CNN卷积神经网络
Convolutional Neural Networks卷积神经网络
上面聊到,好像CNN一个牛逼的地方就在于通过感受野和权值共享减少了神经网络需要训练的参数的个数。那究竟是啥的呢?
下图左:如果我们有1000x1000像素的图像,有1百万个隐层神经元,那么他们全连接的话(每个隐层神经元都连接图像的每一个像素点),就有1000x1000x1000000=10^12个连接,也就是10^12个权值参数。然而图像的空间联系是局部的,就像人是通过一个局部的感受野去感受外界图像一样,每一个神经元都不需要对全局图像做感受,每个神经元只感受局部的图像区域,然后在更高层,将这些感受不同局部的神经元综合起来就可以得到全局的信息了。这样,我们就可以减少连接的数目,也就是减少神经网络需要训练的权值参数的个数了。如下图右:假如局部感受野是10x10,隐层每个感受野只需要和这10x10的局部图像相连接,所以1百万个隐层神经元就只有一亿个连接,即10^8个参数。比原来减少了四个0(数量级),这样训练起来就没那么费力了,但还是感觉很多的啊,那还有啥办法没?
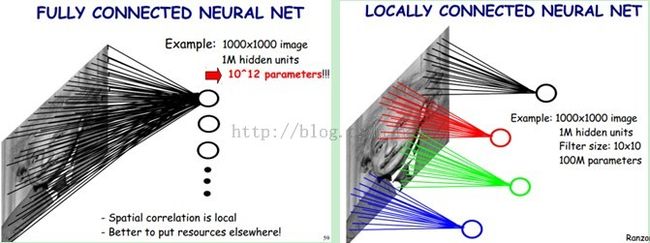
我们知道,隐含层的每一个神经元都连接10x10个图像区域,也就是说每一个神经元存在10x10=100个连接权值参数。那如果我们每个神经元这100个参数是相同的呢?也就是说每个神经元用的是同一个卷积核去卷积图像。这样我们就只有100个参数!不管你隐层的神经元个数有多少,两层间的连接我只有100个参数啊!这就是权值共享!这就是卷积神经网络的主打卖点啊!
好了,你就会想,这样提取特征也忒不靠谱吧,这样你只提取了一种特征啊?对了,真聪明,我们需要提取多种特征对不?假如一种滤波器,也就是一种卷积核就是提出图像的一种特征,例如某个方向的边缘。那么我们需要提取不同的特征,怎么办,加多几种滤波器不就行了吗?对了。所以假设我们加到100种滤波器,每种滤波器的参数不一样,表示它提出输入图像的不同特征,例如不同的边缘。这样每种滤波器去卷积图像就得到对图像的不同特征的放映,我们称之为Feature Map。所以100种卷积核就有100个Feature Map。这100个Feature Map就组成了一层神经元。到这个时候明了了吧。我们这一层有多少个参数了?100种卷积核x每种卷积核共享100个参数=100x100=10K,也就是1万个参数。见下图右:不同的颜色表达不同的
滤波器。
刚才说隐层的参数个数和隐层的神经元个数无关,只和滤波器的大小和滤波器种类的多少有关。那么隐层的神经元个数怎么确定呢?它和原图像,也就是输入的大小(神经元个数)、滤波器的大小和滤波器在图像中的滑动步长都有关!例如,我的图像是1000x1000像素,而滤波器大小是10x10,假设滤波器没有重叠,也就是步长为10,这样隐层的神经元个数就是(1000x1000 )/ (10x10)=100x100个神经元了,假设步长是8,也就是卷积核会重叠两个像素,那么……我就不算了,思想懂了就好。注意了,这只是一种滤波器,也就是一个Feature Map的神经元个数哦,如果100个Feature Map就是100倍了。由此可见,图像越大,神经元个数和需要训练的权值参数个数的贫富差距就越大。
需要注意的一点是,上面的讨论都没有考虑每个神经元的偏置部分。所以权值个数需要加1 。这个也是同一种滤波器共享的。
总之,卷积网络的核心思想是将:局部感受野、权值共享(或者权值复制)以及时间或空间亚采样这三种结构思想结合起来获得了某种程度的位移、尺度、形变不变性。
3.训练过程
神经网络用于模式识别的主流是有指导学习网络,无指导学习网络更多的是用于聚类分析。对于有指导的模式识别,由于任一样本的类别是已知的,样本在空间的分布不再是依据其自然分布倾向来划分,而是要根据同类样本在空间的分布及不同类样本之间的分离程度找一种适当的空间划分方法,或者找到一个分类边界,使得不同类样本分别位于不同的区域内。这就需要一个长时间且复杂的学习过程,不断调整用以划分样本空间的分类边界的位置,使尽可能少的样本被划分到非同类区域中。
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。卷积网络执行的是有导师训练,所以其样本集是由形如:(输入向量,理想输出向量)的向量对构成的。所有这些向量对,都应该是来源于网络即将模拟的系统的实际“运行”结果。它们可以是从实际运行系统中采集来的。在开始训练前,所有的权都应该用一些不同的小随机数进行初始化。“小随机数”用来保证网络不会因权值过大而进入饱和状态,从而导致训练失败;“不同”用来保证网络可以正常地学习。实际上,如果用相同的数去初始化权矩阵,则网络无能力学习。
训练算法与传统的BP算法差不多。主要包括4步,这4步被分为两个阶段:
第一阶段,向前传播阶段:
a)从样本集中取一个样本(X,Yp),将X输入网络;
b)计算相应的实际输出Op。
在此阶段,信息从输入层经过逐级的变换,传送到输出层。这个过程也是网络在完成训练后正常运行时执行的过程。在此过程中,网络执行的是计 算(实际上就是输入与每层的权值矩阵相点乘,得到最后的输出结果):
Op=Fn(…(F2(F1(XpW(1))W(2))…)W(n))
第二阶段,向后传播阶段
a)算实际输出Op与相应的理想输出Yp的差;
b)按极小化误差的方法反向传播调整权矩阵。
卷积网络较一般神经网络在图像处理方面有如下优点: a)输入图像和网络的拓扑结构能很好的吻合;b)特征提取和模式分类同时进行,并同时在训练中产生;c)权重共享可以减少网络的训练参数,使神经网络结构变得更简单,适应性更强。