hadoop2.6.0+eclipse配置
【0】安装前的声明
0.1) 所用节点2个
master : 192.168.119.105 hadoop5
slave : 192.168.119.101 hadoop1
(先用一个slave,跑成功后,在从master分别scp到各个slaves即可】)
0.2) 每个机子的那些个文件需要一样
(或者直接从master直接scp到各个slaves即可)
vim /etc/hosts(主机名和ip地址映射文件)
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.119.101 hadoop1
192.168.119.102 hadoop2
192.168.119.103 hadoop3
192.168.119.104 hadoop4
192.168.119.105 hadoop5
jdk 解压目录
这里统一解压到 /usr/java/jdk
0.3) 所有master和slaves机子的用户名全部是hadoop
注意要用hadoop用户的权限对hadoop的文件配置进行操作
【1】安装JDK
1.1)解开jdk压缩包
tar -zvx -f jdk-7u7-linux-x64.tar.gz (解压缩,-z处理gz, -j 处理 bzip2)
(或许之前,你需要 chmod 755 your_jdk_file)

1.2)配置环境变量
打开/etc/profile,在文件最后输入下面内容

1.3) source /etc/profile
作用:在当前bash环境下读取并执行FileName中的命令。
注:该命令通常用命令“.”来替代。
如:source .bash_rc 与 . .bash_rc 是等效的。
注意:source命令与shell scripts的区别是,
source在当前bash环境下执行命令,而scripts是启动一个子shell来执行命令。这样如果把设置环境变量(或alias等等)的命令写进scripts中,就只会影响子shell,无法改变当前的BASH,所以通过文件(命令列)设置环境变量时,要用source 命令。
1.4 )设置新安装的JDK为默认的JDK

命令行输入如下命令:
sudo update-alternatives –install /usr/bin/java java /usr/java/jdk/bin/java 300
sudo update-alternatives –install /usr/bin/javac javac /usr/java/jdk/bin/javac 300
sudo update-alternatives –config java
(Attention)–install 和 –config 是两个 横线-,
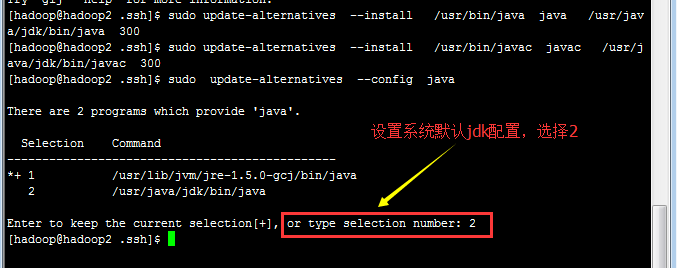
1.5)验证Java是否安装成功
输入 java-version ,输出Java版本信息即为安装成功。

【2】SSH 安装
(google ssh centos 安装
http://www.cnblogs.com/alaska1131/articles/1659654.html)
(以下配图中的文字有错误,改为:
ssh的公私钥建立 输入命令:ssh-keygen 就可以了(其默认的密钥生成方式是rsa) ,
然后三个回车,默认的公私钥就在家目录的.ssh文件夹下了。)
2.1)如何使用ssh
ssh的目的就是使用免密码登陆;
如果在master上,如
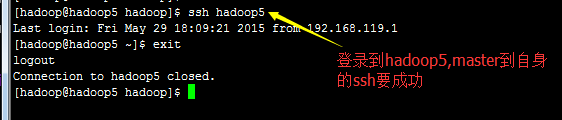
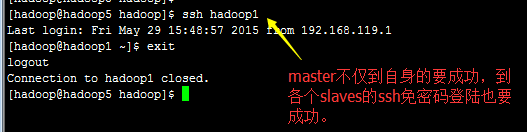
Attention)
A1 ) 当ssh安装后,.ssh 文件夹会自动生成在家目录(如/home/hadoop下),所有机器的.ssh 的访问权限必须是700
A2)在.ssh 下的authorized_keys 的权限 必须是644或者600,
A3)ssh会依据.ssh和authorized_keys的权限来判断是否接受免密码登陆
【3】Hadoop2.6.0 配置
http://blog.csdn.net/caiandyong/article/details/42815221
http://blog.csdn.net/caiandyong/article/details/44925845
3.1)文件配置 (hadoop解压文件所放置的目录,请自行创建)
以下配置文件只需傻瓜式的copy and paste
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop5:9000</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hdfs/hadooptmp</value>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop5:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop5:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop5:19888</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop5</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop5:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop5:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop5:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop5:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop5:8088</value>
</property>
</configuration>vim slaves (有多少个slaves 就写对应的主机名)
hadoop1
hadoop2 (若从master scp到slaves(hadoop2的话))
vim hadoop-env.sh 末尾追加
export JAVA_HOME=/usr/java/jdk
export HADOOP_PREFIX=/home/hadoop/hadoop
【Complementary】
从master(hadoop5) scp hadoop framework到 slave(hadoop2)
1) jump到hadoop5的家目录
2) scp -r hadoop/ hadoop@hadoop2:~/
3) scp -r /usr/java/jdk/ hadoop@hadoop2:~ ;
and then
sudo cp -r ~/jdk /usr/java/;
You Should Know: (when execute scp operation from master to slave)
1) 修改 hadoop/etc/hadoop/slaves 添加hadoop2 这是slave的主机
2) 修改hadoop/etc/hadoop/hdfs-site.xml 将 dfs.replication 修改为2
3.2)格式化hdfs (slave端 不需要此operation)
bin/hdfs namenode -format
3.3)开启所有进程 (slave端 不需要此operation)
sbin/start-all.sh
or 关闭所有进程 sbin/stop-all.sh
3.4) 访问
hdfs的 web页面 http://192.168.119.101:50070/dfshealth.html#tab-overview
hadoop 的 节点 web页面 http://192.168.119.101:8088/cluster/nodes
【Attention】
如果要重新格式化,请吧hdfs的文件夹 namenode,datanode and hadooptmp 文件夹里面的内容清空干净
rm -r * ,然后在重新格式化,启动所有进程,等等。
3.5)最后的效果(缺一不可)
如果scp master(hadoop5)上面的hadoop framwork 到 slave2(hadoop2)上的话,
那么你会看到:
至此,hadoop集群搭建完毕。
3.6) 两个节点的集群启动(补充)
首先,我们用到了一个master(hadoop5)和一个slave(hadoop1),后来,我们又添加了一个slave(hadoop2), 我们看看两个节点的启动效果。
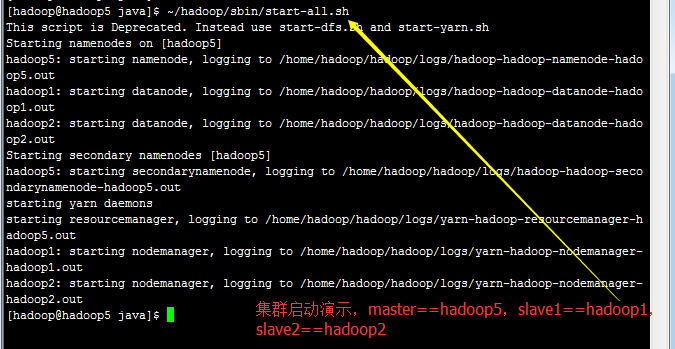


Bingo !
【4】CentOS上安装eclipse IDE工具(只为方便调试java程序) + hadoop 集成
4.1) 下载eclipse 官网
并传送到centos上,推荐使用 lrzsz 这个工具(centos 上安装)
lrzsz 使用实例
安装lrzsz (receive 和 send)
yum install lrzsz
rz r就是receive linux服务器接收。 也就是 windows上传文件。
如图,输入rz会调出一个对话框,可以选择你需要上传的文件

sz r就是Send linux服务器发送。 也就是 windows下载文件。
如图,输入sz 后面接上你需要发送的文件 或文件夹。

4.2) 解压即可,放置到/usr/local/
4.3)下载插件 hadoop-eclipse-plugin-2.6.0.jar

并放置到 /usr/local/eclipse/plugins
4.4) 配置eclipse 和 MapReduce IDE
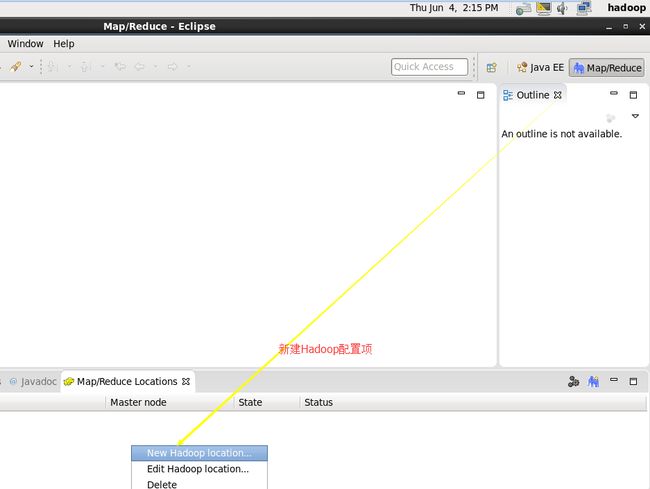
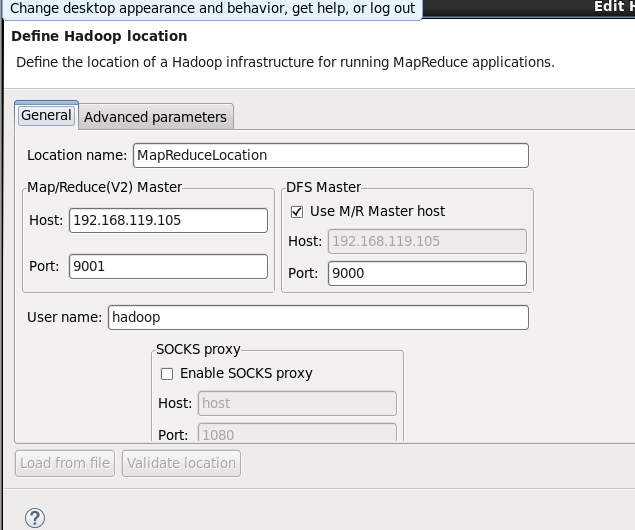
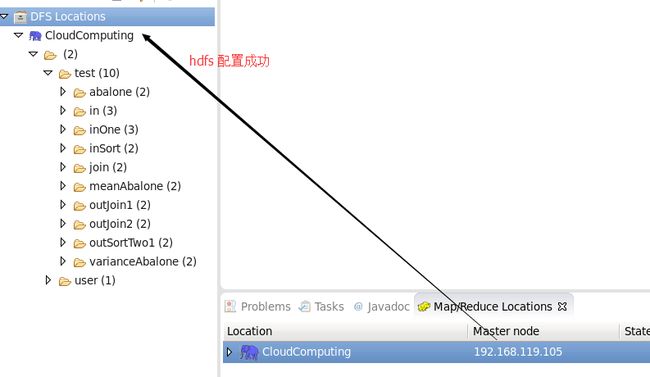

创建项目完成,接下来,你就开始coding吧。