python短域名数据分析框架
本文数据源及分析方法均参考《利用python进行数据分析》一书。但我重新对数据分析目标和步骤进行了组织,可以更加清晰的呈现整个挖掘分析流程。
分析对象为美国某短域名网站记录的短域名生成数据(http://1usagov.measuredvoice.com/)。数据基本结构如下,可以看到内容包括所用浏览器和操作系统(’a’)、用户所在时区(’tz’)等信息。
records[0]
#[Out]# {u'a': u'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.78 Safari/535.11',
#[Out]# u'al': u'en-US,en;q=0.8',
#[Out]# u'c': u'US',
#[Out]# u'cy': u'Danvers',
#[Out]# u'g': u'A6qOVH',
#[Out]# u'gr': u'MA',
#[Out]# u'h': u'wfLQtf',
#[Out]# u'hc': 1331822918,
#[Out]# u'hh': u'1.usa.gov',
#[Out]# u'l': u'orofrog',
#[Out]# u'll': [42.576698, -70.954903],
#[Out]# u'nk': 1,
#[Out]# u'r': u'http://www.facebook.com/l/7AQEFzjSi/1.usa.gov/wfLQtf',
#[Out]# u't': 1331923247,
#[Out]# u'tz': u'America/New_York',
#[Out]# u'u': u'http://www.ncbi.nlm.nih.gov/pubmed/22415991'}
分析目标包括:(1)得到各地区用户的数量统计并绘图;(2)得到各地区windows和非windows用户的数量统计并绘图。
针对分析任务1:得到各地区用户的数量统计并绘图
1)从文件读取数据
import pandas as pd from pandas import Series,DataFrame import numpy as np #此处为文件所在路径 path = 'D:\\apython\\usagov_bitly_data2012-03-16-1331923249.txt' import json records = [json.loads(line) for line in open(path)]
2)抽取用户时区信息
df = DataFrame(records)
timezones = df['tz'].fillna("missing")
timezones[timezones == ''] = "unknown"
timezones.head(2)
#[Out]# 0 America/New_York
#[Out]# 1 America/Denver
3)汇总统计时区信息
tz_counts = timezones.value_counts() tz_counts.head(2) #[Out]# America/New_York 1251 #[Out]# unkown 521
4)利用统计信息绘图
top10 = tz_counts[:10] top10.plot(kind='barh')
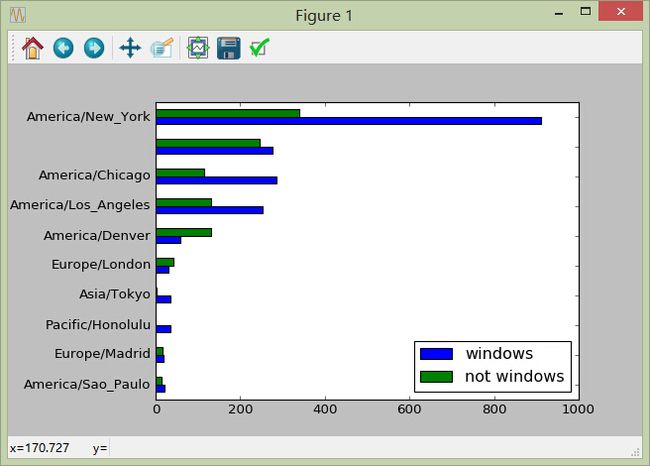
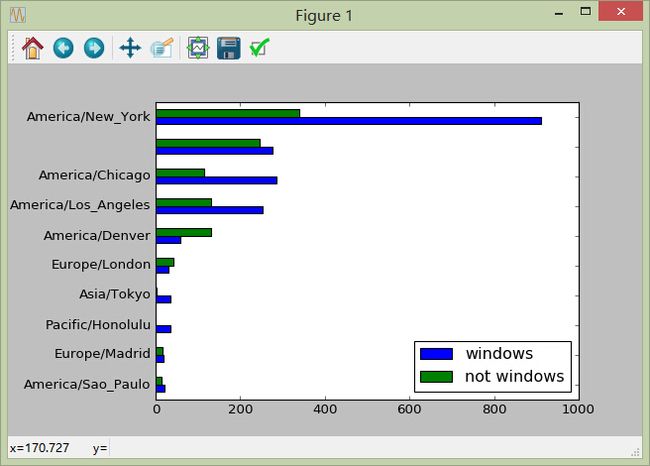
针对分析任务2:得到各地区windows和非windows用户的数量统计并绘图
其中有几个步骤与任务1相同,不再重复介绍,统一标注为“同任务1”。
1)从文件读取数据
同任务1
2)抽取用户时区信息
同任务1
3)抽取操作系统信息
cdf = df[df.a.notnull()]
ops = ['windows' if ('Windows' in x) else 'not windows' for x in cdf['a']]
ops[:10]
#[Out]# ['windows',
#[Out]# 'not windows',
#[Out]# 'windows',
#[Out]# 'not windows',
#[Out]# 'windows',
#[Out]# 'windows',
#[Out]# 'windows',
#[Out]# 'windows',
#[Out]# 'not windows',
#[Out]# 'windows']
4)根据时区、系统信息分组
groups = cdf.groupby(['tz',ops]) groups.size()[:2] #[Out]# tz #[Out]# not windows 245 #[Out]# windows 276
5)汇总统计分组后的信息
mgroups = groups.size().unstack()
mgroups = mgroups.fillna(0)
mgroups[:2]
#[Out]# not windows windows
#[Out]# tz
#[Out]# 245 276
#[Out]# Africa/Cairo 0 3
mgroups['sum'] = mgroups.sum(axis = 1)
#获取用户总量前10的地区
tsum10 = mgroups.sort_values('sum')[-10:]
tsum10
#[Out]# not windows windows sum
#[Out]# tz
#[Out]# America/Sao_Paulo 13 20 33
#[Out]# Europe/Madrid 16 19 35
#[Out]# Pacific/Honolulu 0 36 36
#[Out]# Asia/Tokyo 2 35 37
#[Out]# Europe/London 43 31 74
#[Out]# America/Denver 132 59 191
#[Out]# America/Los_Angeles 130 252 382
#[Out]# America/Chicago 115 285 400
#[Out]# 245 276 521
#[Out]# America/New_York 339 912 1251
tsum10 = tsum10.drop('sum', axis = 1)
tsum10
#[Out]# windows not windows
#[Out]# tz
#[Out]# America/Sao_Paulo 20 13
#[Out]# Europe/Madrid 19 16
#[Out]# Pacific/Honolulu 36 0
#[Out]# Asia/Tokyo 35 2
#[Out]# Europe/London 31 43
#[Out]# America/Denver 59 132
#[Out]# America/Los_Angeles 252 130
#[Out]# America/Chicago 285 115
#[Out]# 276 245
#[Out]# America/New_York 912 339
6)利用统计信息绘图
tsum10.plot(kind='barh')