最佳调度问题的回溯算法(java实现)
实验目的:
理解回溯法的原理,掌握调度问题的处理方法,实现最佳调度问题的回溯解决。
问题定义
输入:
1. 任务数N
2. 机器数M
3. 随机序列长度t[i],其中t[i]=x表示第i个任务完成需要时间单位x,
输出:
1. 开销时间besttime,表示最佳调度需要时间单位
2. 最佳调度序列bestx[],其中bestx[i]=x,表示将第i个任务分配给第x个机器执行。
实验思想
解空间的表示:
一个深度为N的M叉树。
基本思路:搜索从开始结点(根结点)出发,以DFS搜索整个解空间。
每搜索完一条路径则记录下besttime 和bestx[]序列
开始结点就成为一个活结点,同时也成为当前的扩展结点。在当前的扩展结点处向纵深方向移至一个新结点,并成为一个新的活结点,也成为当前扩展结点。
如果在当前的扩展结点处不能再向纵深方向扩展,则当前扩展结点就成为死结点。
此时,应往回移动(回溯)至最近的一个活结点处,并使这个活结点成为当前的扩展结点;直至找到一个解或全部解。
测试数据及结果
本测试的硬件以及软件环境如下
CPU:PM 1.5G; 内存:768M;操作系统:windows xp sp2;软件平台:JDK1.5;开发环境:eclipse
如图1所示:即为求任务数为10机器数为5的最佳调度的算法结果。
图1
实验结论以及算法分析
通过测试证明算法正确有效。
性能分析的方法:使用JDK 1.5的System.nanoTime(),计算算法消耗的时间,以此来评价算法。(该方法在JDK1.5以下的版本中不支持)
为了不影响算法的准确度,在测试的过程我们注释掉了打印随机字符串的步骤。
由于没有使用限界函数进行优化,算法时间和空间复杂度呈指数级增长。所以该算法不适合较大规模的计算。
图2
图2 蓝线表示任务数一定M=3时,n增大时求解最佳调度对所消耗的时间,该趋势随着指数增加。
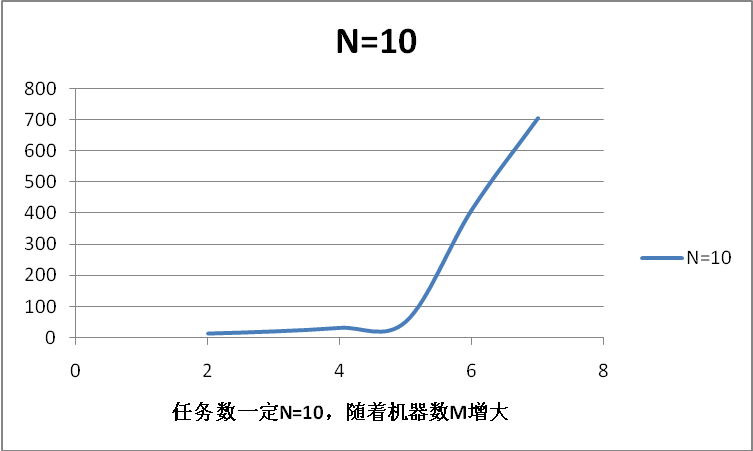
图3
图3表示任务数N一定时随着M的增大的增长曲线。
图2和图3表明该程序的时间复杂度与理论分析相符合。
源代码
最佳调度的回溯算法(java描述)
BestSchedule.Java