How does a relational database work-事务管理(一)(翻译自Coding-Geek文章)
原文链接:http://coding-geek.com/how-databases-work/#Buffer-Replacement_strategies
紧接上一篇文章,本文翻译了如下章节:
Transaction manager(事务管理器)
一、关于ACID
一个满足ACID标准的事务,符合以下四个条件:
- Atomicity(原子性):
一个事务要么完整的执行所有对数据库的操作,要么不对数据库做任何操作,即使要持续运行10个小时。如果事务中止了,数据库将返回到事务执行前的状态(事务回滚)。 - Isolation(隔离性): A和B两个事务同时运行,无论哪个事务先执行完都不影响最终的执行结果。
- Durability(持久化):一旦事务成功提交;数据将持久化、保存到数据库,无论后续发生何种异常。
Consistency(一致性): 只有满足数据库约束的有效数据能写到数据库。一致性与原子性和隔离性强相关。

在同一个事务中,你可以执行多条SQL语句去查询、修改、新增、删除数据库中的数据。当多个事务同时访问一份数据时,混乱出现了。最经典的例子就是转账汇款,从A账号转账到B账户。想象一下,有这样两个事务:
- 事务1:从A账户转账100美元到B账户。
- 事务2:从A账户账户50美元到B账户。
对应到事务的ACID原则上来说:
- Atomicity(原子性):
确保发生任何故障(服务器崩溃、网络中断等)都不会出现100美元从A账户扣除了,却没有存入B账户的情况(数据不一致)。 - Isolation(隔离性):
事务1和2同时执行,最终结果始终是A账户减少150美元,B账号增加了150美元。不会出现A账号减少了150美元,B账户只增加了50美元的情况(事务2的执行结果覆盖的事务1,出现了数据不一致)。 - Durability(持久化):如果事务1成功提交,事务的执行结果将被保存到数据库。数据不会凭空丢失,即使数据库发生故障。
- Consistency(一致性): 确保在转账的过程中,总金额是一致的,A账户减少多少钱,B账户就对应的增加多少钱。
现代数据库不会使用纯粹、完全的事务隔离,因为它会带来极大的性能损耗。SQL规范定义了四种隔离模式。
- Serializable(串行化执行,
SQLite默认级别):最高隔离性级别。同时执行的两个事务完全隔离,每个事务有独立的运行空间。 Repeatable Read(可重读,
MySQL默认级别):每个事务独立执行。不过,如果一个事务添加了新数据,并已提交完毕;另外一个正在执行的事务能看到新加的数据。但,如果一个事务是修改数据后提交完毕,另一个正在执行的事务是看不到这种修改的。,在新增加数据的情况下,破环的事务了的隔离性。例如:事务A正在执行“SELECT COUNT(*) FROM
TABLE_X”,这时事务B往TABLE_X添加了数据。如果事务A再次执行COUNT(*)操作,前后两次的查询结果不同。这种情况被称之为”幻读”。Read Committed(Oracle、PostgreSQL、SQL
Server默认支持的级别):这种隔离度是在Repeatable
Read的基础上,增加了一条打破事务隔离性的规则。如果事务A读取了数据D,同时事务B对数据做了修改(包括删除)后提交。事务A再次读取数据D,能感知事物B对数据D的修改。也就是说,Read Committed模式下,一个事务既可以感知另一个事务添加新数据,也能感知这个事务对数据的修改。这个模式也叫
non-repeatable read。Read uncommitted:隔离性最差的一种方式,它是在 Read
committed的基础上又增加了一条破坏事务隔离性的规则。事务A读取了数据D,同时数据D被事务B做了修改(事务B还未提交,还在执行过程中);如果事务A再次读取数据D,它将感知数据D被修改了,然后事务B回滚,A持有的数据还是被事务B修改后的。实际数据D未被修改(因为事务B回滚了)。这种模式叫”脏读”。
大多数数据库会添加自定义的隔离性级别, 例如在Oracle、PostgreSQL、SQL Server使用的snapshot Isolation(快照隔离)。很多时间,数据库不会支持SQL规范中定义的所有隔离模式(特别是 Read uncommitted模式)。
用户在连接到数据库时,可以修改默认隔离模式。
二、 Concurrency contro(并发控制)
支撑数据库实现事务隔离性、一致性、原子性的关键是解决好数据库同写的问题(含添加、删除和修改)。
1) 如果所有的事务仅仅是读取数据,他们能并行工作,相互无影响。
2) 如果有一个事务(哪怕只有一个)在修改其他事务读取的数据,数据库需要考虑如何屏蔽数据修改对其它事务的影响。并且,需要要确保修后的数据不会被其它事务覆盖。
这种技术称为“并发控制”。
解决这个问题最简单的方法是让多个事务按时间先后依次执行(串行化)。但是,这是一种非常低效的做法(在多核处理器上仅跑一个任务)。
理想的解决方式是随时允许创建事务、运行事务、删除事务。要达到这个目标,需要做到以下几点:
- 实时监控所有事务的所有操作。
- 检查是否存在多个事务同时读/写相同数据的情况,是否造成冲突。
- 重排引起冲突的事务执行顺序,将冲突区域范围缩小。
- 按重排好的顺序执行引起数据冲突的操作(不会引起冲突的事务操作仍然并行)。
- 考虑把一些引起冲突的事务取消掉。
本质上来讲,这是一个冲突事务的调度问题。冲突事务调度的算法是非常复杂的,也非常耗时。企业级的数据库不可能花费几个小时去寻找最优调度策略,处理冲突事务。
因此,它们仅使用简易的调度策略,使得算法耗费的时间在可接受的范围内。当然这种调度策略会导致突事务更多的时间等待。
三、 Lock manager(锁管理)
为解决事务冲突的问题,大多数数据库使用加锁和数据版本管理两种策略。这是一个大的命题,我将聚焦在锁管理部分,适当介绍一下数据版本管理。
Pessimistic lock(悲观锁)。它背后的原理是:
- 如果一个事务需要获取数据。
- 它先将数据加锁。
- 如果另一个事务也需要获取这块数据。
- 它需要等待第一个事务释放锁。
这种锁也叫独享锁-exclusive lock。
但是,使用独享锁将导致访问数据库代价高昂。因为,它要求其它也需要读取同一批数据的事务等待。这也是为什么存在另外一种锁—(shared lock)共享锁。
Shared lock(共享锁)。其原理是:
- 如果事务1仅是需要读取数据A。
- 事务1对数据A加shared lock,然后读取数据A。
- 如果事务2也是只需要读取数据A。
- 事务2对数据A加shared lock,然后读取数据A。
- 如果事务3需要修改数据A。
- 事务3对是数据A加Pessimistic lock,它需要等待另外两个事务释放shared lock。
如果一块数据已经添加了Pessimistic lock。另外一个事务即使只是读数据(需要对数据加shared lock),也需要等待Pessimistic lock释放;否则读取的是脏数据。
Lock manager的职责就是管理锁的申请和释放。Lock manager通过哈希表管理锁资源,也管理着锁与数据的关联关系。包括:
- 哪些事务对特定数据加了锁。
- 哪些事务在等待对特定数据加锁。
四、 Dead lock(死锁)
使用锁有可能导致一个问题,即两个事务同时等待对方释放锁。
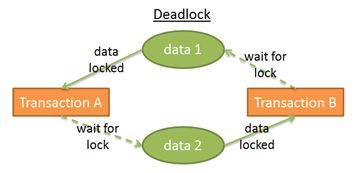
在这张图中,可以看到:
- Transaction A拥有data1的exclusive lock,同时申请data2权限。
- Transaction B拥有data2的exclusive lock,同时申请data1权限。
这就出现了死锁。
出现死锁时,Lock manger将选择其中一个事务回滚以解除死锁状态。选择哪一个事务回滚,这是个很复杂的问题,要考虑以下方面:
- 回滚涉及数据量最小的事务(造成混滚的代价最小),是否就是最好的决策?
- 回滚最新提交的事务(因为其它事务等待的时间更长),是否就是最好的决策?
- 回滚耗时更短的事务(避免长时间等待,线程饿死),是否就是最好的决策?
- 即使回滚,又有多少其它事务会受此回滚的影响?
当然,在做出回滚的决策之前,先要明确是否已经出现了事务死锁。
依据lock manager的哈希表,能画出一个依赖关系图(类似上面的截图)。如果在图中出现了环路,即意味着出现了死锁。检查是否出现环路是非常耗时的,因为依赖关系图的数据量通常很庞大;所以,一般采用更简单的方法:判断是否超时。如果事务申请的锁未在指定的超时时间内分配,则认为事务进入了死锁。
Lock manager能够判断新申请的锁是否会导致死锁。同样的,要做出准确的判断,算法也是非常耗时间的。取而代之,它采用一些检查条件来判断。
五、 Two-phase locking(二阶段锁)
为确保一个事务完全隔离,最简单方法是在事务开始时申请锁,在事务结束时释放锁。这意味着,事务必须等待申请完所有需要的锁才开始运行,在执行过程中完全占用锁,结束时才统一释放。这种方案逻辑上没问题,但是会耗费很多时间在等待锁资源上。
一种更快一些的方案是Two-Phase Locking Protocol(在DB2和SQL Server中使用)。在这种方案中,一个事务被分解为两个阶段。
- 在growing phase(发展阶段),事务可以申请锁,不能释放锁。
在shrinking phase(收缩阶段),事务可以释放锁(已经加锁处理过的数据,且不会再处理),不能申请锁。
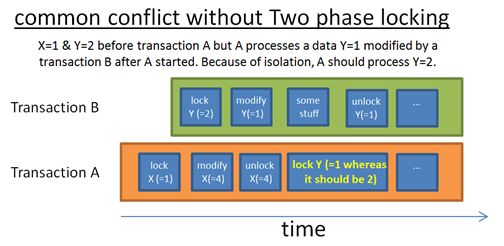
其背后的原理有这样两条:
- 尽快释放不再使用的锁,以减少其它事务的等待时间。
- 避免出现这种情况:某个事务获取数据后,数据又被其它事务修改,以至于数据与获取时不一致。
这种策略能完美运行,除非一个事务修改了数据,释放了锁,然后又回滚事务。另一个事务在前一个事务释放锁后,读取了数据;它不清楚修改后的数据后面又发生了回滚。
为了避免出现这种情况,规定所有的exclusive lock必须在事务结束时才释放。
再多说几句:
当然,一个真实的企业级数据库会使用更复杂的方案,更丰富的锁(如:意向锁),更细的锁控制粒度(基于行、分页、分区、表空间等)。但,其核心思想是一样的。
这里,我只描述了最基础的锁的原理。Data versioning(数据版本管理)是另一种解决事务冲突的方案。
数据版本管理的基本原理是:
- 所有的事务都可以同时修改相同的数据。
- 每个事务都持有所需数据的一个拷贝(一个版本)。
如果多个事务修改相同的数据,只有一个事务的修改会被持久化,其它事务的修改会丢弃(事务回滚,后面也可能re-run)。
这种方式带来性能上的提升,因为:
- 读数据的事务不会阻塞写数据的事务。
- 写数据的事务也不会阻塞读数据的事务。
- 不存在又笨又慢(fat and slow)的锁管理开销。
如果没有出现两个事务同时写同一片数据,这种方式更好。但是,这种方式需要巨大的磁盘空间开销。
数据版本管理和锁管理是两种不同的思想: 乐观锁(optimistic locking)与悲观锁(pessimistic locking)。它们都同时存在支持方和反对方,使用哪种方式依赖于具体的引用场景(more reads VS more writes)。说到数据库对Data versioning的支持情况,我觉得PostgreSQL的多版本数据管理并发控制做得非常强大。
一些数据库,如DB2(9.7之前版本)和SQL Server(除了所谓的视图快照隔离)仅支持加锁的机制。其它一些数据库,如PostgreSQL、MySQL和Oracle同时支持加锁和数据版本管理两种方式。我不知道有什么数据库是仅支持Data versioning的(如果你知道,请告诉我)。
如果你已经读过了介绍隔离性不同级别的章节,就应该清楚。提升隔离性将增加锁的数量,增加事务申请锁的等待时间。这也是为什么大多数据库不将隔离性最强的串行化(Serializable),设置为默认级别的原因。
你也可以在主流的数据库(如MySQL、PostgreSQL、Oracle)指导文档中检查它的设置情况。