布隆过滤器的原理、实现和探究

作者:金良([email protected]) csdn博客:http://blog.csdn.net/u012176591
1.布隆过滤器的使用价值

图1 布隆迪过滤器的映射方法
现在,让我们看看如何用布隆过滤器来检测一个WEB网页地址Y是否已经被我们收录。用相同的8个随机数生成器(f1,f2,...,f8)对这个WEB网页地址产生8个信息指纹s1,s2,...s8,然后将这8个指纹对应到布隆过滤器的8个二进制位,分别是t1,t2,...,t8。如果Y已被收录,显然t1,t2,...,t8对应的8个二进制位一定是1。通过这样的方式我们能够很快地确定一个WEB页面是否已被我们收录。
2.布隆过滤器的实现
布隆过滤器实现代码:
#encoding=UTF-8
'''
Created on 2014年6月21日
@author: jin
'''
import BitVector
class MyHash():#哈希类,根据不同参数初始化后作为不同的哈希函数
def __init__(self, cap, seed):
self.cap = cap
self.seed = seed
def hash(self, value): #计算哈希值得过程
ret = 0
for i in range(len(value)):
ret += self.seed*ret + ord(value[i]) #ord()函数计算传入的url字符串中每一个字符在ASCII码表中对应的顺序值
return (self.cap-1) & ret #返回哈希值,即在比特序列中的位置
class BloomFilter():
def __init__(self, BIT_SIZE=1<<31):
self.BIT_SIZE = 1 << 31 #不拢过滤器的比特数,
self.seeds = [5, 7, 11, 13,19, 31, 37, 61] #8个种子,用于产生hash函数
self.bitset = BitVector.BitVector(size=self.BIT_SIZE)
self.hashFuncList = []
for i in range(len(self.seeds)):
self.hashFuncList.append(MyHash(self.BIT_SIZE, self.seeds[i])) #对每个种子,创建一个MyHash对象,一共8个
def insert(self, value): #插入值,这里并非真正地插入并存储,而是把该值对应的8个位置的比特位置为1
for function in self.hashFuncList:
locationBit = function.hash(value) #计算应该置为1的比特位
self.bitset[locationBit] = 1
def isContaions(self, value):
if value == None:
return False
ret = True
for f in self.hashFuncList:
locationBit = f.hash(value)
ret = ret & self.bitset[locationBit] #可以看出,对8个哈希函数,只要有一个为0,那么将返回0,即该值尚未存在
return ret
def Main(): #主函数
fd = open("urls.txt") #有重复的网址 http://www.kalsey.com/tools/buttonmaker/
bloomfilter = BloomFilter()
while True:
url = fd.readline()
if cmp(url, 'exit') == 0:
print 'complete and exit now'
break
elif bloomfilter.isContaions(url) == False:
bloomfilter.insert(url)
else:
print 'url :%s has exist' % url
Main()
url.txt内部存储有一系列网址,最后一行是‘exit’,内容如下:
http://sourceforge.net/robots.txt http://sourceforge.net/ http://sourceforge.net http://sourceforge.net and https://sourceforge.net http://sourceforge.net/sitemap.xml http://sourceforge.net/allura_sitemap/sitemap.xml http://sourceforge.net/directory_sitemap.xml http://a.fsdn.com http://a.fsdn.com/con/img/sftheme/favicon.ico http://a.fsdn.com/con/js/min/sf.head.js http://a.fsdn.com/con/js/sftheme/dd_belatedpng.js http://fonts.googleapis.com http://fonts.googleapis.com/css http://a.fsdn.com/con/css/sf.css http://sourceforge.net/blog/feed/ http://email.playtime.uni.cc/ http://services.nexodyne.com/email/ http://gizmo967.mgs3.org/Gmail/ http://www.hkwebs.net/catalog/tools/gmail/ http://sagittarius.dip.jp/~toshi/cgi-bin/designmail/designmail.html http://www.eoool.com/ http://sourceforge.netand https://sourceforge.net http://a.fsdn.com/con/js/adframe.js http://sourceforge.net/directory/ http://kalsey.com/tools/buttonmaker/ http://www.lucazappa.com/brilliantMaker/buttonImage.php http://www.feedforall.com/public/rss-graphic-tool.htm http://www.yugatech.com/make.php http://www.hkwebs.net/catalog/tools/buttonmaker/index.php http://phorum.com.tw/Generator.aspx http://www.logoyes.com/lc_leftframe.htm http://cooltext.com/Default.aspx exit运行效果如下,可以看到未发生存储地址冲突:
complete and exit now往url.txt里面再增加一个原来未有的网址
http://www.kalsey.com/tools/buttonmaker/,再次运行,竟然发生了冲突,如下:
url :http://www.kalsey.com/tools/buttonmaker/ has exist complete and exit now这说明此网址和另外一个网址对应的8个信息指纹相同,虽然它们本身的值是不同的,这就产生了冲突。
可以看到布隆过滤器有一定的误识别率。下面我们对其进行分析。
3.误识别率的问题
假定布隆过滤器有m比特,里面有n个元素,每个元素对应k个信息指纹的哈希函数,当然m个比特里有0也有1。我们假定某个比特为0,在这个布隆过滤器里插入一个元素,他的第一个哈希函数会把过滤器中的某个比特置为1,理想情况下,任一比特位被置1的概率是1/m,它依然为0的概率则是1-1/m。对于过滤器中的一个特定位置,如果这个元素的k个哈希函数都没有把它设置成1,其概率是 ![]() 。如果过滤器插入第二个元素,这个特定位置仍不被置1的概率是
。如果过滤器插入第二个元素,这个特定位置仍不被置1的概率是![]() ,类似的,插入n个元素其仍为0的概率是
,类似的,插入n个元素其仍为0的概率是![]() 。反过来,一个比特在插入n个元素后,被置1的概率则是
。反过来,一个比特在插入n个元素后,被置1的概率则是![]() 。
。
现在假定这n个元素都放到布隆过滤器中了,新来的一个不在集合中的元素,由于它的信息指纹的哈希函数都是随机的,因此,它的第一个哈希函数正好命中某个值为1的比特的概率就是上述概率。一个不再集合中的元素被误识别为已经在集合中,需要所有的哈希函数对应的比特值均为1,其概率为


我们下面对简化的误识别率的公式进行研究。
图2 误识别率与m/n的关系
图2的代码:
k=8
r = np.linspace(1,50,1000)
p = np.power(1-np.exp(-k/r),k)
plt.title('misjudgment & m/n')
plt.plot(r,p)
plt.xlabel('m/n')
plt.ylabel('misjudgment')
plt.show()
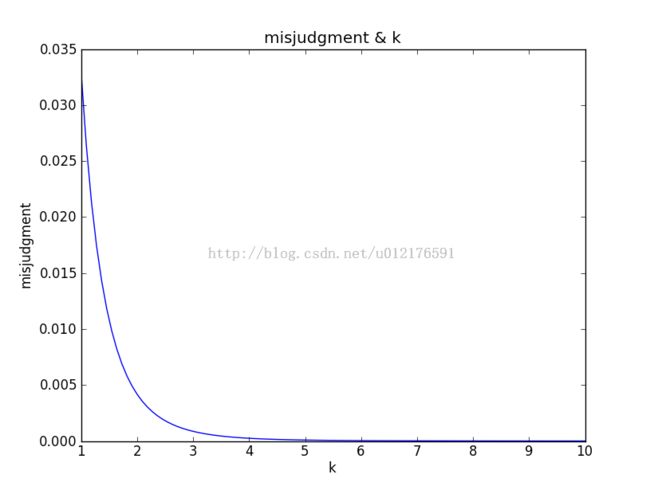
图3 误识别率与k的关系
图3的代码:
r = 30;
k = np.linspace(1,10,100)
p = np.power(1-np.exp(-k/r),k)
plt.title('misjudgment & k')
plt.xlabel('k')
plt.ylabel('misjudgment')
plt.plot(k,p)
plt.show()