Storm实战之WordCount
在storm环境部署完毕,并正确启动之后,现在就可以真正进入storm开发了,按照惯例,以wordcount作为开始。
这个例子很简单,核心组件包括:一个spout,两个bolt,一个Topology。
spout从一个路径读取文件,然后readLine,向bolt发射,一个文件处理完毕后,重命名,以不再重复处理。
第一个bolt将从spout接收到的字符串按空格split,产生word,发射给下一个bolt。
第二个bolt接收到word后,统计、计数,放到HashMap容器中。
1,定义一个spout,作用是源源不断滴向bolt发射字符串。
2,定义一个bolt,作用是接收spout发过来的字符串,并分割成word,发射给下一个bolt。
3,定义一个bolt,接收word,并统计。
注意
WordCounter类的
prepare方法,里面定义了一个Thread,持续监控容器的变化(word个数增加或者新增word)。
4,定义一个Topology,提交作业。
5,代码完成后,导出jar(导出时不要指定Main class),然后上传至storm集群,通过命令./storm jar com.x.x.WordCountTopo /data/tianzhen/input 2来提交作业。
Topo启动,spout、bolt执行过程:
Thread监控的统计结果:
源文件处理之后被重命名为*.bak。
和Hadoop不同,在任务执行完之后,Topo不会停止,spout会一直监控数据源,不停地往bolt发射数据。
所以现在如果源数据发生变化,应该能够立马体现出来。我往path下再放一个文本文件,结果:
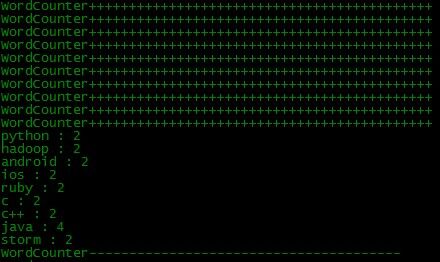
可见,结果立刻更新了,storm的实时性就体现在这里。
这个例子很简单,核心组件包括:一个spout,两个bolt,一个Topology。
spout从一个路径读取文件,然后readLine,向bolt发射,一个文件处理完毕后,重命名,以不再重复处理。
第一个bolt将从spout接收到的字符串按空格split,产生word,发射给下一个bolt。
第二个bolt接收到word后,统计、计数,放到HashMap容器中。
1,定义一个spout,作用是源源不断滴向bolt发射字符串。
点击(此处)折叠或打开
- import java.io.File;
- import java.io.IOException;
- import java.util.Collection;
- import java.util.List;
- import java.util.Map;
-
- import org.apache.commons.io.FileUtils;
- import org.apache.commons.io.filefilter.FileFilterUtils;
-
- import backtype.storm.spout.SpoutOutputCollector;
- import backtype.storm.task.TopologyContext;
- import backtype.storm.topology.OutputFieldsDeclarer;
- import backtype.storm.topology.base.BaseRichSpout;
- import backtype.storm.tuple.Fields;
- import backtype.storm.tuple.Values;
-
- public class WordReader extends BaseRichSpout {
- private static final long serialVersionUID = 2197521792014017918L;
- private String inputPath;
- private SpoutOutputCollector collector;
-
- @Override
- @SuppressWarnings(\"rawtypes\")
- public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
- this.collector = collector;
- inputPath = (String) conf.get(\"INPUT_PATH\");
- }
-
- @Override
- public void nextTuple() {
- Collection<File> files = FileUtils.listFiles(new File(inputPath),
- FileFilterUtils.notFileFilter(FileFilterUtils.suffixFileFilter(\".bak\")), null);
- for (File f : files) {
- try {
- List<String> lines = FileUtils.readLines(f, \"UTF-8\");
- for (String line : lines) {
- collector.emit(new Values(line));
- }
- FileUtils.moveFile(f, new File(f.getPath() + System.currentTimeMillis() + \".bak\"));
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
-
- @Override
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields(\"line\"));
- }
-
- }
2,定义一个bolt,作用是接收spout发过来的字符串,并分割成word,发射给下一个bolt。
点击(此处)折叠或打开
- import org.apache.commons.lang.StringUtils;
-
- import backtype.storm.topology.BasicOutputCollector;
- import backtype.storm.topology.OutputFieldsDeclarer;
- import backtype.storm.topology.base.BaseBasicBolt;
- import backtype.storm.tuple.Fields;
- import backtype.storm.tuple.Tuple;
- import backtype.storm.tuple.Values;
-
- public class WordSpliter extends BaseBasicBolt {
-
- private static final long serialVersionUID = -5653803832498574866L;
-
- @Override
- public void execute(Tuple input, BasicOutputCollector collector) {
- String line = input.getString(0);
- String[] words = line.split(\" \");
- for (String word : words) {
- word = word.trim();
- if (StringUtils.isNotBlank(word)) {
- word = word.toLowerCase();
- collector.emit(new Values(word));
- }
- }
- }
-
- @Override
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields(\"word\"));
-
- }
-
- }
3,定义一个bolt,接收word,并统计。
点击(此处)折叠或打开
- import java.util.HashMap;
- import java.util.Map;
- import java.util.Map.Entry;
-
- import backtype.storm.task.TopologyContext;
- import backtype.storm.topology.BasicOutputCollector;
- import backtype.storm.topology.OutputFieldsDeclarer;
- import backtype.storm.topology.base.BaseBasicBolt;
- import backtype.storm.tuple.Tuple;
-
- public class WordCounter extends BaseBasicBolt {
- private static final long serialVersionUID = 5683648523524179434L;
- private HashMap<String, Integer> counters = new HashMap<String, Integer>();
- private volatile boolean edit = false;
-
- @Override
- @SuppressWarnings(\"rawtypes\")
- public void prepare(Map stormConf, TopologyContext context) {
- final long timeOffset = Long.parseLong(stormConf.get(\"TIME_OFFSET\").toString());
- new Thread(new Runnable() {
- @Override
- public void run() {
- while (true) {
- if (edit) {
- for (Entry<String, Integer> entry : counters.entrySet()) {
- System.out.println(entry.getKey() + \" : \" + entry.getValue());
- }
- System.out.println(\"WordCounter---------------------------------------\");
- edit = false;
- }
- try {
- Thread.sleep(timeOffset * 1000);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }).start();
- }
-
- @Override
- public void execute(Tuple input, BasicOutputCollector collector) {
- String str = input.getString(0);
- if (!counters.containsKey(str)) {
- counters.put(str, 1);
- } else {
- Integer c = counters.get(str) + 1;
- counters.put(str, c);
- }
- edit = true;
- System.out.println(\"WordCounter+++++++++++++++++++++++++++++++++++++++++++\");
- }
-
- @Override
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
-
- }
- }
4,定义一个Topology,提交作业。
点击(此处)折叠或打开
- public class WordCountTopo {
- public static void main(String[] args) {
- if (args.length != 2) {
- System.err.println(\"Usage: inputPaht timeOffset\");
- System.err.println(\"such as : java -jar WordCount.jar D://input/ 2\");
- System.exit(2);
- }
- TopologyBuilder builder = new TopologyBuilder();
- builder.setSpout(\"word-reader\", new WordReader());
- builder.setBolt(\"word-spilter\", new WordSpliter()).shuffleGrouping(\"word-reader\");
- builder.setBolt(\"word-counter\", new WordCounter()).shuffleGrouping(\"word-spilter\");
- String inputPaht = args[0];
- String timeOffset = args[1];
- Config conf = new Config();
- conf.put(\"INPUT_PATH\", inputPaht);
- conf.put(\"TIME_OFFSET\", timeOffset);
- conf.setDebug(false);
- LocalCluster cluster = new LocalCluster();
- cluster.submitTopology(\"WordCount\", conf, builder.createTopology());
- }
- }
5,代码完成后,导出jar(导出时不要指定Main class),然后上传至storm集群,通过命令./storm jar com.x.x.WordCountTopo /data/tianzhen/input 2来提交作业。
Topo启动,spout、bolt执行过程:
Thread监控的统计结果:
源文件处理之后被重命名为*.bak。
和Hadoop不同,在任务执行完之后,Topo不会停止,spout会一直监控数据源,不停地往bolt发射数据。
所以现在如果源数据发生变化,应该能够立马体现出来。我往path下再放一个文本文件,结果:
可见,结果立刻更新了,storm的实时性就体现在这里。