Storm的学习(五)
这一篇博客打算说一说Trident的聚合操作,场景:比如我们在计算wordCount的时候,需要从各个Partion上面获取word出现的次数,这就需要聚合操作,就类似与Mapeduce的Reduce一样。
1 partition aggregate
按照字面的意思就是在各个partition上面进行聚集操作,比如下面的例子,就是统计各个Partition元祖数目。
package storm.trident.operation.builtin;
import storm.trident.operation.CombinerAggregator;
import storm.trident.tuple.TridentTuple;
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}CombinerAggregator是一个接口,并且支持泛型。有三个方法,init()获取输入元祖的字段(这个例子中是计数,因此每一个元祖都返回1),combine()用于不同元祖的合并操作,zero()当没有元祖时返回的类型(本例中返回0).先在各自的partition上面进行操作,然后结果在合并成一个partition。
package com.trident.aggregate;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Random;
import backtype.storm.task.TopologyContext;
import backtype.storm.tuple.Fields;
import storm.trident.operation.TridentCollector;
import storm.trident.spout.IBatchSpout;
public class Spout01 implements IBatchSpout{
private int batchSize;
public Spout01(int batchSize) {
super();
this.batchSize = batchSize;
}
@Override
public void open(Map conf, TopologyContext context) {
// TODO Auto-generated method stub
}
@Override
public void emitBatch(long batchId, TridentCollector collector) {
// TODO Auto-generated method stub
Random random = new Random();
for(int i=0;i<batchSize;i++){
int num = random.nextInt(100);
System.out.println("emit: "+num);
List<Object> list = new ArrayList<Object>();
list.add(num);
collector.emit(list);
}
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
@Override
public void ack(long batchId) {
// TODO Auto-generated method stub
}
@Override
public void close() {
// TODO Auto-generated method stub
}
@Override
public Map getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
@Override
public Fields getOutputFields() {
// TODO Auto-generated method stub
return new Fields("value");
}
}package com.trident.aggregate;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class Function01 extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
// TODO Auto-generated method stub
System.out.println(tuple.get(0));
}
}package com.trident.aggregate;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.tuple.Fields;
import storm.trident.TridentTopology;
import storm.trident.operation.builtin.Count;
public class demo01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Spout01 spout01 = new Spout01(10);
Function01 function01 = new Function01();
TridentTopology topology = new TridentTopology();
topology.newStream("input", spout01).shuffle().
partitionAggregate(new Fields("value"), new Count(), new Fields("count"))
.each(new Fields("count"), function01,new Fields("output"))
.parallelismHint(3);
//each(new Fields("value"), function01,new Fields("value1"));
Config config = new Config();
config.setMaxSpoutPending(10);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Count", config, topology.build());
}
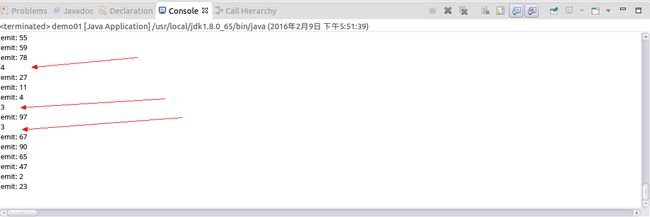
}new Spout01(10)模拟一次发送10个元祖,parallelismHint(3)模拟并行化是3,因此理论上是输出3,3,4。
下面看看代码具体的运行:
2 aggregate
aggregate与partition aggregate不同,在执行前会先执行global operation,将同一个batch(上个例子中batchsize=10就是一个batch中包含10个元祖)中的元祖合并到一个partition上,在进行合并操作,如下所示的代码:
package com.trident.aggregate;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.tuple.Fields;
import storm.trident.TridentTopology;
import storm.trident.operation.builtin.Count;
public class demo01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Spout01 spout01 = new Spout01(10);
Function01 function01 = new Function01();
TridentTopology topology = new TridentTopology();
topology.newStream("input", spout01).shuffle().
aggregate(new Fields("value"), new Count(), new Fields("count"))
//partitionAggregate(new Fields("value"), new Count(), new Fields("count"))
.each(new Fields("count"), function01,new Fields("output"))
.parallelismHint(3);
//each(new Fields("value"), function01,new Fields("value1"));
Config config = new Config();
config.setMaxSpoutPending(10);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Count", config, topology.build());
}
}很显然,此时运行的结果应该是10,并且parallelismHint(3)似乎也不起作用。
Aggregator常用的接口有三种:ReducerAggregator,Aggregator,CombinerAggregator,都可以用于aggregate和partition aggregate,CombinerAggregator前面已经介绍过了,这里就不在重复。
The ReducerAggregator interface
ReducerAggregator首先将属于同一个batch的partitions合并成一个单独的partition,然后再进行aggregation操作。里面主要有两个方法:init()返回一个初始值。reduce()迭代操作元组进行相应的操作。
package com.trident.aggregate;
import storm.trident.operation.ReducerAggregator;
import storm.trident.tuple.TridentTuple;
public class Sum implements ReducerAggregator<Integer>{
private static int sum;
@Override
public Integer init() {
// TODO Auto-generated method stub
return 0;
}
@Override
public Integer reduce(Integer curr, TridentTuple tuple) {
// TODO Auto-generated method stub
System.out.println(sum+"+ "+tuple.getInteger(0)+"="+(sum+tuple.getInteger(0)));
sum += tuple.getInteger(0);
return sum;
}
}package com.trident.aggregate;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.tuple.Fields;
import storm.trident.TridentTopology;
import storm.trident.operation.builtin.Count;
public class demo01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Spout01 spout01 = new Spout01(3);
Function01 function01 = new Function01();
TridentTopology topology = new TridentTopology();
topology.newStream("input", spout01).shuffle().
aggregate(new Fields("value"), new Sum(), new Fields("sum"))
//aggregate(new Fields("value"), new Count(), new Fields("count"))
//partitionAggregate(new Fields("value"), new Count(), new Fields("count"))
.each(new Fields("sum"), function01,new Fields("output"))
.parallelismHint(2);
//each(new Fields("value"), function01,new Fields("value1"));
Config config = new Config();
config.setMaxSpoutPending(10);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Count", config, topology.build());
}
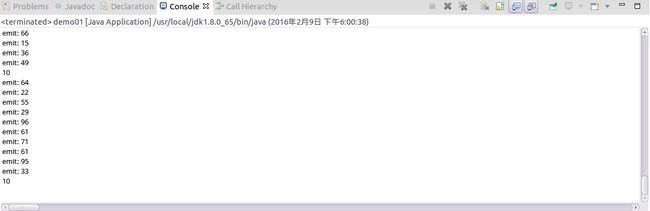
}运行结果如下:

The Aggregator interface
首先将属于同一个batch的partitions合并成一个单独的partition,然后再进行aggregation操作。init()返回元组的相应字段,aggregate()聚合操作,complete()最后一个batch完成操作后,发送一个tuple(注意和ReducerAggregator的区别,ReducerAggregator是接收一个元组发送一次结果,而Aggregator是等batch完成后,在发送结果)。下面还是求和操作:
package com.trident.aggregate;
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseAggregator;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class Sum01 extends BaseAggregator<Integer> {
private Integer integer = 0;
@Override
public Integer init(Object batchId, TridentCollector collector) {
// TODO Auto-generated method stub
return 0;
}
@Override
public void aggregate(Integer integer, TridentTuple tuple,
TridentCollector collector) {
// TODO Auto-generated method stub
this.integer += tuple.getInteger(0) +integer;
}
@Override
public void complete(Integer integer, TridentCollector collector) {
// TODO Auto-generated method stub
collector.emit(new Values(this.integer));
}
}
package com.trident.aggregate;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.tuple.Fields;
import storm.trident.TridentTopology;
import storm.trident.operation.builtin.Count;
public class demo01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Spout01 spout01 = new Spout01(1);
Function01 function01 = new Function01();
TridentTopology topology = new TridentTopology();
topology.newStream("input", spout01).shuffle().
aggregate(new Fields("value"), new Sum01(), new Fields("sum"))
//aggregate(new Fields("value"), new Count(), new Fields("count"))
//partitionAggregate(new Fields("value"), new Count(), new Fields("count"))
.each(new Fields("sum"), function01,new Fields("output"))
.parallelismHint(1);
//each(new Fields("value"), function01,new Fields("value1"));
Config config = new Config();
config.setMaxSpoutPending(10);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Count", config, topology.build());
}
}
运行结果如下:
这里有个小问题:如果俺同时求和和均值该如何操作啊?
这里仅写一个小小的代码就可以了,就不多说了,感兴趣的可以自己去实现:
mystream.chainedAgg().partitionAggregate(new Fields("b"),
new Average(), new Fields("average")).partitionAggregate(
new Fields("b"), new Sum(), new Fields("sum")).chainEnd();
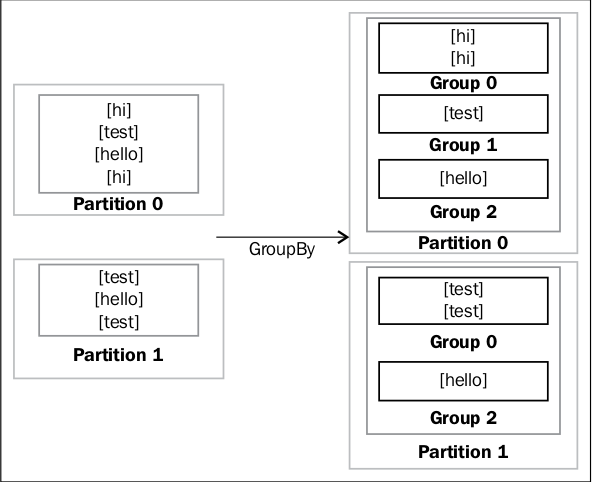
还有一个常用的groupBy操作,即分组操作喽。。。看下面的图即可知道意思,就不在多写代码了。