【Hadoop】Avro源码分析(二):反序列化之Generic
- 文件读取
- 类图继承
- DataFileStream
- DataFileReader
- Header与Data Block读取
- 初始化Header
- Data Block读取
本文着重研究avro反序列化的Generic方式,先从下面这段读取avro文件(反序列化)的代码开始讲起。
File file = new File("e://twitter.avro");
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>();
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(file, datumReader);
GenericRecord datum = null;
while(dataFileReader.hasNext()) {
datum = dataFileReader.next(datum);
System.out.println(datum);
}1. 文件读取
类图继承
DataFileReader是继承DataFileStream实现FileReader接口,
public class DataFileReader<D> extends DataFileStream<D> implements FileReader<D>DataFileStream
DataFileStream的字段:
private DatumReader<D> reader;
private long blockSize;
private boolean availableBlock = false;
private Header header;
/** Decoder on raw input stream. (Used for metadata.) */
BinaryDecoder vin;
/** Secondary decoder, for datums. * (Different than vin for block segments.) */
BinaryDecoder datumIn = null;
ByteBuffer blockBuffer;
long blockCount; // # entries in block
long blockRemaining; // # entries remaining in block
byte[] syncBuffer = new byte[DataFileConstants.SYNC_SIZE];
private Codec codec;其中,vin用来读取header,datumIn用来读取data block的datum。
DataFileReader
DataFileReader的构造器通过读入File返回SeekableInputStream、DatumReader进行构造。
/** Construct a reader for a file. */
public DataFileReader(File file, DatumReader<D> reader) throws IOException {
this(new SeekableFileInput(file), reader);
}
/** Construct a reader for a file. */
public DataFileReader(SeekableInput sin, DatumReader<D> reader)
throws IOException {
super(reader);
this.sin = new SeekableInputStream(sin);
initialize(this.sin);
blockFinished();
}其中,initialize()是对header进行初始化,详细介绍见下。SeekableInput是接口,
class SeekableFileInput extends FileInputStream implements SeekableInput static class SeekableInputStream extends InputStream implements SeekableInput其继承关系:
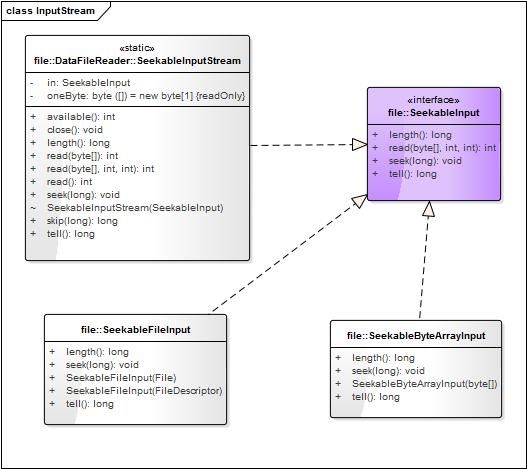
2. Header与Data Block读取
在前一篇中提到,avro文件由header与多个data block组成。
初始化Header
读取文件后,初始化header是在DataFileStream的initialize()方法中实现。
/** Initialize the stream by reading from its head. */
void initialize(InputStream in) throws IOException {
this.header = new Header();
this.vin = DecoderFactory.get().binaryDecoder(in, vin);
byte[] magic = new byte[DataFileConstants.MAGIC.length];
try {
vin.readFixed(magic); // read magic
} catch (IOException e) {
throw new IOException("Not a data file.");
}
if (!Arrays.equals(DataFileConstants.MAGIC, magic))
throw new IOException("Not a data file.");
long l = vin.readMapStart(); // read meta data
if (l > 0) {
do {
for (long i = 0; i < l; i++) {
String key = vin.readString(null).toString();
ByteBuffer value = vin.readBytes(null);
byte[] bb = new byte[value.remaining()];
value.get(bb);
header.meta.put(key, bb);
header.metaKeyList.add(key);
}
} while ((l = vin.mapNext()) != 0);
}
vin.readFixed(header.sync); // read sync
// finalize the header
header.metaKeyList = Collections.unmodifiableList(header.metaKeyList);
header.schema = Schema.parse(getMetaString(DataFileConstants.SCHEMA),false);
this.codec = resolveCodec();
reader.setSchema(header.schema);
}Data Block读取
类GenericDatumReader实现接口DatumReader,类图:
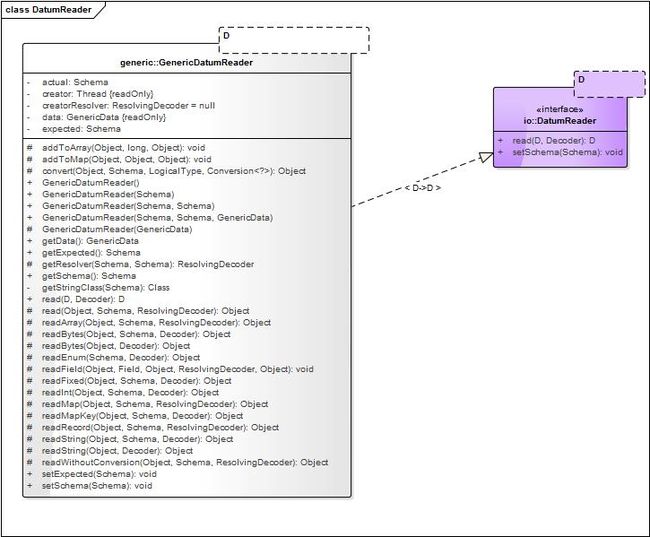
GenericDatumReader的字段如下:
private final GenericData data;
private Schema actual;
private Schema expected;
private ResolvingDecoder creatorResolver = null;
private final Thread creator;接下来,且看dataFileReader.next(datum)是如何读取data block的datum?在DataFileStream中next()通过调用DatumReader.read()来读取datum:
public D next(D reuse) throws IOException {
if (!hasNext())
throw new NoSuchElementException();
D result = reader.read(reuse, datumIn);
if (0 == --blockRemaining) {
blockFinished();
}
return result;
}在上面initialize()的reader.setSchema(header.schema);中已将DatumReader的actual与expected设置成了header.schema。看看GenericDatumReader.read()的实现:
@Override
@SuppressWarnings("unchecked")
public D read(D reuse, Decoder in) throws IOException {
ResolvingDecoder resolver = getResolver(actual, expected);
resolver.configure(in);
D result = (D) read(reuse, expected, resolver);
resolver.drain();
return result;
}
/** Called to read data.*/
protected Object read(Object old, Schema expected,
ResolvingDecoder in) throws IOException {
Object datum = readWithoutConversion(old, expected, in);
LogicalType logicalType = expected.getLogicalType();
if (logicalType != null) {
Conversion<?> conversion = getData().getConversionFor(logicalType);
if (conversion != null) {
return convert(datum, expected, logicalType, conversion);
}
}
return datum;
}
protected Object readWithoutConversion(Object old, Schema expected,
ResolvingDecoder in) throws IOException {
switch (expected.getType()) {
case RECORD: return readRecord(old, expected, in);
case ENUM: return readEnum(expected, in);
case ARRAY: return readArray(old, expected, in);
case MAP: return readMap(old, expected, in);
case UNION: return read(old, expected.getTypes().get(in.readIndex()), in);
case FIXED: return readFixed(old, expected, in);
case STRING: return readString(old, expected, in);
case BYTES: return readBytes(old, expected, in);
case INT: return readInt(old, expected, in);
case LONG: return in.readLong();
case FLOAT: return in.readFloat();
case DOUBLE: return in.readDouble();
case BOOLEAN: return in.readBoolean();
case NULL: in.readNull(); return null;
default: throw new AvroRuntimeException("Unknown type: " + expected);
}
}针对不同type的schema,read方法实现也不一样。具体我们来看readRecord的实现:
/** Called to read a record instance. May be overridden for alternate record * representations.*/
protected Object readRecord(Object old, Schema expected,
ResolvingDecoder in) throws IOException {
Object r = data.newRecord(old, expected);
Object state = data.getRecordState(r, expected);
for (Field f : in.readFieldOrder()) {
int pos = f.pos();
String name = f.name();
Object oldDatum = null;
if (old!=null) {
oldDatum = data.getField(r, name, pos, state);
}
readField(r, f, oldDatum, in, state);
}
return r;
}