (type) {
case V1LayerParameter_LayerType_NONE:
return "";
case V1LayerParameter_LayerType_ABSVAL:
return "AbsVal";
case V1LayerParameter_LayerType_ACCURACY:
return "Accuracy";
case V1LayerParameter_LayerType_ARGMAX:
return "ArgMax";
case V1LayerParameter_LayerType_BNLL:
return "BNLL";
case V1LayerParameter_LayerType_CONCAT:
return "Concat";
case V1LayerParameter_LayerType_CONTRASTIVE_LOSS:
return "ContrastiveLoss";
case V1LayerParameter_LayerType_CONVOLUTION:
return "Convolution";
case V1LayerParameter_LayerType_DECONVOLUTION:
return "Deconvolution";
case V1LayerParameter_LayerType_DATA:
return "Data";
case V1LayerParameter_LayerType_DATA_HEATMAP:// 这是我们自己添加的输入数据的层
return "DataHeatmap";
case V1LayerParameter_LayerType_DROPOUT:
return "Dropout";
case V1LayerParameter_LayerType_DUMMY_DATA:
return "DummyData";
case V1LayerParameter_LayerType_EUCLIDEAN_LOSS:
return "EuclideanLoss";
case V1LayerParameter_LayerType_EUCLIDEAN_LOSS_HEATMAP:// 这是我们自己添加的计算损失函数的层
return "EuclideanLossHeatmap";
case V1LayerParameter_LayerType_ELTWISE:
return "Eltwise";
case V1LayerParameter_LayerType_EXP:
return "Exp";
case V1LayerParameter_LayerType_FLATTEN:
return "Flatten";
case V1LayerParameter_LayerType_HDF5_DATA:
return "HDF5Data";
case V1LayerParameter_LayerType_HDF5_OUTPUT:
return "HDF5Output";
case V1LayerParameter_LayerType_HINGE_LOSS:
return "HingeLoss";
case V1LayerParameter_LayerType_IM2COL:
return "Im2col";
case V1LayerParameter_LayerType_IMAGE_DATA:
return "ImageData";
case V1LayerParameter_LayerType_INFOGAIN_LOSS:
return "InfogainLoss";
case V1LayerParameter_LayerType_INNER_PRODUCT:
return "InnerProduct";
case V1LayerParameter_LayerType_LRN:
return "LRN";
case V1LayerParameter_LayerType_MEMORY_DATA:
return "MemoryData";
case V1LayerParameter_LayerType_MULTINOMIAL_LOGISTIC_LOSS:
return "MultinomialLogisticLoss";
case V1LayerParameter_LayerType_MVN:
return "MVN";
case V1LayerParameter_LayerType_POOLING:
return "Pooling";
case V1LayerParameter_LayerType_POWER:
return "Power";
case V1LayerParameter_LayerType_RELU:
return "ReLU";
case V1LayerParameter_LayerType_SIGMOID:
return "Sigmoid";
case V1LayerParameter_LayerType_SIGMOID_CROSS_ENTROPY_LOSS:
return "SigmoidCrossEntropyLoss";
case V1LayerParameter_LayerType_SILENCE:
return "Silence";
case V1LayerParameter_LayerType_SOFTMAX:
return "Softmax";
case V1LayerParameter_LayerType_SOFTMAX_LOSS:
return "SoftmaxWithLoss";
case V1LayerParameter_LayerType_SPLIT:
return "Split";
case V1LayerParameter_LayerType_SLICE:
return "Slice";
case V1LayerParameter_LayerType_TANH:
return "TanH";
case V1LayerParameter_LayerType_WINDOW_DATA:
return "WindowData";
case V1LayerParameter_LayerType_THRESHOLD:
return "Threshold";
default:
LOG(FATAL) << "Unknown V1LayerParameter layer type: " << type;
return "";
}
}
(2)然后在caffe.proto中下面的位置加入你自己的层的参数:
// VGG heatmap params 自己层的参数
message HeatmapDataParameter {
optional bool segmentation = 1000 [default = false];
optional uint32 multfact = 1001 [default = 1];
optional uint32 num_channels = 1002 [default = 3];
optional uint32 batchsize = 1003;
optional string root_img_dir = 1004;
optional bool random_crop = 1005; // image augmentation type
optional bool sample_per_cluster = 1006; // image sampling type
optional string labelinds = 1007 [default = '']; // if specified, only use these regression variables
optional string source = 1008;
optional string meanfile = 1009;
optional string crop_meanfile = 1010;
optional uint32 cropsize = 1011 [default = 0];
optional uint32 outsize = 1012 [default = 0];
optional float scale = 1013 [ default = 1 ];
optional uint32 label_width = 1014 [ default = 1 ];
optional uint32 label_height = 1015 [ default = 1 ];
optional bool dont_flip_first = 1016 [ default = true ];
optional float angle_max = 1017 [ default = 0 ];
optional bool flip_joint_labels = 1018 [ default = true ];
}还有可视化的测试参数
/ NOTE
// Update the next available ID when you add a new LayerParameter field.
//
// LayerParameter next available layer-specific ID: 139 (last added: tile_param)
message LayerParameter {
optional string name = 1; // the layer name
optional string type = 2; // the layer type
repeated string bottom = 3; // the name of each bottom blob
repeated string top = 4; // the name of each top blob
// The train / test phase for computation.
optional Phase phase = 10;
// The amount of weight to assign each top blob in the objective.
// Each layer assigns a default value, usually of either 0 or 1,
// to each top blob.
repeated float loss_weight = 5;
// Specifies training parameters (multipliers on global learning constants,
// and the name and other settings used for weight sharing).
repeated ParamSpec param = 6;
// The blobs containing the numeric parameters of the layer.
repeated BlobProto blobs = 7;
// Specifies on which bottoms the backpropagation should be skipped.
// The size must be either 0 or equal to the number of bottoms.
repeated bool propagate_down = 11;
// Rules controlling whether and when a layer is included in the network,
// based on the current NetState. You may specify a non-zero number of rules
// to include OR exclude, but not both. If no include or exclude rules are
// specified, the layer is always included. If the current NetState meets
// ANY (i.e., one or more) of the specified rules, the layer is
// included/excluded.
repeated NetStateRule include = 8;
repeated NetStateRule exclude = 9;
// Parameters for data pre-processing.
optional TransformationParameter transform_param = 100;
// Parameters shared by loss layers.
optional LossParameter loss_param = 101;
// Options to allow visualisation可视化层的参数,就这两货哈
optional bool visualise = 200 [ default = false ];
optional uint32 visualise_channel = 201 [ default = 0 ];
下面对各个参数进行解释:
segmentation 是否分割,默认是否, 假设图像的分割模板在segs/目录
multfact 将ground truth中的关节乘以这个multfact,就是图像中的位置,图像中的位置除以这个就是关节的位置,默认是1,也就是说关节的坐标与图像的坐标是一致大小的
num_channels 图像的channel数默认是3
batchsize batch大小
root_img_dir 存放图像文件的根目录
random_crop 是否需要随机crop图像(如果true则做随机crop,否则做中心crop)
sample_per_cluster 图像采样的类型(是否均匀地在clusters上采样)
labelinds 类标索引(只使用回归变量才设置这个)
source 存放打乱文件顺序之后的文件路径的txt文件
meanfile 平均值文件路径
crop_meanfile crop之后的平均值文件路径
cropsize crop的大小
outsize 默认是0(就是crop出来之后的图像会缩放的因子,0表示不缩放)
scale 默认是1,实际上就是一系列预处理(去均值、crop、缩放之后的像素值乘以该scale得到最终的图像的)
label_width heatmap的宽
label_height heatmap的高
dont_flip_first 不要对调第一个关节的位置,默认是true
angle_max 对图像进行旋转的最大角度,用于增强数据的,默认是0度
flip_joint_labels 默认是true(即水平翻转,将左右的关节对调)
为了保证完整性,把英文解释全部:
- visualise: show visualisations for crops, rotations etc (recommended for testing)
- source: label file
- root_img_dir: directory with images (recommend you store images on ramdisk)
- meanfile: proto file containing the mean image(s) to be subtracted (optional)
- cropsize: size of random crop (randomly cropped from the original image)
- outsize: size that crops are resized to
- multfact: label coordinates in the ground truth text file are multiplied by this (default 1)
- sample_per_cluster: sample evenly across clusters
- random_crop: do random crop (if false, do center crop)
- label_height/width: width of regressed heatmap (must match net config)
- segmentation: segment images on the fly (assumes images are in a segs/ directory)
- angle_max: max rotation angle for training augmentation
- flip_joint_labels: when horizontally flipping images for augmentation, if this is set to true the code also swaps left<->right labels (this is important e.g. for observer-centric pose estimation). This assumes that the left,right joint labelsare listed consecutively (e.g. wrist_left,wrist_right,elbow_left,elbow_right)
- dont_flip_first: This option allows you to turn off label mirroring for the first label. E.g. for labels head,wrist_right,wrist_left,elbow_right,elbow_left,shoulder_right,shoulder_left, the first joint is head and should not be swapped with wrist_right.
(3)这样,你就可以在proto中配置你自己层的参数了
下面给出一个配置heatmapdata层的实例:
layer {
name: "data"
type: "DataHeatmap" // 层的类型是DataHeatmap
top: "data"
top: "label"
visualise: false // 是否可视化
include: { phase: TRAIN }
heatmap_data_param {
source: "/data/tp/flic/train_shuffle.txt"
root_img_dir: "/mnt/ramdisk/tp/flic/"
batchsize: 14
cropsize: 248
outsize: 256
sample_per_cluster: false
random_crop: true
label_width: 64
label_height: 64
segmentation: false
flip_joint_labels: true
dont_flip_first: true
angle_max: 40
multfact: 1 # set to 282 if using preprocessed data from website
}
}
(4)heatmapdata层的实现
1)在介绍实现之前需要给出我们的训练数据的样子
看完参数,我们看一下训练的数据的格式感性理解一下:
下面给出一个样例:
train/FILE.jpg 123,144,165,123,66,22 372.296,720,1,480,0.53333 0
下面对样例做出解释
参数之间是以空格分隔
第一个参数是图像的路径:train/FILE.jpg
第二个参数是关节坐标:123,144,165,123,66,22
第三个参数是crop和scale的参数,分别为x_left,x_right,y_left,y_right,scaling_fact:372.296,720,1,480,0.53333
注意:第三个参数的crop的坐标其实上针对的是mean图像的,在mean图像中进行crop,然后放大到与原始图像一样大小,然后原始图像减去经过crop且放大之后的mean图像。这样在对原始图像进行crop的时候就不用担心了
第四个参数是是否cluster,是否均匀地在训练中采样图像: 0
This is a space-delimited file where
the first arg is the path to your image
the second arg is a comma-delimited list of (x,y) coordinates you wish to regress (the coordinates in the train/FILE.jpg image space)
the third arg is a comma-delimited list of crops & scaling factors of the input image (in order x_left,x_right,y_left,y_right,scaling_fact). Note: These crop & scaling factors are only used to crop the mean image. You can set these to 0 if you aren't using a mean image (for mean subtraction).
the fourth arg is a coordinate 'cluster' (from which you have the option to evenly sample images in training). You can set this to 0.
2)在讲解该层如何实现之前首先介绍点预备知识:
①首先给出在opencv中如何crop一幅图像
// You mention that you start with a CVMat* imagesource CVMat * imagesource; // Transform it into the C++ cv::Mat format cv::Mat image(imagesource); // Setup a rectangle to define your region of interest cv::Rect myROI(10, 10, 100, 100); // Crop the full image to that image contained by the rectangle myROI // Note that this doesn't copy the data cv::Mat croppedImage = image(myROI);
②如何进行随机crop以及中心crop
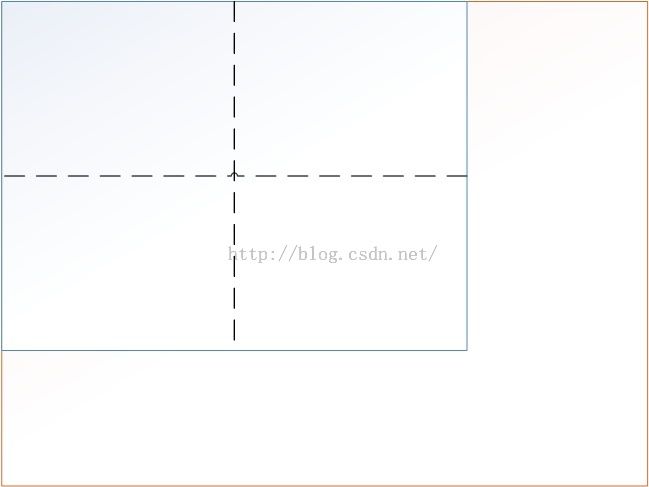
上图中的黄色边框表示图像
蓝色边框表示x_border = x-cropsize以及y_border=y-cropsize大小的crop区域
如果随机crop则表示从[0,x_border-1]以及[0,y_border-1]大小的区域(也就是图中的蓝色矩形框内)随机采集一个点坐标crop的左上角的点,然后以cropsize为边长取一个正方型。
如果是中心crop则取图中两个虚线的交点,即蓝色矩形的中心坐标crop的左上角的点,然后以cropsize为边长取一个正方形。
3)我们所写的层应该继承那个基类
我们所写的HeatmapData层是继承自BasePrefetchingDataLayer的(在文件data_layers.hpp中),下面给出其定义
template <typename Dtype>
class BasePrefetchingDataLayer :
public BaseDataLayer<Dtype>, public InternalThread {
public:
explicit BasePrefetchingDataLayer(const LayerParameter& param);
// LayerSetUp: implements common data layer setup functionality, and calls
// DataLayerSetUp to do special data layer setup for individual layer types.
// This method may not be overridden.
void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
// Prefetches batches (asynchronously if to GPU memory)
static const int PREFETCH_COUNT = 3
protected:
virtual void InternalThreadEntry();
virtual void load_batch(Batch<Dtype>* batch) = 0;
Batch<Dtype> prefetch_[PREFETCH_COUNT];
BlockingQueue<Batch<Dtype>*> prefetch_free_;
BlockingQueue<Batch<Dtype>*> prefetch_full_;
Blob<Dtype> transformed_data_;
};
4)实现自己的层
首先定义层的头文件
// Copyright 2014 Tomas Pfister
#ifndef CAFFE_HEATMAP_HPP_
#define CAFFE_HEATMAP_HPP_
#include "caffe/layer.hpp"
#include <vector>
#include <boost/timer/timer.hpp>
#include <opencv2/core/core.hpp>
#include "caffe/common.hpp"
#include "caffe/data_transformer.hpp"
#include "caffe/filler.hpp"
#include "caffe/internal_thread.hpp"
#include "caffe/proto/caffe.pb.h"
namespace caffe
{
// 继承自PrefetchingDataLayer
template<typename Dtype>
class DataHeatmapLayer: public BasePrefetchingDataLayer<Dtype>
{
public:
explicit DataHeatmapLayer(const LayerParameter& param)
: BasePrefetchingDataLayer<Dtype>(param) {}
virtual ~DataHeatmapLayer();
virtual void DataLayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual inline const char* type() const { return "DataHeatmap"; }
virtual inline int ExactNumBottomBlobs() const { return 0; }
virtual inline int ExactNumTopBlobs() const { return 2; }
protected:
// 虚函数,就是实际读取一批数据到Batch中
virtual void load_batch(Batch<Dtype>* batch);
// 以下都是自己定义的要使用的函数,都在load_batch中被调用了
// Filename of current image
inline void GetCurImg(string& img_name, std::vector<float>& img_class, std::vector<float>& crop_info, int& cur_class);
inline void AdvanceCurImg();
// Visualise point annotations
inline void VisualiseAnnotations(cv::Mat img_annotation_vis, int numChannels, std::vector<float>& cur_label, int width);
// Random number generator
inline float Uniform(const float min, const float max);
// Rotate image for augmentation
inline cv::Mat RotateImage(cv::Mat src, float rotation_angle);
// Global vars
shared_ptr<Caffe::RNG> rng_data_;
shared_ptr<Caffe::RNG> prefetch_rng_;
vector<std::pair<std::string, int> > lines_;
int lines_id_;
int datum_channels_;
int datum_height_;
int datum_width_;
int datum_size_;
int num_means_;
int cur_class_;
vector<int> labelinds_;
vector<cv::Mat> mean_img_;
bool sub_mean_; // true if the mean should be subtracted
bool sample_per_cluster_; // sample separately per cluster?
string root_img_dir_;
vector<float> cur_class_img_; // current class index
int cur_img_; // current image index
vector<int> img_idx_map_; // current image indices for each class
// array of lists: one list of image names per class
vector< vector< pair<string, pair<vector<float>, pair<vector<float>, int> > > > > img_list_;
// vector of (image, label) pairs
vector< pair<string, pair<vector<float>, pair<vector<float>, int> > > > img_label_list_;
};
}
#endif /* CAFFE_HEATMAP_HPP_ */
在介绍详细实现之前先口述一下实现的流程:
1)首先在SetUp该函数中读取,proto中的参数,从而获得一批数据的大小、heatmap的长和宽,对图像进行切割的大小,以及切割后的图像需要缩放到多大,还有就是是否需要对每个类别的图像进行采样、放置图像的根目录等信息。
此外还读取每个图像文件的路径、关节的坐标位置、crop的位置、是否进行采样。
如果在每个类上进行采样,还会生成一个数组,该数组对应的是图像的类别索引与图像的索引之间的映射。
此外还从文件中读取每个视频的mean,然后将所读取的mean放到vector容器中,便于在读取数据的时候从图像中取出mean。最后还会设置top的形状
2)在load_batch这个函数中就是真正地读取数据,并且对数据进行预处理,预处理主要是是否对图像进行分割,对平均值图像进行切割,并将切割的图像块放大到图像的大小,然后用图像减去该段视频切割并方法的平均值图像(你会不会觉得很奇怪,我也觉得很奇怪。。。竟然是切割平均值图像的,然后放大到与原图像一样的大小,然后再用原图像减去该均值图像,主要是原理我没想明白)。
// Copyright 2015 Tomas Pfisterimg
#include <fstream> // NOLINT(readability/streams)
#include <iostream> // NOLINT(readability/streams)
#include <string>
#include <utility>
#include <vector>
#include "caffe/data_layers.hpp"
#include "caffe/layer.hpp"
#include "caffe/util/io.hpp"
#include "caffe/util/math_functions.hpp"
#include "caffe/util/rng.hpp"
#include <stdint.h>
#include <cmath>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/highgui/highgui_c.h>
#include <opencv2/imgproc/imgproc.hpp>
#include "caffe/layers/data_heatmap.hpp"
#include "caffe/util/benchmark.hpp"
#include <unistd.h>
namespace caffe
{
template <typename Dtype>
DataHeatmapLayer<Dtype>::~DataHeatmapLayer<Dtype>() {
this->StopInternalThread();
}
// 读取参数文件中的一些数据什么的,然后初始化
template<typename Dtype>
void DataHeatmapLayer<Dtype>::DataLayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
HeatmapDataParameter heatmap_data_param = this->layer_param_.heatmap_data_param();
// Shortcuts
// 类标索引字符串(也就是关节类型?)
const std::string labelindsStr = heatmap_data_param.labelinds();
// batchsize
const int batchsize = heatmap_data_param.batchsize();
// heatmap的宽度
const int label_width = heatmap_data_param.label_width();
// heatmap的高度
const int label_height = heatmap_data_param.label_height();
// crop的大小
const int size = heatmap_data_param.cropsize();
// crop之后再次进行resize之后的大小
const int outsize = heatmap_data_param.outsize();
// label的batchsize
const int label_batchsize = batchsize;
// 每个cluster都要进行采样
sample_per_cluster_ = heatmap_data_param.sample_per_cluster();
// 存放图像文件的根路径
root_img_dir_ = heatmap_data_param.root_img_dir();
// initialise rng seed
const unsigned int rng_seed = caffe_rng_rand();
srand(rng_seed);
// get label inds to be used for training
// 载入类标索引
std::istringstream labelss(labelindsStr);
LOG(INFO) << "using joint inds:";
while (labelss)
{
std::string s;
if (!std::getline(labelss, s, ',')) break;
labelinds_.push_back(atof(s.c_str()));
LOG(INFO) << atof(s.c_str());
}
// load GT
// shuffle file
// 载入ground truth文件,即关节坐标文件
std::string gt_path = heatmap_data_param.source();
LOG(INFO) << "Loading annotation from " << gt_path;
std::ifstream infile(gt_path.c_str());
string img_name, labels, cropInfos, clusterClassStr;
if (!sample_per_cluster_)// 是否根据你指定的类别随机取图像
{
// sequential sampling
// 文件名,关节位置坐标,crop的位置,是否均匀地在clusters上采样
while (infile >> img_name >> labels >> cropInfos >> clusterClassStr)
{
// read comma-separated list of regression labels
// 读取关节位置坐标
std::vector <float> label;
std::istringstream ss(labels);
int labelCounter = 1;
while (ss)
{
// 读取一个数字
std::string s;
if (!std::getline(ss, s, ',')) break;
// 是否是类标索引中的值
// 如果labelinds为空或者为不为空在其中找到
if (labelinds_.empty() || std::find(labelinds_.begin(), labelinds_.end(), labelCounter) != labelinds_.end())
{
label.push_back(atof(s.c_str()));
}
labelCounter++;// 个数
}
// read cropping info
// 读取crop的信息
std::vector <float> cropInfo;
std::istringstream ss2(cropInfos);
while (ss2)
{
std::string s;
if (!std::getline(ss2, s, ',')) break;
cropInfo.push_back(atof(s.c_str()));
}
int clusterClass = atoi(clusterClassStr.c_str());
// 图像路径,关节坐标,crop信息、类别
img_label_list_.push_back(std::make_pair(img_name, std::make_pair(label, std::make_pair(cropInfo, clusterClass))));
}
// initialise image counter to 0
cur_img_ = 0;
}
else
{
// uniform sampling w.r.t. classes
// 根据类别均匀采样
// 也就是说图像有若干个类别,然后每个类别下有若干个图像
// 随机取其中一个图像
while (infile >> img_name >> labels >> cropInfos >> clusterClassStr)
{
// 获得你指定的类别
// 如果你制定为0
int clusterClass = atoi(clusterClassStr.c_str());
// 那么
if (clusterClass + 1 > img_list_.size())
{
// expand the array
img_list_.resize(clusterClass + 1);
}
// read comma-separated list of regression labels
// 读取关节的坐标位置到label这个vector
std::vector <float> label;
std::istringstream ss(labels);
int labelCounter = 1;
while (ss)
{
std::string s;
if (!std::getline(ss, s, ',')) break;
if (labelinds_.empty() || std::find(labelinds_.begin(), labelinds_.end(), labelCounter) != labelinds_.end())
{
label.push_back(atof(s.c_str()));
}
labelCounter++;
}
// read cropping info
// 读取crop信息到cropinfo这个vector
std::vector <float> cropInfo;
std::istringstream ss2(cropInfos);
while (ss2)
{
std::string s;
if (!std::getline(ss2, s, ',')) break;
cropInfo.push_back(atof(s.c_str()));
}
// 每个clusterClass下都是一个vector,用于装各种图像
img_list_[clusterClass].push_back(std::make_pair(img_name, std::make_pair(label, std::make_pair(cropInfo, clusterClass))));
}// while结尾
// 图像的类别个数
const int num_classes = img_list_.size();
// init image sampling
cur_class_ = 0;
// cur_class_img_中存放的是某个类别中随机取到的图像的索引值
cur_class_img_.resize(num_classes);
// init image indices for each class
for (int idx_class = 0; idx_class < num_classes; idx_class++)
{
// 是否需要根据类别随机取某个类别中的一个图像
if (sample_per_cluster_)
{
// img_list_[idx_class].size()是该idx_class这个类中图像的个数
// 产生从0-该类中图像个数之间的一个随机数
cur_class_img_[idx_class] = rand() % img_list_[idx_class].size();
// 图像类别个数
LOG(INFO) << idx_class << " size: " << img_list_[idx_class].size();
}
else
{
cur_class_img_[idx_class] = 0;
}
}
}
if (!heatmap_data_param.has_meanfile())// 是否有meanfile
{
// if no mean, assume input images are RGB (3 channels)
this->datum_channels_ = 3;
sub_mean_ = false;
} else {
// Implementation of per-video mean removal
// 下面整个一段代码是将每个视频mean文件读取到Mat结构
sub_mean_ = true;
// 从参数文件中获取mean文件的路径
string mean_path = heatmap_data_param.meanfile();
LOG(INFO) << "Loading mean file from " << mean_path;
BlobProto blob_proto, blob_proto2;
Blob<Dtype> data_mean;
// 读取到blob,然后blob数据转换到data_mean
ReadProtoFromBinaryFile(mean_path.c_str(), &blob_proto);
data_mean.FromProto(blob_proto);
LOG(INFO) << "mean file loaded";
// read config
this->datum_channels_ = data_mean.channels();
// mean值的数目,有多少个视频,就有多少个mean啊
num_means_ = data_mean.num();
LOG(INFO) << "num_means: " << num_means_;
// copy the per-video mean images to an array of OpenCV structures
const Dtype* mean_buf = data_mean.cpu_data();
// extract means from beginning of proto file
// mean文件中的图像的高度
const int mean_height = data_mean.height();
// mean文件中图像的宽度
const int mean_width = data_mean.width();
// 高度数组
int mean_heights[num_means_];
// 宽度数组
int mean_widths[num_means_];
// offset in memory to mean images
// 在mean图像中的偏移量
const int meanOffset = 2 * (num_means_);
for (int n = 0; n < num_means_; n++)
{
mean_heights[n] = mean_buf[2 * n];
mean_widths[n] = mean_buf[2 * n + 1];
}
// save means as OpenCV-compatible files
// 将从protobin文件读取的blob存放到Mat中
// 获得mean_image容器,这其中包含了若干个视频的mean值
// 下面是分配内存
for (int n = 0; n < num_means_; n++)
{
cv::Mat mean_img_tmp_;
mean_img_tmp_.create(mean_heights[n], mean_widths[n], CV_32FC3);
mean_img_.push_back(mean_img_tmp_);
LOG(INFO) << "per-video mean file array created: " << n << ": " << mean_heights[n] << "x" << mean_widths[n] << " (" << size << ")";
}
LOG(INFO) << "mean: " << mean_height << "x" << mean_width << " (" << size << ")";
// 下面是实际的赋值
for (int n = 0; n < num_means_; n++)
{
for (int i = 0; i < mean_heights[n]; i++)
{
for (int j = 0; j < mean_widths[n]; j++)
{
for (int c = 0; c < this->datum_channels_; c++)
{
mean_img_[n].at<cv::Vec3f>(i, j)[c] = mean_buf[meanOffset + ((n * this->datum_channels_ + c) * mean_height + i) * mean_width + j]; //[c * mean_height * mean_width + i * mean_width + j];
}
}
}
}
LOG(INFO) << "mean file converted to OpenCV structures";
}
// init data
// 改变数据形状
this->transformed_data_.Reshape(batchsize, this->datum_channels_, outsize, outsize);
top[0]->Reshape(batchsize, this->datum_channels_, outsize, outsize);
for (int i = 0; i < this->PREFETCH_COUNT; ++i)
this->prefetch_[i].data_.Reshape(batchsize, this->datum_channels_, outsize, outsize);
this->datum_size_ = this->datum_channels_ * outsize * outsize;
// init label
int label_num_channels;
if (!sample_per_cluster_)// 如果不按照类别进行均匀采样
label_num_channels = img_label_list_[0].second.first.size();// 获取关节坐标的数字的个数(注意是数字的个数,并不是坐标的个数,要除以2才能是坐标的个数哈)
else// 如果按照类别均匀采样
label_num_channels = img_list_[0][0].second.first.size();// 第0类的第0个图像的关节数字的个数
label_num_channels /= 2;// 获得关节个数
// 将输出设置为对应的大小
// top[0]是batchsize个图像数据
// top[1]是batchsize个heatmap(一个heatmap有关节个数个channel)
// label的batchsize,关节个数作为channel,关节的heatmap的高、关节heatmap的宽度
top[1]->Reshape(label_batchsize, label_num_channels, label_height, label_width);
for (int i = 0; i < this->PREFETCH_COUNT; ++i)
this->prefetch_[i].label_.Reshape(label_batchsize, label_num_channels, label_height, label_width);
LOG(INFO) << "output data size: " << top[0]->num() << "," << top[0]->channels() << "," << top[0]->height() << "," << top[0]->width();
LOG(INFO) << "output label size: " << top[1]->num() << "," << top[1]->channels() << "," << top[1]->height() << "," << top[1]->width();
LOG(INFO) << "number of label channels: " << label_num_channels;
LOG(INFO) << "datum channels: " << this->datum_channels_;
}
// 根据初始化之后的信息读取实际的文件数据,以及关节的位置,并将关节位置转换为类标
template<typename Dtype>
void DataHeatmapLayer<Dtype>::load_batch(Batch<Dtype>* batch) {
CPUTimer batch_timer;
batch_timer.Start();
CHECK(batch->data_.count());
HeatmapDataParameter heatmap_data_param = this->layer_param_.heatmap_data_param();
// Pointers to blobs' float data
// 指向数据和类标的指针
Dtype* top_data = batch->data_.mutable_cpu_data();
Dtype* top_label = batch->label_.mutable_cpu_data();
cv::Mat img, img_res, img_annotation_vis, img_mean_vis, img_vis, img_res_vis, mean_img_this, seg, segTmp;
// Shortcuts to params
// 是否显示读取的图像啥的,用户调试
const bool visualise = this->layer_param_.visualise();
// 是否对图像进行缩放
const Dtype scale = heatmap_data_param.scale();
// 每次读多少个图像
const int batchsize = heatmap_data_param.batchsize();
// heatmap的高度
const int label_height = heatmap_data_param.label_height();
// heatmap的宽度
const int label_width = heatmap_data_param.label_width();
// 需要旋转多少度
const float angle_max = heatmap_data_param.angle_max();
// 是否不要翻转第一个图
const bool dont_flip_first = heatmap_data_param.dont_flip_first();
// 是否翻转关节的坐标
const bool flip_joint_labels = heatmap_data_param.flip_joint_labels();
// 关节的坐标数值需要乘以这个multfact
const int multfact = heatmap_data_param.multfact();
// 图像是否需要分割
const bool segmentation = heatmap_data_param.segmentation();
// 切割的图像的块的带下
const int size = heatmap_data_param.cropsize();
// 切割之后的图像块需要缩放到outsize大小
const int outsize = heatmap_data_param.outsize();
const int num_aug = 1;
// 缩放因子
const float resizeFact = (float)outsize / (float)size;
// 是不是需要随机切图像块
const bool random_crop = heatmap_data_param.random_crop();
// Shortcuts to global vars
const bool sub_mean = this->sub_mean_;
const int channels = this->datum_channels_;
// What coordinates should we flip when mirroring images?
// For pose estimation with joints assumes i=0,1 are for head, and i=2,3 left wrist, i=4,5 right wrist etc
// in which case dont_flip_first should be set to true.
int flip_start_ind;
if (dont_flip_first) flip_start_ind = 2;
else flip_start_ind = 0;
if (visualise)
{
cv::namedWindow("original image", cv::WINDOW_AUTOSIZE);
cv::namedWindow("cropped image", cv::WINDOW_AUTOSIZE);
cv::namedWindow("interim resize image", cv::WINDOW_AUTOSIZE);
cv::namedWindow("resulting image", cv::WINDOW_AUTOSIZE);
}
// collect "batchsize" images
std::vector<float> cur_label, cur_cropinfo;
std::string img_name;
int cur_class;
// loop over non-augmented images
// 获取batchsize个图像,然后进行预处理
for (int idx_img = 0; idx_img < batchsize; idx_img++)
{
// get image name and class
// 获取文件名、label、cropinfo、类标
this->GetCurImg(img_name, cur_label, cur_cropinfo, cur_class);
// get number of channels for image label
// 获取关节的数值的个数(并不是关节个数哈,关节个数乘以2就是该数)
int label_num_channels = cur_label.size();
// 将根路径和文件名称拼接并读取数据到img
std::string img_path = this->root_img_dir_ + img_name;
DLOG(INFO) << "img: " << img_path;
img = cv::imread(img_path, CV_LOAD_IMAGE_COLOR);
// show image
// 显示读取的图像
if (visualise)
{
img_annotation_vis = img.clone();
this->VisualiseAnnotations(img_annotation_vis, label_num_channels, cur_label, multfact);
cv::imshow("original image", img_annotation_vis);
}
// use if seg exists
// 是否对图像分割
// 分割的模板存放在segs目录
// 读取分割模板到seg
if (segmentation)
{
std::string seg_path = this->root_img_dir_ + "segs/" + img_name;
std::ifstream ifile(seg_path.c_str());
// Skip this file if segmentation doesn't exist
if (!ifile.good())
{
LOG(INFO) << "file " << seg_path << " does not exist!";
idx_img--;
this->AdvanceCurImg();
continue;
}
ifile.close();
seg = cv::imread(seg_path, CV_LOAD_IMAGE_GRAYSCALE);
}
int width = img.cols;
int height = img.rows;
// size是crop的大小
// 如果crop的大小太大x_border会变成负数,下面会进行pad
int x_border = width - size;
int y_border = height - size;
// 将读取的图像转换为RGB
// convert from BGR to RGB
cv::cvtColor(img, img, CV_BGR2RGB);
// to float
// 转换数据类型到float
img.convertTo(img, CV_32FC3);
if (segmentation)
{
segTmp = cv::Mat::zeros(.rows, img.cols, CV_32FC3);
int threshold = 40;// 阈值
// 获取分割模板
seg = (seg > threshold);
// 对图像进行分割
segTmp.copyTo(img, seg);
}
if (visualise)
img_vis = img.clone();
// subtract per-video mean if used
// 减去每个视频的均值
int meanInd = 0;
if (sub_mean)
{
// 由此可以看到每个视频的命名规则,就是目录的名字嘛,而且还是数字
// 比如0,1,2,3,4
// 假设路径是images/1/xxx.jpg
// 那么获取的平均值索引就是1,然后再到mean_img_中得到对应的均值图像
std::string delimiter = "/";
std::string img_name_subdirImg = img_name.substr(img_name.find(delimiter) + 1, img_name.length());
std::string meanIndStr = img_name_subdirImg.substr(0, img_name_subdirImg.find(delimiter));
meanInd = atoi(meanIndStr.c_str()) - 1;
// subtract the cropped mean
mean_img_this = this->mean_img_[meanInd].clone();
DLOG(INFO) << "Image size: " << width << "x" << height;
DLOG(INFO) << "Crop info: " << cur_cropinfo[0] << " " << cur_cropinfo[1] << " " << cur_cropinfo[2] << " " << cur_cropinfo[3] << " " << cur_cropinfo[4];
DLOG(INFO) << "Crop info after: " << cur_cropinfo[0] << " " << cur_cropinfo[1] << " " << cur_cropinfo[2] << " " << cur_cropinfo[3] << " " << cur_cropinfo[4];
DLOG(INFO) << "Mean image size: " << mean_img_this.cols << "x" << mean_img_this.rows;
DLOG(INFO) << "Cropping: " << cur_cropinfo[0] - 1 << " " << cur_cropinfo[2] - 1 << " " << width << " " << height;
// crop and resize mean image
// 对mean文件进行切割并且调整其大小为图像大小
// cur_cropinfo中的数据分别为x_left,x_right,y_left,y_right
// 而Rect则是x,y,w,h,所以需要转换
cv::Rect crop(cur_cropinfo[0] - 1, cur_cropinfo[2] - 1, cur_cropinfo[1] - cur_cropinfo[0], cur_cropinfo[3] - cur_cropinfo[2]);
mean_img_this = mean_img_this(crop);// 这样就crop了
cv::resize(mean_img_this, mean_img_this, img.size());
DLOG(INFO) << "Cropped mean image.";
// 原图像减去crop之后并放大成与原图像一样大小的平均值图像
// 这是什么原理?????
img -= mean_img_this;
DLOG(INFO) << "Subtracted mean image.";
if (visualise)
{
img_vis -= mean_img_this;
img_mean_vis = mean_img_this.clone() / 255;
cv::cvtColor(img_mean_vis, img_mean_vis, CV_RGB2BGR);
cv::imshow("mean image", img_mean_vis);
}
}
// pad images that aren't wide enough
// 如果crop大小大于图像大小则padding,图像得右侧padding
if (x_border < 0)
{
DLOG(INFO) << "padding " << img_path << " -- not wide enough.";
// 函数原型如下
// void copyMakeBorder( const Mat& src, Mat& dst,
// int top, int bottom, int left, int right,
// int borderType, const Scalar& value=Scalar() );
cv::copyMakeBorder(img, img, 0, 0, 0, -x_border, cv::BORDER_CONSTANT, cv::Scalar(0, 0, 0));
width = img.cols;
x_border = width - size;
// add border offset to joints
// 因为pad过图像的右侧了所以需要调整关节的x坐标
for (int i = 0; i < label_num_channels; i += 2)// 注意这里是i+=2哦!
cur_label[i] = cur_label[i] + x_border;
DLOG(INFO) << "new width: " << width << " x_border: " << x_border;
if (visualise)// 显示经过padding的图像
{
img_vis = img.clone();
cv::copyMakeBorder(img_vis, img_vis, 0, 0, 0, -x_border, cv::BORDER_CONSTANT, cv::Scalar(0, 0, 0));
}
}
DLOG(INFO) << "Entering jitter loop.";
// loop over the jittered versions
// 将关节位置转换为heatmap
for (int idx_aug = 0; idx_aug < num_aug; idx_aug++)
{
// augmented image index in the resulting batch
const int idx_img_aug = idx_img * num_aug + idx_aug;
// 关节坐标,首先将从文件读取的关节坐标赋值给它
// 接下来因为要对图像进行crop,crop之后的图像还要resize
// 所以对应的关节坐标也要进行crop和缩放,经过这个处理的
// 关节位置就存放在了 cur_label_aug
std::vector<float> cur_label_aug = cur_label;
// 是否随机crop
if (random_crop)
{
// random sampling
DLOG(INFO) << "random crop sampling";
// horizontal flip
// 随机旋转是否需要水平翻转
if (rand() % 2)
{
// flip,0表示水平
// 水平翻转
cv::flip(img, img, 1);
if (visualise)
cv::flip(img_vis, img_vis, 1);
// "flip" annotation coordinates
// 将图像的坐标也翻转了
for (int i = 0; i < label_num_channels; i += 2)
// width 是原始图像的宽度,原始图像的宽度除以multfact就是关节的图像宽度,关节图像的宽度减去关节的x坐标就是翻转过来的x坐标
cur_label_aug[i] = (float)width / (float)multfact - cur_label_aug[i];
// "flip" annotation joint numbers
// assumes i=0,1 are for head, and i=2,3 left wrist, i=4,5 right wrist etc
// where coordinates are (x,y)
// 将索引位置也翻转了。。。
if (flip_joint_labels)
{
float tmp_x, tmp_y;
for (int i = flip_start_ind; i < label_num_channels; i += 4)
{
CHECK_LT(i + 3, label_num_channels);
tmp_x = cur_label_aug[i];
tmp_y = cur_label_aug[i + 1];
cur_label_aug[i] = cur_label_aug[i + 2];
cur_label_aug[i + 1] = cur_label_aug[i + 3];
cur_label_aug[i + 2] = tmp_x;
cur_label_aug[i + 3] = tmp_y;
}
}
}
// left-top coordinates of the crop [0;x_border] x [0;y_border]
// 生成左上的坐标,用于切割图像
int x0 = 0, y0 = 0;
x0 = rand() % (x_border + 1);
y0 = rand() % (y_border + 1);
// do crop
cv::Rect crop(x0, y0, size, size);
// NOTE: no full copy performed, so the original image buffer is affected by the transformations below
// img_crop与img公用一个内存,所以在img_crop中所作的更改对img也会有
cv::Mat img_crop(img, crop);
// "crop" annotations
// 万一关节的位置在crop的大小之外怎么办???疑问
for (int i = 0; i < label_num_channels; i += 2)
{
cur_label_aug[i] -= (float)x0 / (float) multfact;
cur_label_aug[i + 1] -= (float)y0 / (float) multfact;
}
// show image
if (visualise)
{
DLOG(INFO) << "cropped image";
cv::Mat img_vis_crop(img_vis, crop);
cv::Mat img_res_vis = img_vis_crop / 255;
cv::cvtColor(img_res_vis, img_res_vis, CV_RGB2BGR);
this->VisualiseAnnotations(img_res_vis, label_num_channels, cur_label_aug, multfact);
cv::imshow("cropped image", img_res_vis);
}
// rotations
// 旋转图像到一个均匀分布的角度
float angle = Uniform(-angle_max, angle_max);
cv::Mat M = this->RotateImage(img_crop, angle);
// also flip & rotate labels
// 遍历所有关节坐标
for (int i = 0; i < label_num_channels; i += 2)
{
// convert to image space
// 将关节坐标转换到图像中的坐标
float x = cur_label_aug[i] * (float) multfact;
float y = cur_label_aug[i + 1] * (float) multfact;
// rotate
// ?为啥
cur_label_aug[i] = M.at<double>(0, 0) * x + M.at<double>(0, 1) * y + M.at<double>(0, 2);
cur_label_aug[i + 1] = M.at<double>(1, 0) * x + M.at<double>(1, 1) * y + M.at<double>(1, 2);
// convert back to joint space
// 转换回关节空间
cur_label_aug[i] /= (float) multfact;
cur_label_aug[i + 1] /= (float) multfact;
}
img_res = img_crop;
} else {// 中心crop(就是图像的中心crop啊)
// determinsitic sampling
DLOG(INFO) << "deterministic crop sampling (centre)";
// centre crop
const int y0 = y_border / 2;
const int x0 = x_border / 2;
DLOG(INFO) << "cropping image from " << x0 << "x" << y0;
// do crop
cv::Rect crop(x0, y0, size, size);
cv::Mat img_crop(img, crop);
DLOG(INFO) << "cropping annotations.";
// "crop" annotations
// 长见识了,关节的annotation也是需要crop的
for (int i = 0; i < label_num_channels; i += 2)
{
// 除以multfact转换到关节坐标,然后再减去
// 不过我有疑问,万一crop之后的图像没有关节咋办
// 这样真的好吗
cur_label_aug[i] -= (float)x0 / (float) multfact;
cur_label_aug[i + 1] -= (float)y0 / (float) multfact;
}
if (visualise)
{
cv::Mat img_vis_crop(img_vis, crop);
cv::Mat img_res_vis = img_vis_crop.clone() / 255;
cv::cvtColor(img_res_vis, img_res_vis, CV_RGB2BGR);
this->VisualiseAnnotations(img_res_vis, label_num_channels, cur_label_aug, multfact);
cv::imshow("cropped image", img_res_vis);
}
img_res = img_crop;
}// end of else
// show image
if (visualise)
{
cv::Mat img_res_vis = img_res / 255;
cv::cvtColor(img_res_vis, img_res_vis, CV_RGB2BGR);
this->VisualiseAnnotations(img_res_vis, label_num_channels, cur_label_aug, multfact);
cv::imshow("interim resize image", img_res_vis);
}
DLOG(INFO) << "Resizing output image.";
// resize to output image size
// 将crop之后的图像弄到给定的大小
cv::Size s(outsize, outsize);
cv::resize(img_res, img_res, s);
// "resize" annotations
// resize 标注的关节
// 将图像进行缩放了,那么关节的坐标也要缩放
for (int i = 0; i < label_num_channels; i++)
cur_label_aug[i] *= resizeFact;
// show image
if (visualise)
{
cv::Mat img_res_vis = img_res / 255;
cv::cvtColor(img_res_vis, img_res_vis, CV_RGB2BGR);
this->VisualiseAnnotations(img_res_vis, label_num_channels, cur_label_aug, multfact);
cv::imshow("resulting image", img_res_vis);
}
// show image
if (visualise && sub_mean)
{
cv::Mat img_res_meansub_vis = img_res / 255;
cv::cvtColor(img_res_meansub_vis, img_res_meansub_vis, CV_RGB2BGR);
cv::imshow("mean-removed image", img_res_meansub_vis);
}
// multiply by scale
// 去均值、crop、缩放之后的像素值乘以该scale得到最终的图像的
if (scale != 1.0)
img_res *= scale;
// resulting image dims
const int channel_size = outsize * outsize;
const int img_size = channel_size * channels;
// store image data
// 将处理好的图像存放到top_data
DLOG(INFO) << "storing image";
for (int c = 0; c < channels; c++)
{
for (int i = 0; i < outsize; i++)
{
for (int j = 0; j < outsize; j++)
{
top_data[idx_img_aug * img_size + c * channel_size + i * outsize + j] = img_res.at<cv::Vec3f>(i, j)[c];
}
}
}
// store label as gaussian
// 将关节转换为高斯图像
DLOG(INFO) << "storing labels";
const int label_channel_size = label_height * label_width;
const int label_img_size = label_channel_size * label_num_channels / 2;
cv::Mat dataMatrix = cv::Mat::zeros(label_height, label_width, CV_32FC1);
float label_resize_fact = (float) label_height / (float) outsize;
float sigma = 1.5;
for (int idx_ch = 0; idx_ch < label_num_channels / 2; idx_ch++)
{
// 将经过缩放的关节转换到图像空间的坐标(也就是乘以multfact),再将缩小之后的图像空间坐标转换到缩小之前的图像空间坐标(也就是乘以label_resize_fact)
float x = label_resize_fact * cur_label_aug[2 * idx_ch] * multfact;
float y = label_resize_fact * cur_label_aug[2 * idx_ch + 1] * multfact;
for (int i = 0; i < label_height; i++)
{
for (int j = 0; j < label_width; j++)
{
// 计算索引
int label_idx = idx_img_aug * label_img_size + idx_ch * label_channel_size + i * label_height + j;
float gaussian = ( 1 / ( sigma * sqrt(2 * M_PI) ) ) * exp( -0.5 * ( pow(i - y, 2.0) + pow(j - x, 2.0) ) * pow(1 / sigma, 2.0) );
gaussian = 4 * gaussian;
// 存入到top_label
top_label[label_idx] = gaussian;
if (idx_ch == 0)
dataMatrix.at<float>((int)j, (int)i) = gaussian;
}
}
}
} // jittered versions loop
DLOG(INFO) << "next image";
// move to the next image
// Advance是进行
// Cur是表示当前
// 那么就是移动到下一个图像
this->AdvanceCurImg();
if (visualise)
cv::waitKey(0);
} // original image loop
batch_timer.Stop();
DLOG(INFO) << "Prefetch batch: " << batch_timer.MilliSeconds() << " ms.";
}
// 获取当前图像的路径、类标、crop信息、类别
template<typename Dtype>
void DataHeatmapLayer<Dtype>::GetCurImg(string& img_name, std::vector<float>& img_label, std::vector<float>& crop_info, int& img_class)
{
if (!sample_per_cluster_)
{
img_name = img_label_list_[cur_img_].first;
img_label = img_label_list_[cur_img_].second.first;
crop_info = img_label_list_[cur_img_].second.second.first;
img_class = img_label_list_[cur_img_].second.second.second;
}
else
{
img_class = cur_class_;
// 看见没,这里用到了cur_class_img_,这个在SetUp中生成的随机数作为该类别的图像索引,该随机数的范围在[0,该类别图像的个数-1]之间。
img_name = img_list_[img_class][cur_class_img_[img_class]].first;
img_label = img_list_[img_class][cur_class_img_[img_class]].second.first;
crop_info = img_list_[img_class][cur_class_img_[img_class]].second.second.first;
}
}
// 实际上就是移动索引
template<typename Dtype>
void DataHeatmapLayer<Dtype>::AdvanceCurImg()
{
if (!sample_per_cluster_)
{
if (cur_img_ < img_label_list_.size() - 1)
cur_img_++;
else
cur_img_ = 0;
}
else
{
const int num_classes = img_list_.size();
if (cur_class_img_[cur_class_] < img_list_[cur_class_].size() - 1)
cur_class_img_[cur_class_]++;
else
cur_class_img_[cur_class_] = 0;
// move to the next class
if (cur_class_ < num_classes - 1)
cur_class_++;
else
cur_class_ = 0;
}
}
// 可视化关节点
template<typename Dtype>
void DataHeatmapLayer<Dtype>::VisualiseAnnotations(cv::Mat img_annotation_vis, int label_num_channels, std::vector<float>& img_class, int multfact)
{
// colors
const static cv::Scalar colors[] = {
CV_RGB(0, 0, 255),
CV_RGB(0, 128, 255),
CV_RGB(0, 255, 255),
CV_RGB(0, 255, 0),
CV_RGB(255, 128, 0),
CV_RGB(255, 255, 0),
CV_RGB(255, 0, 0),
CV_RGB(255, 0, 255)
};
int numCoordinates = int(label_num_channels / 2);
// points
// 将关节点放到centers数组中
cv::Point centers[numCoordinates];
for (int i = 0; i < label_num_channels; i += 2)
{
int coordInd = int(i / 2);
centers[coordInd] = cv::Point(img_class[i] * multfact, img_class[i + 1] * multfact);
// 给关节画圈圈
cv::circle(img_annotation_vis, centers[coordInd], 1, colors[coordInd], 3);
}
// connecting lines
// 1,3,5是一条膀子
// 2,4,6是一条膀子
cv::line(img_annotation_vis, centers[1], centers[3], CV_RGB(0, 255, 0), 1, CV_AA);
cv::line(img_annotation_vis, centers[2], centers[4], CV_RGB(255, 255, 0), 1, CV_AA);
cv::line(img_annotation_vis, centers[3], centers[5], CV_RGB(0, 0, 255), 1, CV_AA);
cv::line(img_annotation_vis, centers[4], centers[6], CV_RGB(0, 255, 255), 1, CV_AA);
}
// [min,max]的均匀分布
template <typename Dtype>
float DataHeatmapLayer<Dtype>::Uniform(const float min, const float max) {
float random = ((float) rand()) / (float) RAND_MAX;
float diff = max - min;
float r = random * diff;
return min + r;
}
// 旋转图像
template <typename Dtype>
cv::Mat DataHeatmapLayer<Dtype>::RotateImage(cv::Mat src, float rotation_angle)
{
cv::Mat rot_mat(2, 3, CV_32FC1);
cv::Point center = cv::Point(src.cols / 2, src.rows / 2);
double scale = 1;
// Get the rotation matrix with the specifications above
rot_mat = cv::getRotationMatrix2D(center, rotation_angle, scale);
// Rotate the warped image
cv::warpAffine(src, src, rot_mat, src.size());
return rot_mat;
}
INSTANTIATE_CLASS(DataHeatmapLayer);
REGISTER_LAYER_CLASS(DataHeatmap);
} // namespace caffe
最后别忘记注册你自己的层。
总结:虽然本文写的复杂,主要是为了分析data_heatmap.cpp的实现了,所以略显复杂。然后实际的新增层的步骤并不复杂,主要就是在caffe.proto中添加层参数,并添加自己的参数为可选,然后自己继承一个层的基类,然后实现该类即可,注意最后别忘记注册自己的层类。
相关的注释代码可以从http://download.csdn.net/detail/xizero00/9471133下载。
参考
[1]另一个介绍如何写层的
http://blog.csdn.net/kuaitoukid/article/details/41865803
[2]caffe的issue也介绍了如何新建自己的层
https://github.com/BVLC/caffe/issues/684
[3]本文所涉及的源代码以及对应的论文
https://github.com/tpfister/caffe-heatmap
[4]你可能需要了解cpp中的pair
http://www.cplusplus.com/reference/utility/make_pair/