日志采集——其它
Flume(cloudare
消息流:agent=>collect=>store
agent支持file,syslog等,store支持HDFS,file。
它有三种不同消息级别保障:end-to-end(先持久化,再发送),storeOnFailure,best effort(消息发送后不确认)
有管理端可以在线查询agent和collect运行情况,也可以动态配置
Scribe(facebook)
消息流:scribe-agent=>scribe=>store
scribe-agent对消息进行采集
agent和scribe之间通过thrif通讯,可以配置消息级别为storeOnFailure。
scribe对不同的topic进行不同的分发。
store支持文件,HDFS,buffer,scribe,thriftfile,null,bucket(多个store)
Kafka(LinkedIn)
消息流:Producer=>Broker=>Consumer
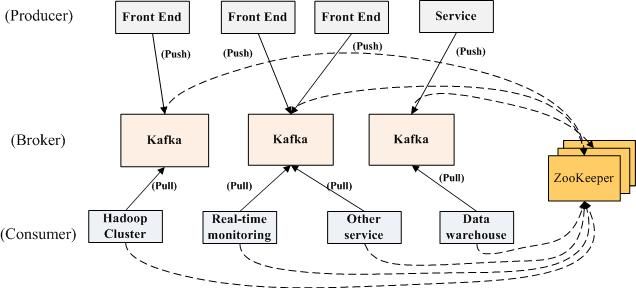
Kafka实际上是一个消息发布订阅系统。producer向某个topic发布消息,而consumer订阅某个topic的消息,进而一旦有新的关于某个topic的消息,broker会传递给订阅它的所有consumer。 在kafka中,消息是按topic组织的,而每个topic又会分为多个partition,这样便于管理数据和进行负载均衡。同时,它也使用了zookeeper进行负载均衡。
Producer和Consumer都可以通过它提供的api进行扩展。通过zookeeper,producer监听了broker和topic的更改信息,可以达到动态扩容
Chukwa
消息流:[adaptor=>agent]=>Collector=>Store
Adaptor就是采集数据;agent发送数据和守护adaptor
Collector,汇集消息,将小文件多写,改成适合HDFS的大文件少些
下面是网上的一个比较图