Hadoop 完全分布式集群配置
本文配置的集群有4台机器:
| 主机名 | IP地址 | 角色 |
| node1 | 192.168.161.11 | NameNode JobTracker |
| node2 | 192.168.161.12 | SecondaryNameNode TaskTracker DataNode |
| node3 | 192.168.161.13 | TaskTracker DataNode |
| node4 | 192.168.161.14 | TaskTracker DataNode |
1.配置ssh
在每台机器中命令行运行以下两行代码:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys将生成的公钥放在了~/.ssh/authorized_keys文件中
将node1的authorized_keys拷贝到node2/node3/node4中
scp ~/.ssh/authorized_keys root@node2:~/.ssh/authorized_node1 scp ~/.ssh/authorized_keys root@node3:~/.ssh/authorized_node1 scp ~/.ssh/authorized_keys root@node4:~/.ssh/authorized_node1
cat ~/.ssh/authorized_node1 >> ~/.ssh/authorized_keys
2.Hadoop配置
/conf/hadoop-env.sh
# The java implementation to use. Required. export JAVA_HOME=/csh/link/jdk
<property> <name>fs.default.name</name> <value>hdfs://node1:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/csh/hadoop/tmp</value> </property>
/conf/hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/csh/hadoop/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/csh/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
node2/conf/slaves 【设置 DataNode 和 TaskTracker】
node2 node3 node4
/conf/mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>node1:9001</value>
</property>
将配置文件复制到另外3台机器上
scp /csh/software/hadoop-1.2.1/conf/* root@node2:/csh/software/hadoop-1.2.1/conf/ scp /csh/software/hadoop-1.2.1/conf/* root@node3:/csh/software/hadoop-1.2.1/conf/ scp /csh/software/hadoop-1.2.1/conf/* root@node4:/csh/software/hadoop-1.2.1/conf/
格式化
bin/hadoop namenode -format
bin/start-all.sh
starting namenode, logging to /csh/software/hadoop-1.2.1/libexec/../logs/hadoop-root-namenode-node1.out node4: starting datanode, logging to /csh/software/hadoop-1.2.1/libexec/../logs/hadoop-root-datanode-node4.out node3: starting datanode, logging to /csh/software/hadoop-1.2.1/libexec/../logs/hadoop-root-datanode-node3.out node2: starting datanode, logging to /csh/software/hadoop-1.2.1/libexec/../logs/hadoop-root-datanode-node2.out node2: starting secondarynamenode, logging to /csh/software/hadoop-1.2.1/libexec/../logs/hadoop-root-secondarynamenode-node2.out starting jobtracker, logging to /csh/software/hadoop-1.2.1/libexec/../logs/hadoop-root-jobtracker-node1.out node4: starting tasktracker, logging to /csh/software/hadoop-1.2.1/libexec/../logs/hadoop-root-tasktracker-node4.out node3: starting tasktracker, logging to /csh/software/hadoop-1.2.1/libexec/../logs/hadoop-root-tasktracker-node3.out node2: starting tasktracker, logging to /csh/software/hadoop-1.2.1/libexec/../logs/hadoop-root-tasktracker-node2.out
访问:
HDFS的路径为:http://node1:50070
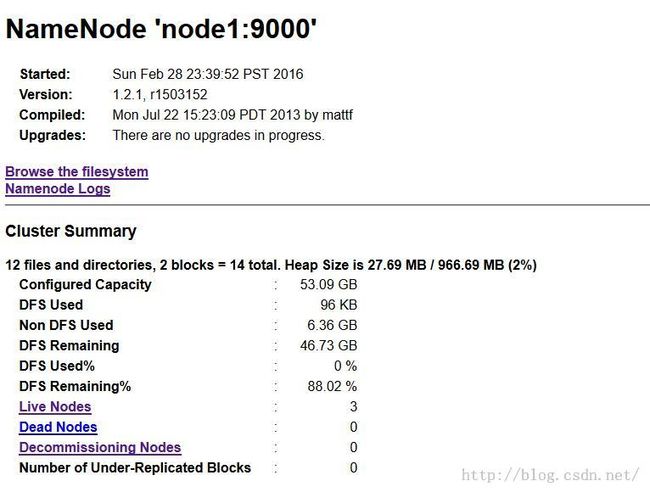
MapReduce的路径为:http://node1:50030

利用jps命令在各节点中查看启动的线程,对应上面的表格
[root@node1 csh]# jps 4817 NameNode 4994 JobTracker 5163 Jps [root@node2 csh]# jps 4164 TaskTracker 4005 DataNode 4295 Jps 4078 SecondaryNameNode [root@node3 csh]# jps 3796 Jps 3589 DataNode 3676 TaskTracker [root@node4 csh]# jps 3700 TaskTracker 3830 Jps 3613 DataNode