图像抠图算法学习 - Shared Sampling for Real-Time Alpha Matting
http://blog.csdn.net/laviewpbt/article/details/19218529
一、序言
陆陆续续的如果累计起来,我估计至少有二十来位左右的朋友加我QQ,向我咨询有关抠图方面的算法,可惜的是,我对这方面之前一直是没有研究过的。除了利用和Photoshop中的魔棒一样的技术或者Photoshop中的选区菜单中的色彩范围类似的算法(这两个我有何PS至少90%一致的代码)是实现简单的抠图外,现在一些state of art 方面的算法我都不了解。因此,也浪费了不少的将知识转换为资产的机会。年30那天,偶然的一个机会,有位朋友推荐我看了一篇关于抠图的文章,并有配套的实现代码,于是我就决定从这篇文章开始我的抠图算法研究之旅。
这篇文章就是Shared Sampling for Real-Time Alpha Matting,关于这篇文章的一些信息,可以在这个网站里找到很多:http://www.inf.ufrgs.br/~eslgastal/SharedMatting/,配套的一个代码在CSDN中可以下载,具体见:http://download.csdn.net/detail/jlwyc/4676516
这篇文章的标题很具有吸引力,发表日期为2010,也算是比较新的。在大家继续看下去之前,我要提醒的是,这里的Real - Time有比较多的限制:主要是(1)必须依赖于强劲的GPU;(2)应用的抠图场合的背景应该比较简单。
不管如何,因为有配套的实现代码,作为起步的研究来说,该文还是算不错的。
从目前流行的抠图技术来看,这篇文章的思路算是比较落伍的一种。
二、技术细节
好了,不管那么多,我先贴些论文中的公式及一些说明将文章的主体细路描述一下。
简单的说,抠图问题就是要解决如下的一个超级病态的方程:
![]()
式中:Cp是我们观察到的图像的颜色,FP、BP、αp均是未知量,可分别称之为前景、背景及透明度。
要解决这样的一个病态的方程,就必须给其增加一些附加的约束,通常,这种约束可以是和待分割图像同等大小的TriMap或者是用户收工划定的scribbles的形式存在,如下两图所示(如未特别说明,一般白色部分表示前景,黑色表示背景,灰色表示待识别的部分):


TriMap scribbles
这样的约束条件使得我们知道了那一部分是明确属于前景(αp=1),而那一部分是属于背景(αp=0),那么下面的主要任务就是搞定那些未知区域的αp值 。
按照论文的说法,在2010年前后解决matting问题的主要方法是基于sampling, pixel affinities 或者两者的结合,特别是后两种是主流的方式。但是这两种都需要求解一个大型的线性系统,这个系统的大小和未知点的个数成正比(我简单看了下closed form那篇抠图文档的代码,就用到了一个庞大的稀疏矩阵),因此对于1MB左右大小的图,求解时间在几秒到几分钟不等。这篇论文提出的算法应该说是基于sampling技术的,他充分利用了相邻像素之间的相似性,并利用了算法内在的并行性,结合GPU编程,实现抠图的实时展示。
总的来说,论文提出的算法可以分成4个步骤:
第一步:Expansion,针对用户的输入,对已知区域(前景或背景)进行小规模的扩展;
第二步:Sample and Gather,对剩余的未知区域内的每个点按一定的规则取样,并选择出最佳的一对前景和背景取样点;
第三步:Refinement,在一定的领域范围内,对未知区域内的每个点的最佳配对重新进行组合。
第四步:Local Smoothing,对得到的前景和背景对以及透明度值进行局部平滑,以减少噪音。
2.1 Expansion
这一步,按照我的经验,可以不做,他唯一的作用就是减少未知点的个数,可能在一定程度上减小后期的计算量,原理也很简单,就是对一个未知点,在其一定的邻域半径内(文中推荐值10,
并且是圆形半径),如果有已知的背景点或前景点,则计算其颜色和这些已知点颜色的距离,然后把这个未知点归属于和其颜色距离小于某个值并且最靠近该点的对象(前景或背景)。
在CSDN提供的参考代码中,这一部分的编码其实写的还是很有特色的,他的循环方式不同于我们普通的邻域编码,他是从像素点逐渐向外部循环开来,有点类似左图的这种循环方式(实际上还是有点区别的,实际是上下两行一起处理,在左右两列处理,然后再向外层扩散),这种处理方式的明显好处就是,只要找到某个点颜色距离小于设定的值,就可以停止循环了,因为这个点肯定是第一个符合颜色距离条件又同时符合物理距离最小的要求的。
这一步做不做,最最终的结果又一定的影响,但是他不具有质的影响。
2.2 Sample and Gather
总的来说,这一步是算法的核心部分,也是对结果影响最大的,他的步骤说起来其实也很简单,我们先看下图。
在这个图中,P和q点都是未知区域,我们需要通过一定的原则在已知区域为其取得一定的样本对,论文中提出的提取方法是: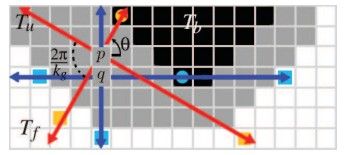
设定一个参数Kg,其意义为一个点最多可能取样的前景点和背景点的个数,也就意味着最多的取样对为Kg*Kg组,通常这个值可以取为4或者更多,论文建议取4就可以了,越大则程序越耗时。
这样对于每个未知点,从该点出发,引出Kg条路径,每个路径之间成360/Kg的夹角,记录下每条路径经过的路线中首次遇到的前景或背景点,直到超出图像的边缘。
为了算法的稳定性,每3*3的矩形区域内(4*4或者5*5也没说不可以的),路径的起始角度周期性的改变,这样相邻像素的Kg条路径经过的区域就有着较大的不同能得到更为有效的结果集。
由上图可以看到,在不少情况下,未知点的前景和背景取样数并不能达到Kg个,甚至极端情况下,找不到任何一个取样点,这样该点就无法进行透明度的计算了,这就要靠后面的过程了。

前景取样点数量分布 背景取样点数量分布 前景+背景取样点数量分布
上图绘制了前面列举的TriMap图中未知区域每个部位的取样点数量分布情况,颜色越靠近白色,表明取样点的数量越大,从图中可以明显看出,处于图像角落的一些未知点取样情况并不是特别理想,但基本上未出现没有取到样的情况,那我们在来看看scribbles那张图的结果。

前景取样点数量分布 背景取样点数量分布 前景+背景取样点数量分布
特别是前景取样分布的结果似乎不太令人满意,有些部分取样数为0了,这个问题下面还会谈到。
在完成取样计算后,我们就需要找出这些取样点中那些是最佳的组合,这个时候就涉及到一般优化时常谈到的目标函数了,在这篇论文中,对目标函数用了四个小函数的乘积来计算,分别如下:
1: 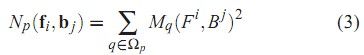
其中
为了全面,我们将上式中αp的计算公式列出: 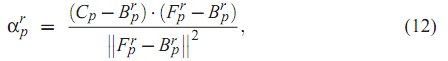
公式(2)的道理很为明显,用一对F/B算出的α值如果很合理的话,那么用α结合F/B重新计算出的颜色应该和原始颜色的差距很小。公式(3)在表明在一定的领域内,由于像素一般不会有突变,差值的平均值也应该很小。
为方便理解,我贴出计算α的部分代码:
/// <summary> /// 通过当前点、前景点以及背景点的颜色值计算对应的Alpha值,对应论文的公式(12)。 /// </summary> /// <param name="BC、GC、RC">当前点的BGR颜色分量值。</param> /// <param name="BF、GF、RF">前景点的BGR颜色分量值。</param> /// <param name="BF、GF、RF">背景点的BGR颜色分量值。</param> /// <remarks>Alpha会出现不在[0,1]区间的情况,因此需要抑制。</remarks> double CalcAlpha(int BC, int GC, int RC, int BF, int GF, int RF, int BB, int GB, int RB) { double Alpha =(double) ((BC - BB) * (BF - BB) + (GC - GB) * (GF - GB) + (RC - RB) * (RF - RB)) / ((BF - BB) * (BF - BB) + (GF - GB) * (GF - GB) + (RF - RB) * (RF - RB) + 0.0000001); // 这里0.0000001换成Eps在LocalSmooth阶段似乎就不对了,有反常的噪点产生 if (Alpha > 1) Alpha = 1; else if (Alpha < 0) Alpha = 0; return Alpha; }
2: 作者考虑在未知点到取样的前景和背景点之间的直线路径上,应该尽量要少有像素的突变,比如如果这条路径需要经过图像的边缘区域,则应该设计一个函数使得该函数的返回值较大,于是作者使用了下面的公式:
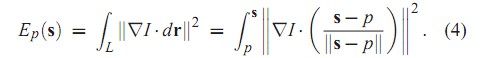
上式即沿着路径对像素颜色进行积分,离散化后也就是一些累加,CSDN的提供的代码在这个函数的处理过程中是有错误的,因为他最后一个判断条件使得循环只会进行一次,有兴趣的朋友可以自己去改改。
按照公式(4)的意义,一个未知点属于前景的可能性可由下式表示:
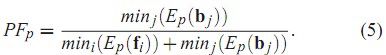 、
、
而一个好的组合也应该最小化下式:
3、未知点和前景点之间的物理距离,一个好的组合中的前景点应该要尽量靠近未知点;
4、未知点和背景点之间的物理距离,一个好的组合中的背景点也应该要尽量靠近未知点;
将这四个条件组合起来,最终得到如下的目标函数:
各子项的指数数据可详见论文本身。
按照这个要求,对前面进行取样得到数据进行处理,并记录下使上式最小的那一对组合,就初步确定了最佳的取样点。
其实,这个时候我们也就可以初步获得处理后的α值了,比如对于我们前面所说的Trimap,其原始图像及经过sample和gather处理后的结果如下图:


从处理结果看,已经可以粗略的得到处理的效果了。
2.3、Refinement
初步的gather处理后,正如前文所说,得到的结果还不够细腻,并且有些未知点由于采样的过程未收集到有效的前景和背景数据,造成该点无法进行处理,因此,在Refinement阶段需要进一步解决这个问题。
论文提出,首先,在一定的邻域内,比如半径为5的领域内,首先统计出公式(2)对应的MP值最小的3个点相关颜色数据,并对这些数据进行加权平均,得到数据对:
然后按照下面这些公式计算新的前景、背景、透明度及可信度的计算。
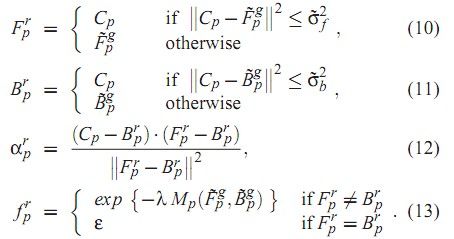
可信度的计算是为下一步的局部平滑做准备的,他反应了我们在这一步确定的取样点是否合理程度的一个度量,经由此步骤,我们可得到的透明度和合成图如下所示:

可见在这一步得到的结果对于上图来说已经相当完美了。
2.4 Local Smoothing
这一步说实在的我没有花太多的精力去看,他的实现过程大概有点类似于高斯模糊,但里面多了很多其他方面的处理,一个很好的事情就是在CSDN提供的代码中对这部分每个公式的实现都是正确的,也是完整的,因此,有兴趣的朋友需要自己多看下论文和对应的代码了。
三、算法的效果
按照论文提供的相关资料集我自己搜集的一些图及配套的Trimap测试了该算法的一些结果,现贴出如下所示:











原图 Trimap 合成后的效果图
可见,对于这些Trimap图,在很多情况下是能获得较为满意的效果的。
我还找了一些简单的图,使用scribble的方式进行处理,效果如下所示:










原图 操作界面 结果图
我选的这些都是背景比较简单的图,因此还能获得较为理想的效果,如果是比较复杂的图,使用scribble是基本上获取不到很理想的效果的,除非人工仔细的划分边界。
四、编程实现
在编程实现方面,CSDN提供的那个代码基本的意思已经达到了,并且里面的函数意义也非常清晰,只不过他使用的opencv的库的,相信专心去研究抠图的人,把他改成其他语言也不是个难题,比如里面用到的vector在C#中就可以用list代替,那些Opencv的结构体也可以在C#中重新定义。
不过那个代码占用的内存非常厉害,这主要是由于VECTOR等数据类型决定的,实际上这里完全可以用数组来搞定的。
我贴一部分代码大家看看:
/// <summary> /// 对每个未知区域的像素按设定的循环角度搜索有效的前景和背景取样点 /// </summary> /// <param name="X">未知区域的X坐标。</param> /// <param name="Y">未知区域的Y坐标。</param> /// <param name="F">用于保存前景点的内存区域。</param> /// <param name="B">用于保存背景点的内存区域。</param> /// <param name="CountF">最终获取的前景点的数量。</param> /// <param name="CountB">最终获取的背景点的数量。</param> /// <remarks>对于有些点,是有可能获取不到有效的点的。</remarks> void Sample(int X, int Y, Point *F, Point *B, int &CountF, int &CountB) { int Z, XX, YY, Alpha; bool F1, F2; double InitAngle, IncAngle, Angle; double Dx, Dy, Step, Value, XD, YD, StepX, StepY; IncAngle = 360 / KG; // 每次扫描增加的角度 InitAngle = (Y % 5 * 5 + X % 25) * IncAngle / 25; // 起始角度,范围在[0,IncAngle]之间,按照3*3的方式轮流替换,有利于提供结果的稳定性,如果KG取值较大,也可以使用4*4或者5*5 CountF = 0; CountB = 0; // 起步时需要记为0,注意参数中的引用(&) for (Z = 0; Z < KG; Z++) { F1 = false; F2 = false; // 开始寻找,暂时未找到任何前景点和背景点 Angle = (InitAngle + Z * IncAngle) / 180.0f * 3.1415926f; // 每次搜索的角度 Dx = cos(Angle); Dy = sin(Angle); Step = min(1.0f / (abs(Dx) + 1e-10), 1.0f / (abs(Dy) + 1e-10)); XD = X + 0.5; YD = Y + 0.5; // +0.5使用于int四舍五入取整,相当于其他语言的round函数 StepX = Step * Dx ; StepY = Step * Dy ; // StepX和StepY中必然有一个为1,另外一个小于1,这样保证每次搜索的像素点都会不同,一个好的建议是加大这个循环步长 // 这样有两个好处。1:加快查找速度;2:让搜索点可以进入已知点的内部,从而避免了只从已知点的边缘取样。但如果已知点的区域狭长,可能丢失有效取样点。 for (; ;) { XX = int(XD); if (XX < 0 || XX >= Width) break; // 已经超出了图像的边界了,结束循环 YY = int(YD); if (YY < 0 || YY >= Height) break; XD += StepX; YD += StepY; Alpha = Mask[YY * MaskStride + XX]; // 得到路径中该点的特征值(前景/背景/未知) if (F1 == false && Alpha == 0) // 如果沿这条路径尚未找到背景点,并且改点具有背景点的特征,则记录下改点到背景点序列中 { B[CountB].X = XX; // 背景点的X坐标 B[CountB].Y = YY; // 背景点的Y坐标 CountB++; // 背景点数量增加1 F1 = true; // 在此路径已经找到了背景点,不用再找背景点了。 } else if (F2 == false && Alpha == 255) // 如果沿这条路径尚未找到前景点,并且改点具有前景点的特征,则记录下改点到前景点序列中 { F[CountF].X = XX; // 前景点的X坐标 F[CountF].Y = YY; // 前景点的X坐标 CountF++; // 前景点数量增加1 F2 = true; // 在此路径已经找到了前景点,不用再找前景点了。 } else if (F1 == true && F2 == true) // 如果前景点和背景点都已经找到了,则结束循环 { break; } } } }
通过以上的Sample代码,我们就可以避免使用Vector之类的数据结构了,速度和内存占用都会得到改进。
然后在Gather阶段的代码改成如下的方式。
void Gathering() { int X, Y, K, L, Index, Speed; int CountF, CountB, Fx, Fy, Bx, By; double Pfp, Min, Dpf, Gp; bool Flag; Point *F = (Point *) malloc(KG * sizeof(Point)); // 采用这种方式占用的内存小很多 Point *B = (Point *) malloc(KG * sizeof(Point)); for (Y = 0; Y < Height; Y++) { Index = Y * MaskStride; for (X = 0; X < Width; X++) { tuple[Index].Flag = -1; // 先都设置为无效的点 if (Mask[Index] != 0 && Mask[Index] != 255) // 只处理未知点 { Sample(X, Y, F, B, CountF, CountB); // 对当前点进行前景和背景取样 Pfp = CalcPFP(X, Y, F, B, CountF, CountB); // 计算公式(5),因为公式(5)只于前景和背景取样点的整体有关,无需放到下面的循环内部 Min = 1e100; Flag = false; for (K = 0; K < CountF; K++) // 对于每一个前景点 { Dpf = CalcDp(X, Y, F[K].X, F[K].Y, true); // 计算前景点到中心点的欧式距离 for (L = 0; L < CountB; L++) // 对于每一个背景点 { Gp = CalcGp(X, Y, F[K].X, F[K].Y, B[L].X, B[L].Y, Pfp, Dpf); // 按照公式(7)计算目标函数 if (Gp < Min) { Min = Gp; Fx = F[K].X; Fy = F[K].Y; // 记录下目标函数为最小值处的前景和背景点的坐标 Bx = B[L].X; By = B[L].Y; Flag = true; } } } if (Flag == true) // 说明找到了最好的组合了,如果找不到,则原因可能是:(1)Sample过程为找到任何有效的前景和背景点;(2)Sample过程只找到前景点或只找到背景点 { // 某个点找不到也不用怕,可能在下面的Refine过程中(其算法为领域处理)得以弥补。 Speed = Fy * Stride + Fx * 3; // 记录下最佳前景点的颜色值 tuple[Index].BF = ImageData[Speed]; tuple[Index].GF = ImageData[Speed + 1]; tuple[Index].RF = ImageData[Speed + 2]; Speed = By * Stride + Bx * 3; tuple[Index].BB = ImageData[Speed]; // 记录下最佳背景点的颜色值 tuple[Index].GB = ImageData[Speed + 1]; tuple[Index].RB = ImageData[Speed + 2]; tuple[Index].SigmaF = CaclSigma(Fx, Fy); // 计算前景点周边像素的均方差值 tuple[Index].SigmaB = CaclSigma(Bx, By); // 计算背景点周边像素的均方差值 tuple[Index].Flag = 1; // 这个像素是个有效的处理点 } } Index++; } } free(F); free(B); }
由于CSDN提供了代码,其他的代码我这里就不提供了。
五、算法的缺陷
以下内容纯属个人意见,请各位阅读的朋友根据自己的知识去判断。
1、Sample过程存在潜在的问题:论文的图2阐述了对某点进行取样的操作过程,这个过程在第一次遇到前景或背景点时就把该点视为前景或背景的一个取样点。这样的话所有的取样点的数据都只可能取在Trimap或者scripple图的前景和背景区域的边缘处。如果边缘处的像素和内部的有很大的区别,显然会出现部分取样点取到的数据很不合理,从而导致最终的透明度信息错误。一种可行的方案就是在Sample的过程中修改每次取样的步长,比如,下面的方式:
StepX = Step * Dx * 10 ; StepY = Step * Dy * 10 ;
即每次沿X或者Y方向移动10个像素,这样就会使得取样点会进入已知区域内部最多10个像素左右,同时也会加速取样的速度。
不过这样做也隐形的带来一个新的问题,即有可能会丢失一些取样点,当已知点的宽度小于10像素时出现这种情况。
2、还是会存在某些点无法获取有效的取样点的,即使有了refine过程。
3、算法的复杂度还是很高,虽然整体的并行性很好,如果没有GPU参与,纯CPU实现起来一样很吃力。
六、效果验证
我用C写了个DLL,并提供了三个示例程序,给有兴趣的朋友测试下效果: http://files.cnblogs.com/Imageshop/SharedMatting.rar
