深入浅出React(一):React的设计哲学 - 简单之美
编者按:自2013年Facebook发布以来,React吸引了越来越多的开发者,基于它的衍生技术,如React Native、React Canvas等也层出不穷。InfoQ精心策划“深入浅出React”系列文章,为读者剖析React开发的技术细节。
React最初来自Facebook内部的广告系统项目,项目实施过程中前端开发遇到了巨大挑战,代码变得越来越臃肿且混乱不堪,难以维护。于是痛定思痛,他们决定抛开很多所谓的“最佳实践”,重新思考前端界面的构建方式,于是就有了React。
React带来了很多开创性的思路来构建前端界面,虽然选择React的最重要原因之一是性能,但是相关技术背后的设计思想更值得我们去思考。之前我也曾写过一篇React的入门文章,并提供了示例代码,大家可以结合参考。
上个月React发布了最新的0.13版,并提供了对ES6的支持。在新版本中,一个小小的改变是React取消了函数的自动绑定,也就是说,以前可以这样去绑定一个事件:
<button onClick={this.handleSubmit}>Submit</button>
而在以ES6语法定义的组件中,必须写为:
<button onClick={this.handleSubmit.bind(this)}>Submit</button>
了解前端开发和JavaScript的同学都知道,做事件绑定时我们需要通过bind(或类似函数)来实现一个闭包以让事件处理函数自带上下文信息,这是由JavaScript语言特性决定的。而在0.13版本之前,React会自动在初始化时对组件的每一个方法做一次这样的绑定,类似于this.func = this.func.bind(this),这样在JSX的事件绑定中就可以直接写为onClick={this.handleSubmit}。
表面上看自动绑定给开发带来了便利,而Facebook却认为这破坏了JavaScript的语言习惯,其背后的神奇(Magic)逻辑或许会给初学者带来困惑,甚至开发者如果从React再转到其它库也可能会无所适从。基于同样的理由,React还取消了对mixin的支持,基于ES6的React组件不再能够以mixin的形式进行代码复用或者扩展。尽管这带来了很大不便,但Facebook认为mixin增加了代码的不可预测性,无法直观的去理解。关于mixin的思考,还可以参考这篇文章。
以简单直观、符合习惯的(idiomatic)方式去编程,让代码更容易被理解,从而易于维护和不断演进。这正是React的设计哲学。
编写可预测,符合习惯的代码
所谓可预测(predictable),即容易理解的代码。在年初的React开发者大会上,React项目经理Tom Occhino进一步阐述React诞生的初衷,在演讲中提到,React最大的价值究竟是什么?是高性能虚拟DOM、服务器端Render、封装过的事件机制、还是完善的错误提示信息?尽管每一点都足以重要。但他指出,其实React最有价值的是声明式的,直观的编程方式。
软件工程向来不提倡用高深莫测的技巧去编程,相反,如何写出可理解可维护的代码才是质量和效率的关键。试想,一个月之后你回头看你写的代码,是否一眼就明白某个变量,某个if判断的含义;一个新加入的同事想去增加一个小小的新功能或是修复某个Bug,他是否对自己的代码有足够的信心不引入任何副作用?随着功能的增加,代码很容易变得越来越复杂,这些问题也将越来越严重,最终导致一份难以维护的代码。而React号称,新同事甚至在加入的第一天就能开始开发新功能。
那么React是如何做的呢?
使用JSX直观的定义用户界面
JSX是React的核心组成部分,它使用XML标记的方式去直接声明界面,界面组件之间可以互相嵌套。但是JSX给人的第一印象却是相当“丑陋”。当下面这样的例子被第一次展示的时候,甚至很多人称之为“巨大的退步(Huge Step Backwards)”:
var React = require(‘React’);
var message =
<div class=“hello” onClick={someFunc}>
<span>Hello World</span>
</div>;
React.renderComponent(message, document.body);
将HTML直接嵌入到JavaScript代码中看上去确实是一件足够疯狂的事情。人们花了多年时间总结出的界面和业务逻辑相互分离的“最佳实践”就这么被彻底打破。那么React为何要如此另类?
模板出现的初衷是让非开发人员也能对界面做一定的修改。但这个初衷在当前Web程序里已完全不适用,每个模板背后的代码逻辑严重依赖模板中的内容和DOM结构,两者是紧密耦合的。即使做到文件位置的分离,实际上两者还是一体的,并且为了两者之间的协作而不得不引入很多机制和概念。以Angularjs的首页示例代码为例:
<ul class="unstyled">
<li ng-repeat="todo in todoList.todos">
<input type="checkbox" ng-model="todo.done">
<span class="done-{{todo.done}}">{{todo.text}}</span>
</li>
</ul>
尽管我们很容易看懂这一小段模板的含义,但你却无法开始写这样的代码,因为你需要学习这一整套语法。比如说,你得知道有ng-repeat这样的标记的准确含义,其中的”todo in todoList.todos”看上去是repeat语法的一部分,或许还有其它语法存在;可以看到有{{todo.text}}这样的数据绑定,那么如果要对这段文本格式化(加一个formatter)该怎么做;另外,ng-model背后又需要什么样的数据结构?
现在来看React怎么写这段逻辑:
//...
render: function () {
var lis = this.todoList.todos.map(function (todo) {
return (
<li>
<input type="checkbox" checked={todo.done}>
<span className="done-{todo.done}">{todo.text}</span>
</li>);
});
return (
<ul class="unstyled">
{lis}
</ul>
);
}
//...
可以看到,JSX中除了另类的HTML标记之外,并没有引入其它任何新的概念(事实上HTML标记也可以完全用JavaScript去写)。Angular中的repeat在这里被一个简单的数组方法map所替代。在这里你可以利用熟悉的JavaScript语法去定义界面,在你的思维过程中其实已经不需要存在模板的概念,需要考虑的仅仅是如何用代码构建整个界面。这种自然而直观的方式直接降低了React的学习门槛并且让代码更容易理解。
简化的组件模型:所谓组件,其实就是状态机器
组件并不是一个新的概念,它意味着某个独立功能或界面的封装,达到复用、或是业务逻辑分离的目的。而React却这样理解界面组件:
所谓组件,就是状态机器
React将用户界面看做简单的状态机器。当组件处于某个状态时,那么就输出这个状态对应的界面。通过这种方式,就很容易去保证界面的一致性。
在React中,你简单的去更新某个组件的状态,然后输出基于新状态的整个界面。React负责以最高效的方式去比较两个界面并更新DOM树。
这种组件模型简化了我们思考的方式:对组件的管理就是对状态的管理。不同于其它框架模型,React组件很少需要暴露组件方法和外部交互。例如,某个组件有只读和编辑两个状态。一般的思路可能是提供beginEditing()和endEditing()这样的方法来实现切换;而在React中,需要做的是setState({editing: true/false})。在组件的输出逻辑中负责正确展现当前状态。这种方式,你不需要考虑beginEditing和endEditing中应该怎样更新UI,而只需要考虑在某个状态下,UI是怎样的。显然后者更加自然和直观。
组件是React中构建用户界面的基本单位。它们和外界的交互除了状态(state)之外,还有就是属性(props)。事实上,状态更多的是一个组件内部去自己维护,而属性则由外部在初始化这个组件时传递进来(一般是组件需要管理的数据)。React认为属性应该是只读的,一旦赋值过去后就不应该变化。关于状态和属性的使用在后续文章中还会深入探讨。
每一次界面变化都是整体刷新
数据模型驱动UI界面的两层编程模型从概念角度看上去是直观的,而在实际开发中却困难重重。一个数据模型的变化可能导致分散在界面多个角落的UI同时发生变化。界面越复杂,这种数据和界面的一致性越难维护。在Facebook内部他们称之为“Cascading Updates”,即层叠式更新,意味着UI界面之间会有一种互相依赖的关系。开发者为了维护这种依赖更新,有时不得不触发大范围的界面刷新,而其中很多并不真的需要。React的初衷之一就是,既然整体刷新一定能解决层叠更新的问题,那我们为什么不索性就每次都这么做呢?让框架自身去解决哪些局部UI需要更新的问题。这听上去非常有挑战,但React却做到了,实现途径就是通过虚拟DOM(Virtual DOM)。
关于虚拟DOM的原理我在去年底的文章有过比较详细的介绍,这里不再重复。简而言之就是,UI界面是一棵DOM树,对应的我们创建一个全局唯一的数据模型,每次数据模型有任何变化,都将整个数据模型应用到UI DOM树上,由React来负责去更新需要更新的界面部分。事实证明,这种方式不但简化了开发逻辑并且极大的提高了性能。
以这种思路出发,我们在考虑不断变化的UI界面时,仅仅需要整体考虑UI的构成。编程模型的简化带来的是代码的精简和易于理解,也即React不断提到的可预测(Predictable)的代码,代码的功能一目了然易于理解。Tom Occhino在2015 React开发者大会上也分享了React在Facebook内部的应用案例,随着新功能被不断的添加到系统中,开发进度非但没有变慢,甚至越来越快。
单向数据流动:Flux
既然已经有了组件机制去定义界面,那么还需要一定的机制来定义组件之间,以及组件和数据模型之间如何通信。为此,Facebook提出了Flux框架用于管理数据流。Flux是一个相当宽松的概念框架,同样符合React简单直观的原则。不同于其它大多数MVC框架的双向数据绑定,Flux提倡的是单向数据流动,即永远只有从模型到视图的数据流动。
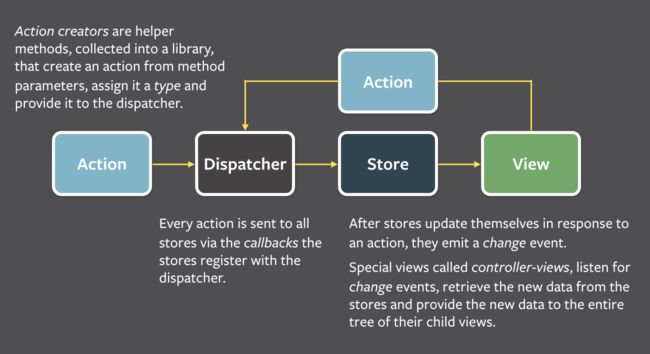
Flux引入了Dispatcher和Action的概念:Dispatcher是一个全局的分发器负责接收Action,而Store可以在Dispatcher上监听到Action并做出相应的操作。简单的理解可以认为类似于全局的消息发布订阅模型。Action可以来自于用户的某个界面操作,比如点击提交按钮;也可以来自服务器端的某个数据更新。当数据模型发生变化时,就触发刷新整个界面。
Flux的定义非常宽松,除了Facebook自己的实现之外,社区中还出现了很多Flux的不同实现,各有特点,比较流行的包括Flexible, Reflux, Flummox等等。
让数据模型也变简单:Immutability
Immutability含义是只读数据,React提倡使用只读数据来建立数据模型。这又是一个听上去相当疯狂的机制:所有数据都是只读的,如果需要修改它,那么你只能产生一份包含新的修改的数据。假设有如下数据:
var employee = {
name: ‘John’,
age: 28
};
如果要修改年龄,那么你需要产生一份新的数据:
var updated = {
name: employee.name,
age: 29
};
这样,原来的employee对象并没有发生任何变化,相反,产生了一个新的updated对象,体现了年龄发生了变化。这时候需要把新的updated对象应用到界面组件上来进行界面的更新。
只读数据并不是Facebook的全新发明,而是起源于Clojure, Scala, Haskell等函数式编程语言。只读的数据可以让代码更加的安全和易于维护,你不再需要担心数据在某个角落被某段神奇的代码所修改;也就不必再为了找到修改的地方而苦苦调试。而结合React,只读数据能够让React的组件仅仅通过比较对象引用是否相等来决定自身是否要重新Render。这在复杂的界面上可以极大的提高性能。
针对只读数据,Facebook开发了一整套框架immutable.js,将只读数据的概念引入JavaScript,并且在github开源。如果不希望一开始就引入这样一个较大的框架,React还提供了一个工具类插件,帮助管理和操作只读数据:React.addons.update。
React思想的衍生:React Native, React Canvas等等
在前几天的Facebook F8开发者大会上,React Native终于众望所归的发布,它将React的思想延伸到了原生移动开发。它的口号是“Learn Once, Write Anywhere”,有React开发经验的开发人员将可以无缝的进行React Native开发。无论是组件化的思想,调试工具,动态代码加载等React具有的强大特性都可以应用在React Native。相信这会对以后的移动开发布局产生重要影响。
React对UI层进行了完美的抽象,写Web界面时甚至能够做到完全的去DOM化:开发者可以无需进行任何DOM操作。因此,这也让对UI层进行整体替换成为了可能。React Native正是将浏览器基于DOM的UI层换成了iOS或者Android的原生控件。而Flipboard则将UI层换成了Canvas。
React Canvas是Flipboard出品的一套前端框架,所有的界面元素都通过Canvas来绘制,infoQ之前也有文章对其进行了介绍。Flipboard追求极致的性能和用户体验,因此对浏览器的缓慢DOM操作深恶痛绝,不惜大刀阔斧彻底舍弃了DOM,而完全用Canvas实现了整套UI控件。有兴趣的同学不妨一试。
小结
React并不是突然从哪里蹦出来,而是为了解决前端开发中的痛点而生。以简单为原则设计也决定了React具有极其平缓的学习曲线,开发者可以快速上手并应用到实际项目中。本文总结分析了其相关技术背后的设计思想,希望通过这个角度能让大家对React有一个总体的认识,从而在React的实际项目开发中,遵循简单直观的原则,进行高效率高质量的产品开发。
参考资料
- React官方网站:http://facebook.github.io/react/
- React博客:http://facebook.github.io/react/blog/
- React入门:http://ryanclark.me/getting-started-with-react/
- 颠覆式前端UI框架:React:http://www.infoq.com/cn/articles/subversion-front-end-ui-development-framework-react
- Immutable.js: http://facebook.github.io/immutable-js/
- React Native: http://facebook.github.io/react-native/
- Flux: https://facebook.github.io/flux/
- Flux框架对比:https://github.com/voronianski/flux-comparison
- React开发者大会网站:http://conf.reactjs.com/index.html
- React在Slack上的聊天社区:http://reactiflux.com/
感谢徐川对本文的审校。
转自:http://www.infoq.com/cn/articles/react-art-of-simplity