Oracle 索引(一)
在Oracle中,索引可以分为逻辑设计和物理实现:
逻辑角度: Single column 单列索引、Concatenated 多列索引(复合索引)、Unique 唯一索引、NonUnique 非唯一索引、Function-based函数索引、Domain 域索引(数据库以外的索引,如文件等)、interMedia全文索引等
物理实现: Partitioned 分区索引、NonPartitioned 非分区索引、
B-tree索引、Rever Key 反转型B树(这种分类是B-tree索引的一种)、Bitmap 位图索引
常用的是B*Tree索引和位图索引,当你创建索引时默认的是B*Tree索引。
(1)B*Tree索引:平衡树形索引,在叶子节点上有双向链表,加快索引定位速度,oracle有一定的优化,可以根据链表直接定位记录,而不走树,综合使用提高速度。数据都位于基于索引的叶子节点中。叶子节点中包含了构建索引的关键数据和源表中行的rowid。B树索引所有的叶子节点都具有相同的深度,所以无论查询条件是哪种类型或写法,都具有相同的查询速度。无论对于大型表还是小型表,B树索引的效率都是相同的.(这句话是正确的?大小型表对于B树索引的查询没有影响?定位时间上和空间上的差异呢?待求证)
一个索引项只会指向一个单独的表数据块,而且一次只能读取一个数据块。(这句话当时不是很理解,看了ROWID的时候稍微有所理解了,注意是索引”项“):ORACLE把ROWID作为B-树和其内部算法标示ROW的唯一标示。
ROWID的结构:使用base-64代码,包括a-z,A-Z,0-9,+,-。一共18位。
1-6位:代表OBJECT
7-9位:文件相对值
10-15:文件中的BLOCK(一个索引项带一个ROWID,而一个ROWID指向一个块)
16-18:BLOCK中的SLOT值
。
----------------------------------------------------------------------------------------------------------------------
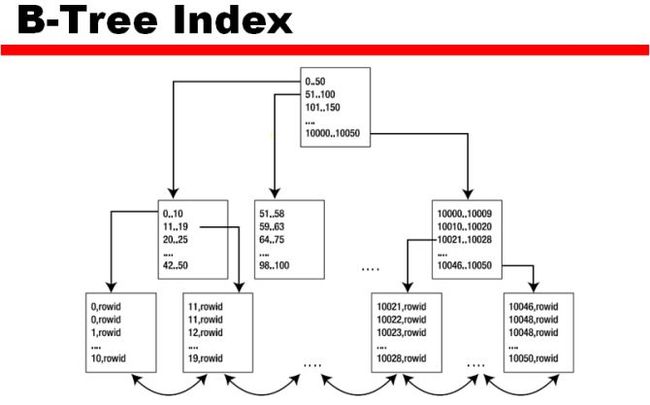
看到此图中的一个叶子节点由4部分组成:
1)在索引的叶子节点的entries的具体格式,如上图:
* entry header:保存了columns的数量和锁信息。
* key column length-value对:指明了在index key中,column的长度,以及具体的column值。
* ROWID
2)在nonpartitioned table的b-tree index中,如果有多rows有相同的value,key values将会重复存放;index实体不能有所有key columns都为NULL的情况,所以当where子句中出现NULL是,会产生全表扫描;ROWID用于指定表中的具体rows。
3)当DML操作发生时,Oracle Server会对indexes进行下面的维护
* 插入操作会引起index entry向index block的插入操作
* delete操作会引起indexes中逻辑上的删除。被删除的indexes entry所产生的空闲空间不能得到马上的利用,直到其所在block中的entries都被删除。
* update操作对于indexes会引起逻辑的删除旧的indexes,再插入新的indexes。除了在create阶段,参数PCTFREE的设置并不影响indexes。一个新的entry将被添加到index block中,即使该block的space不足PCTFREE。
(2)Bitmap 位图索引:用二进制的0、1来构建索引,在进行or操作时非常快, 见图。位图索引是在低区分值列上创建的压缩对象。
创建位图索引时,Oracle会对整个表进行扫描,并为索引列的每个取值建立一个位图.(我的理解是:类似二进制里的一位只能被一个键值使用为1,其他键值的此位只能表示为0,如下图中,每种颜色的值在BITMAP的二进制代码里得到了体现,使用或运算,得到每位都是1)
1)当table有大量数据并且其key columns的基数(关键字不同的值)较少时,查询时常使用OR等组合的WHERE子句,对索引关键字的修改非常少,此时bitmap index的性能更优于b-tree index。
2)bitmap index也是由一个b-tree组成,但是其叶子节点为每个key value存储了一个bitmap,而不是ROWID。bitmap中的每个bit相当于一个可能的ROWID。
如上图,bitmap index的结构包含:
* entry header:包括columns的数量和lock信息。
* key values:由每个关键字的长度和value对组成。
* start ROWID
* end ROWID
* bitmap segment:有一个bits string组成。
如果要搜索表的值的话,那么Oracle会用内部的转换函数将位图中的相关信息转换成rowid来访问数据块。
3)bitmap indexes中的key发生改变时,将会引起bitmap的改变。这就需要对相应的bitmap的segment加锁,所以其他的transaction就不能再进行修改操作。所以对性能有一定影响。(因为bitmap对于并发操作时,改一条会锁了很多记录,因为所有的记录在一个索引条目上,所以修改或增加时会一起锁定)
4)b-tree indexes与 bitmap indexes 比较:
| B-tree索引 |
Bitmap 索引 |
| Suitable for high-cardinality columns(记录对应的列重复的值较少,如主键,姓名等 )。 |
Suitable for low-cardinality columns(用在记录相同的值较多的列上,如果性别只有两种值:男和女)。 |
| Updates on keys relatively inexpensive (在做updated时,b-tree只消耗很少的资源)。 |
Updates to key columns very expensive (在做updated时,bitmap的消耗是昂贵的)。 |
| Inefficient for queries using OR predicates(where子句中 or条件较多时速度较慢) |
Effcient for queries using OR predicates (where子句中 or条件较多时速度非常快) |
| Useful for OLTP(记录频繁的insert和update,查询相对较少的系统)。 |
Useful for data warehousing (OLIP)数据仓库,查询系统等较少做数据修改的系统。 |
(3)复合索引
复合索引也是一种B*树索引,它由多列组成。当我们拥有使用两列或超过两列的频繁查询时,就使用B*树复合索引,而其所使用的两列或多列在 where子句中and逻辑操作符连接。因为复合索引中列的顺序很重要,所以确信以最有效的索引能排列他们,可以参考用作列排序的下面的两个准则 :
1) 前导列应该是查询中使用最频繁的列。
2) 前导列应该是选择最多的列,这意味着它比后面的列具有更高的基数。
复合索引在下列情况中具有优势:
1)假定在WHERE子句中频繁使用下面的条件:order_status_id = 1 和order_date = ‘dd-mon-yyyy’。如果为每一列创建一个索引,那么为了搜索列的值,两个索引都要被读取,但是如果为两列都创建一个复合索引,那么只有一个索引 被读取,这样无疑比两个索引要求更少的I/O。
2) 使用前面例子中同样的条件,如果创建一个复合索引,将更快地检索行,因为你正在排除了所有order_status_id 不是1的行,从而减少了搜索order_date的行数。
(4)反向索引
B*树索引的另一个特点是能够将索引键“反转”。首先,你可以问问自己“为什么想这么做?” B*树索引是为特定的环境、特定的问题而设计的。实现B*树索引的目的是为了减少“右侧”索引中对索引叶子块的竞争,比如在一个Oracle RAC 环境中,某些列用一个序列值或时间戳填充,这些列上建立的索引就属于“右侧”(right-hand-side)索引。
RAC 是一种Oracle 配置,其中多个实例可以装载和打开同一个数据库。如果两个实例需要同时修改同一个数据块,它们会通过一个硬件互连(interconnect)来回传递这 个块来实现共享,互连是两个(或多个)机器之间的一条专用网络连接。如果某个利用一个序列填充,这个列上有一个主键索引 ,那么每个人插入新值时,都会视图修改目前索引结构右侧的左块(见本文图一,其中显示出索引中较高的值都放在右侧,而较低的值放在左侧)。如果对用序列填 充的列上的索引进行修改,就会聚集在很少的一组叶子块上。倘若将索引的键反转,对索引进行插入时,就能在索引中的所有叶子键上分布开(不过这往往会使索引 不能得到充分地填充)。
反向索引是B*Tree索引的一个分支,它的设计是为了运用在某些特定的环境下的。Oracle推出它的主要目的就是为了降低在并行服务器(Oracle Parallel Server)环境下索引叶块的争用。当B*Tree索引中有一列是由递增的序列号产生的话,那么这些索引信息基本上分布在同一个叶块,当用户修改或访问相似的列时,索引块很容易产生争用。反向索引中的索引码将会被分布到各个索引块中,减少了争用。反向索引反转了索引码中每列的字节,通过dump()函数我们可以清楚得看见它做了什么。举个例子:1,2,3三个连续的数,用dump()函数看它们在Oracle内部的表示方法。
SQL> select 'number',dump(1,16) from dual union all
select 'number',dump(2,16) from dual union all
select 'number',dump(3,16) from dual;
'NUMBE DUMP(1,16)
------ -----------------
number Typ=2 Len=2: c1,2 (1)
number Typ=2 Len=2: c1,3 (2)
number Typ=2 Len=2: c1,4 (3)
再对比一下反向以后的情况:
SQL> select 'number',dump(reverse(1),16) from dual union all
select 'number',dump(reverse(2),16) from dual union all
select 'number',dump(reverse(3),16) from dual;
'NUMBE DUMP(REVERSE(1),1
------ -----------------
number Typ=2 Len=2: 2,c1 (1)
number Typ=2 Len=2: 3,c1 (2)
number Typ=2 Len=2: 4,c1 (3)
我们发现索引码的结构整个颠倒过来了,这样1,2,3个索引码基本上不会出现在同一个叶块里,所以减少了争用。不过反向索引又一个缺点就是不能在所有使用常规索引的地方使用。在范围搜索中其不能被使用,例如,where column>value,因为在索引的叶块中索引码没有分类,所以不能通过搜索相邻叶块完成区域扫描。(理解起来比较费劲啊,RAC,什么时候才有时间学啊!)
(5)降序索引
降序索引(descending index)是oracle 8i引入的,用以扩展B*树索引的功能,它允许在索引中以降序(从大到小的顺序)存储一列。在oracle8i及以上版本中,DESC关键字确实会改变创建和使用索引的的方式。
(6)函数索引
基于函数的索引也是8i以来的新产物,它有索引计算列的能力,它易于使用并且提供计算好的值,在不修改应用程序的逻辑上提高了查询性能。
总结:索引使用场合及建议
(1)B*Tree索引。
常规索引,多用于oltp系统,快速定位行,应建立于高cardinality列(即列的唯一值除以行数为一个很大的值,存在很少的相同值)。
(2)反向索引。
B*Tree的衍生产物,应用于特殊场合,在ops环境加序列增加的列上建立,不适合做区域扫描。
(3)降序索引。
B*Tree的衍生产物,应用于有降序排列的搜索语句中,索引中储存了降序排列的索引码,提供了快速的降序搜索。
(4)位图索引。
位图方式管理的索引,适用于OLAP(在线分析)和DSS(决策处理)系统,应建立于低cardinality列,适合集中读取,不适合插入和修改,提供比B*Tree索引更节省的空间。
(5)函数索引。
B*Tree的衍生产物,应用于查询语句条件列上包含函数的情况,索引中储存了经过函数计算的索引码值。可以在不修改应用程序的基础上能提高查询效率。
SQL SERVER 索引学了个概念,把ORACLE的索引又重新温习了一遍,更加理解是一些,不知道SQL SERVER有没有更深入的文章。寻找。。。