DWARF调试格式的简介(续完)
数组
数组类型由一个DIE描述,它定义了该数据是以列为主序(就像在Fortan里),还是以行为主序(就像在C或C++里)。该数组的索引由一个subrange类型表示,这个类型给出了每个维度的上下限。这允许DWARF描述C形式的、总是以0作为最小索引的数组;以及在Pascal或Ada中,可以任意值作为上下限的数组。
结构体,类,联合,及接口
大多数语言允许程序员把数据集中到结构体(在C及C++里称为struct,在Pascal里称为record)。这个结构体的每个部分通常具有一个唯一的名字,可能具有不同的类型,并且每个都有自己的空间。C及C++拥具有union,而Pascal拥具有可变(variant)record,它们类似于一个结构体,但各部分占据相同的内存位置。Java接口具有一个C++class特性的一个子集, 因为它可能仅有抽象方法及常量数据成员。
虽然每个语言有自己的术语(C++把这些部分称为一个类成员,而Pascal称它们为域(field)),底层的构造可以描述在DWARF里。尊重其传统,DWARF使用C/C++术语,同时具有描述struct,union,class及interface的DIE。在这里我们将描述类(class)DIE,但其它DIE在本质上具有相同的构造。
用于一个类的DIE是描述这个类每个成员的DIE的父亲。每个类有一个名字,还可能有其它属性。如果在编译时刻一个实例的大小是已知的,那么它将具有一个字节大小属性。每个这些描述看起来非常类似一个简单变量的描述,虽然可能有某些额外的属性。例如, C++允许程序员指定一个成员是public,private,还是protected。这通过可访问性(accessibility)属性来描述。
C及C++允许不是简单变量的比特域(bit field)作为一个类成员。它们被描述为从这个类实例的开头到这个比特域最左侧比特的偏移,以及显示这个成员占据多少比特的一个比特大小(bit size)。
变量
变量通常都相当简单。它们有一个名字,代表一块可以包含某个类型的一个值的内存(或寄存器)。这个变量可以包含的值的类型,以及修改的限制(即,它是否是常量),都由该变量的类型来描述。
区分变量的是:该变量保存在何处,及其作用域。一个变量的作用域定义了在这个程序的何处这个变量是已知的,并且在某种程度上,它由该变量在何处声明确定。在C中,在一个函数或块中声明的变量具有函数或块作用域。那些声明在一个函数外的变量具有全局或文件作用域。这允许在不同的文件中定义具有相同名字的、不同的变量,而不引起冲突。这也允许不同的函数或编译单元引用相同的变量。DWARF使用一个(file, line,column)三元组记录变量被定义在源文件中的何处。
DWARF把变量分为3个类别:常量,函数参数,及变量。一个常量用于描述具有真正命名常量(true named constants)的语言,比如Ada参数。(C没有把常量用作语言部分。声明一个变量const仅是告诉你,不使用一个显式的转换,你不能修改这个变量)。一个正式的参数代表传递给一个函数的值。稍后我们将回到这个话题。
某些语言,像C或C++(但不包括Pascal),允许声明一个变量而不定义它。这暗示在别的地方应该有该变量的一个真正的定义,在编译器或调试器可望找到的地方。一个描述一个变量声明的DIE提供了该变量的一个描述,但没有告诉调试器它在哪里。
大多数变量具有一个描述该变量保存在哪里的位置属性。在最简单的情形里,一个变量保存在内存中,并具有一个固定的地址[1]。但许多变量是被动态分配的,比如那些声明在一个C函数内的,并且定位它们要求某些(通常简单的)计算。例如,一个局部变量可能被分配在栈上,定位它可能只是向一个框指针(frame pointer)加上一个固定的偏移那么简单。在其它情形里,这个变量可能保存在一个寄存器中。其它变量可能要求稍微复杂的计算来定位数据。作为一个C++类成员的一个变量可能要求更加复杂的计算,来确定在一个派生类中基类的位置。
位置表达式(Location Expression)
DWARF提供了一个非常通用的方案来描述如何定位由一个变量代表的数据。一个DWARF位置表达式包含了告诉一个调试器如何定位该数据的一连串操作。图7显示了3个名为a,b及c的变量的DIE。变量a在内存里有一个固定的位置,变量b在寄存器0里,而变量c在当前函数栈框内偏移–12处。虽然a被首先声明,描述它的DIE是在所有的函数之后产生的。a的实际地址将由链接器填入。
[1] 此外,可能不是一个固定地址,但是到这个可执行代码载入地址的一个固定偏移。载入器重定位(relocate)了对一个可执行映像中地址的引用,这样,在运行时,位置属性包含实际的内存地址。在一个目标文件里,位置属性是这个偏移连同一个合适的重定位表项(relocation table entry)。
图7. 变量a,b及c的DWARF描述
DWARF位置表达式可以包含由一个简单栈机器(stack machine)求值的一连串操作及值。这可以是一个任意复杂的计算,包含种类繁多的算术操作、在该表达式内的测试及跳转、对其它位置表达式的调用求值,以及访问处理器的内存或寄存器。甚至有操作用于描述分裂并保存在不同位置的数据,比如一个结构体,其中某些数据保存在内存里,而某些则保存在寄存器中。
虽然这巨大的灵活性实际上很少使用,位置表达式应该允许描述一个变量数据的位置,不管这个语言的定义如何的复杂,或这个编译器的优化如何的聪明。
描述可执行代码
函数及子程序
DWARF把返回值的函数及不返回值的子例程处理作同一个事物的不同变体。稍微偏离其肇始的C的术语,DWARF使用一个Subprogram DIE描述两者。这个DIE有一个名字、一个源位置三原体(triplet),及一个表示这个子程序是否是外部的属性,即,在当前编译单元外可见。
一个Subprogram DIE具有的属性给出了这个子程序占据的上下限内存地址,如果子程序它是连续的;或者一个内存范围列表,如果该函数没有占据一组连续的内存地址。低的PC地址被假定为这个例程的入口,除非显式地指定了另一个。
一个函数返回的值由类型属性给出。不返回值的例程(像C的void函数)没有这个属性。DWARF不描述一个函数调用的约定;这定义在特定架构的应用二进制接口(Application Binary Interface——ABI)中。可能存在能帮助一个调试器定位该字程序数据,或找出当前子程序调用者的属性。返回地址属性是一个指明该调用者保存地址的位置表达式。框基址(frame base)属性是一个计算该函数栈框地址的位置表达式。这些是有用的,因为某些编译器有可能执行的、最常用的优化是:消除显式保存返回地址或框指针(frame pointer)的指令。
Subprogram DIE拥有描述这个子程序的DIE。由具有variable parameter属性的变量DIE来表示可能被传递给一个函数的参数。如果这个参数是可选的、或具有一个缺省值,这些都由属性来表示。这些参数DIE的次序与这个函数的实参列表相同,但中间可能插有额外的DIE,例如,定义由这些参数使用的类型。
一个函数可能定义了可以是局部或全局的变量。这些变量的DIE跟在参数DIE后面。许多语言允许嵌套词法块(lexical block)。这些由词法块DIE表示,它进而可能拥有变量DIE,或嵌套的词法块DIE。
这里是一个稍微长些的例子。图8a显示了strndup.c,GCC中复制一个字符串的函数的源代码。图8b列出了为这个文件产生的DWARF。就像在之前的例子中,没有显示源代码行信息及位置属性。
图8a. strndup.c源代码
在图8b里,DIE <2>显示了size_t的定义,它是unsigned int的一个typedef。这允许一个调试器把形参n的类型显示为一个size_t,而把其值显示为一个无符号整数。DIE <5>描述了函数strndup。它拥有到其兄弟DIE <10>的一个指针;接着的所有DIE都是这个Subprogram DIE的孩子。该函数返回一个描述在DIE<10>中的,指向char的指针。DIE <5>还把该子例程描述为外部的、有原型的函数,并给出了该例程的上下限PC值。该例程的形参及局部变量被描述在DIE<6>到<9>中。

图8b. strndup.c的DWARF描述
编译单元
大多数有趣的程序包含多个文件。构成一个程序的每个源文件被独立编译,然后与系统库链接起来构成这个程序。DWARF把每个单独编译的源文件称为一个编译单元。
每个编译单元的DWARF数据以一个Compilation UnitDIE开始。这个DIE包含这个编译单元的通用信息,包括目录及源文件名、使用的编程语言、一个标识这个DWARF数据的产生者的字符串,以及到协助定位行号及宏信息的DWARF数据节的一个偏移。
如果该编译单元是连续的(即,它被载入一块内存中),那么有该单元内存上下限的值。这使得调试器更加容易识别哪个编译单元在一个特定内存地址构建代码。如果该编译单元不是连续的,那么由编译器及链接器提供一组该代码占据的内存地址。
Compilation Unit DIE是所有描述该编译单元的DIE的父亲。通常,开始的DIE(多个)将描述数据类型,跟着是全局数据,然后构成这个源文件的函数。用于变量及函数的DIE出现的次序与这些变量及函数在该源文件中出现的次序相同。
数据编码
从概念上讲,描述一个程序的DWARF数据是一棵树。每个DIE可能有一个兄弟并且包含的若干DIE。每个这些DIE有一个类型(称为它的TAG)及若干属性。每个属性由一个属性类型及一个值表示。不幸的是,这不是一个非常紧凑的编码。没有压缩的话, DWARF数据是难以处理的。
DWARF版本2及3提供了几个方式来缩小这个需要与目标文件一起保存的数据。第一个是通过以前序(prefix order)保存“扁平化(flatten)”这棵树。DIE的每个类型被定义为要么有孩子,要么没有。如果DIE没有孩子,下一个DIE是其兄弟。如果DIE可以有孩子,那么下一个DIE是其第一个孩子。余下的孩子被表示为第一个孩子的兄弟。这样,到兄弟或子DIE的链接可以被消除。如果编译器的编写者认为,从一个DIE跳到其兄弟,而不需要逐个通过其子DIE,是有用的(例如,跳到在一个编译单元里的下一个函数),那么可以向这个DIE添加一个兄弟属性。
第二个压缩数据的方案是使用缩略语。虽然DWARF在产生哪个DIE及属性方面允许高度的灵活性,大多数编译器仅产生有限的一组DIE,它们都具有相同的一组属性。作为保存这个DIE的TAG值及属性-值对的替代,仅保存一个缩略语表的一个索引,后跟属性码。每个缩略语给出该标签的值——一个表示该DIE是否有孩子的标记,并带有所期望值的类型的一组属性。图9显示了用于图8b中的形参DIE的缩略语。图8中的DIE <6>实际上如图示那样编码 [1]。这以增加一些复杂性作为代价,显著减少了需要保存的数据量。
[1] 编码的项还包括该文件及行的值,它们没有显示在图8b里。
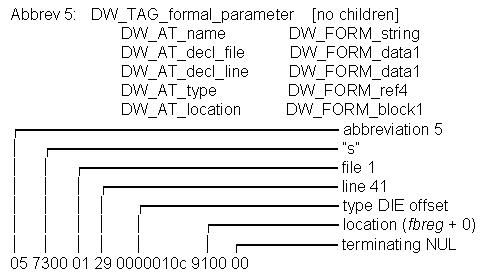
图9. 缩写项及编码形式
DWARF版本3允许从一个编译单元引用保存在另一个编译单元或共享库中的DWARF数据的特性较少使用。许多编译器为每个编译单元产生相同的缩略语表或基本类型,不管这个编译单元是否真正使用所有这些缩略语或类型。这些可以保存在一个共享库里,并由每个编译单元援引,而不是复制在每个编译单元里。
其它DWARF数据
行号表
DWARF行表(linetable)包含了源代码行(用于一个程序的可执行部分)与包含对应机器代码的内存之间的映射。在最简单的形式中,这可以被看做一个矩阵,其中一列包含内存地址,而另一列包含源代码三元组(文件,行及列)。如果你希望在特定的一行上设置一个断点,这个表向你给出保存这个断点的内存地址。相反,如果你的程序在内存的某个位置上有一个缺陷(比如,使用一个坏的指针),你可以查看最接近这个内存地址的源代码行。
DWARF通过添加传送一个程序额外信息的列进行扩展。当一个编译器优化这个程序时,它可能移动或删除指令。一个给定源代码语句的代码可能没有保存为一个机器指令序列,而可能是分散的,并插入了附近其它语句的指令。识别代表一个函数prolog的结尾,或epilog的开始的代码是有用的。这样调试器可以在载入一个函数的所有实参之后,或在这个函数返回之前停止。某些处理器可以执行多个指令集,因此有另一个列表示在指定的机器位置保存了哪个集。
正如你可能想象的,如果这个表以每条机器指令一行来保存,它将是巨大的。DWARF通过把它编码为一个称作行号程序[1]的指令序列来压缩这个数据。这些指令由一个简单的有限状态机解释来重新构建完整的行号表。
这个有限状态机使用一组缺省值初始化。通过执行行号程序的一个或多个操作码产生这个行号表中的每行。通常这些操作码是相当简单的:例如,向机器地址或行号添加一个值,设置列号,或设置一个标记表示该内存地址代表一个源语句开始、函数prolog结束、或函数epilog开始。一组特别的操作码把最常用的操作(递增内存地址,及递增或递减源代码行号)合并入一个单操作码(a single opcode)。
最后,如果该行号表的一行有与前面的行相同的源代码三元组, 那么在行号程序中不为该行产生指令。图10列出了strndup.c的行号程序。注意仅保存了代表一个语句开始指令的机器地址。在这个代码中编译器不能识别基本块,函数prolog的结尾或epilog的开始。在行号程序中,这个表仅编码为31个字节。
[1] 称这为一个行号程序(line numberprogram)有点用词不当。这个程序描述的比行号要多得多,比如指令集、基本块的开始、函数prolog的结尾等。

图10. strndup.c的行号表
宏信息
大多数调试器很难显示并调试带有宏的代码。用户查看原始的,带有这些宏的源文件,而代码对应这些宏产生的结果。
DWARF包括了定义在这个程序中的宏的描述。这是相当初级的信息,但可以被一个调试器用于显示一个宏的值,或有可能把这个宏翻译回源语言。
调用框信息
每个处理器有某种特定的方式调用函数以及传递实参,这通常定义在ABI里。在最简单的情形中,对于每个函数这都是相同的,并且调试器确切知道如何找到实参的值及函数的返回地址。
对于某些处理器,依赖于该函数如何写,可能有不同的调用序列,例如,如果实参数目多于一个特定的值,取决于操作系统,可能有不同的调用序列。编译器将尝试优化这个调用序列来使得代码既小又快。一个常用的优化是,当有一个简单的、不调用任何其它函数的函数(一个叶子函数)时,让它使用调用者的栈框,而不是构建它自己的。另一个优化可能是消除一个指向当前调用框的寄存器。在这个调用过程中,某些寄存器可能被保留,其它则不会。尽管让调试器推敲出调用序列或优化的所有可能的排列是可能的,但这既枯燥又容易出错。优化及调试器的一个小修改就可能不能在栈中移动到调用函数。
DWARF调用框信息(Call Frame Information——CFI)向调试器提供了足够的关于一个函数如何被调用的信息,因此它可以定位该函数的每个实参、定位当前调用框,以及定位调用函数的调用框。这个信息被调试器用来“回滚栈”,定位前一个函数、该函数被调用的位置,以及传递的值。
类似行号表,CFI被编码为一个将被解释产生一个表的指令序列。在这个表中,包含代码的每个地址对应一行。第一列包含机器地址,而随后的列包含在该地址指令执行时机器寄存器的值。类似于行号表,如果如果构建这个表,它将是巨大的。幸运的是,两个机器指令间的改变非常小,因此CFI编码相当紧凑。
ELF节
虽然DWARF被定义为,允许它与任何目标文件格式一起使用,它最通常与ELF一起使用。每个不同类型的DWARF数据保存在它们自己的节里。所有这些节的名字都以".debug_"开始。为了提升效率,大多数DWARF数据的引用使用到该编译单元数据开头的一个偏移。这避免了重定位这个调试数据,可以加速程序的载入及调试。
ELF节及它们的内容是
.debug_abbrev 用在.debug_info节的缩写
.debug_aranges 内存地址与编译单元之间的一个映射
.debug_frame 调用框信息
.debug_info 包含DIE的核心DWARF数据
.debug_line 行号程序
.debug_loc 宏描述
.debug_macinfo 全局对象及函数的一个查找表
.debug_pubnames 全局对象及函数的一个查找表
.debug_pubtypes 全局类型的一个查找表
.debug_ranges DIE所援引的地址范围
.debug_str 由.debug_info使用的字符串表
总结
现在你应该了解了——DWARF简明扼要的解释。嗯,也不是很简明扼要。DWARF调试信息的基本概念是简单的。一个程序被描述为一棵树,所带的节点以一个紧凑的语言及机器无关的方式表示源代码中的函数、数据及类型。行表提供了可执行指令与产生它们的源代码之间的映射。CFI描述了如何回滚栈。
同样,在DWARF中也有相当多微妙的地方,考虑到要为大范围的程序语言及不同的机器架构表达许多不同的微细差别。DWARF未来的方向是提高对优化代码的描述,这样调试器可以更好地在由先进的编译器优化产生的代码中行进。
完整的DWARF版本3标准在DWARF网站可以免费下载(dwarf.freestandards.org)。还有一个用于DWARF相关问题及讨论的邮件列表。在网站上还有注册这个邮件列表的指引。
致谢
我想感谢Sun Microsystems的ChrisQuenelle,HP前雇员Ron Brender,感谢他们关于这篇文章的意见与建议。同样感谢Susan Heimlich,她给出了很多编辑的建议。
使用GCC产生DWARF
使用gcc产生DWARF非常简单。只要指定–g选项产生调试信息。可以使用带有-h选项的objump来显示ELF节。
$ gcc –g –c strndup.c
$ objdump –h strndup.o
strndup.o: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 0000007b 00000000 00000000 00000034 2**2
CONTENTS,ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 00000000 00000000 000000b0 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 00000000 00000000 000000b0 2**2
ALLOC
3 .debug_abbrev 00000073 00000000 00000000 000000b0 2**0
CONTENTS, READONLY, DEBUGGING
4 .debug_info 00000118 00000000 00000000 00000123 2**0
CONTENTS,RELOC, READONLY, DEBUGGING
5 .debug_line 00000080 00000000 00000000 0000023b 2**0
CONTENTS, RELOC, READONLY, DEBUGGING
6 .debug_frame 00000034 00000000 00000000 000002bc 2**2
CONTENTS, RELOC, READONLY, DEBUGGING
7 .debug_loc 0000002c 00000000 00000000 000002f0 2**0
CONTENTS,READONLY, DEBUGGING
8 .debug_pubnames 0000001e 00000000 00000000 0000031c 2**0
CONTENTS,RELOC, READONLY, DEBUGGING
9 .debug_aranges 00000020 00000000 00000000 0000033a 2**0
CONTENTS, RELOC, READONLY,DEBUGGING
10 .comment 0000002a 00000000 00000000 0000035a 2**0
CONTENTS,READONLY
11 .note.GNU-stack 00000000 00000000 00000000 00000384 2**0
CONTENTS,READONLY
使用Readelf 打印DWARF
Readelf可以显示及解码在一个目标文件或可执行文件中的DWARF数据。这些选项是
-w displayall DWARF sections
-w[liaprmfFso] display specific sections
l line table
i debug info
a abbreviation table
p public names
r ranges
m macro table
f debug frame (encoded)
F debug frame (decoded)
s string table
o location lists
列出的DWARF,即使最小的程序也是相当多的,因此把readelf的输出重定向到一个文件,然后使用less或一个编辑器,比如vi,来浏览这个文件,是个好主意。