SQL 统计分组 Group By和Compute By的整理
在日常的项目开发中数据统计方面大家都常常用到Groub By进行分组,可能很少人用Compute By吧,我今天也是第一次使用,以前没有写博客的习惯,只是把自己的经验都整理起来都保存到了YX笔记当中,就从这一篇开始吧,把自己的一些经验写出来,一方面可以让自己再梳理下以前的知识。本人菜鸟,大牛勿喷,不喜勿入!从不在意什么排名,也不在意什么评论的数量,any way,走我自己的路管你那么多!
好了,进入正题,比如说项目中你需要按类别统计商品的总价,或者因为多表连接之后你出现了重复的数据(当然你可以用开窗函数),貌似我想不出来还有其他的作用了,毕竟本人就是菜鸟一枚,有大牛知道的话能告知下。例:
有如下的商品数据:
想要按照类别查看价格的总和,ok!
Select t.GoodsType,SUM(t.Price) From T_Goods t Group By t.GoodsType得到的结果
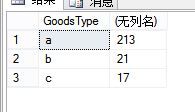
Group By就是分组,根据Group By后的字段名就行分组,若有多个字段就先根据第一个字段分组,再在满足第一个字段的子集中按照第二个字段再进行分组,依次类推。
再看看这个:
Select t.GoodsType,SUM(t.Price),t.Remark From T_Goods t Group By t.GoodsType,t.Remark
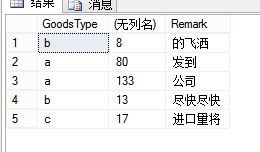
这里插播一个知识点,我们大家都知道Group By 可以跟Having 和Where 连用,但是两者是有细微区别的,请看这段
Select t.GoodsType,SUM(t.Price) TotalPrice From T_Goods t Where t.Price>=20 Group By t.GoodsType --Having SUM(t.Price) >=20使用where的结果 VS Having的结果:
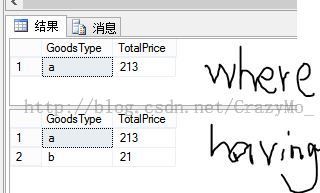
当然有些数据两个查询结果是相同的,但是两者确确实实地存在区别的,构造出这个数据我也试了几次,
where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。而having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
而Compute By 也是分组,与Group By的区别在于Compute By 可以显示出细节:
请看
Select * from T_Goods t Order By t.GoodsType Compute Max(t.Price),Min(t.Price),AVG(t.Price) By t.GoodsType
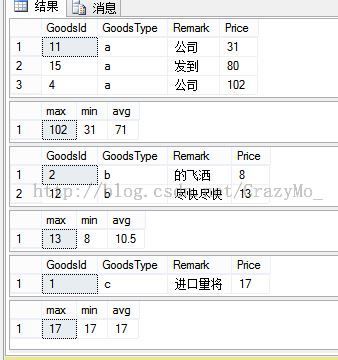
说实话我现在也没有在项目中用过Compute By,下面的统计行和数据行是什么关系,我也不是很清楚,求大神告知!