Cracking the Coding Interview 150题(一)
1、数组与字符串
1.1 实现一个算法,确定一个字符串的所有字符是否全都不同。假设不允许使用额外的数据结构,又该如何处理?
1.2 用C或C++实现void reverse(char* str)函数,即反转一个null结尾的字符串。
1.3 给定两个字符串,请编写程序,确定其中一个字符串的字符重新排列后,能否变成另一个字符串。
1.4 编写一个方法,将字符串中的空格全部替换为“%20”。假设该字符串尾部有足够的空间存放新增字符,并且知道字符串的“真实”长度。示例:输入Mr John Smith,输出Mr%20John%20Smith。
1.5 利用字符重复出现的次数,编写一个方法,实现基本的字符串压缩功能。比如,字符串aabcccccaaa会变为a2b1c5a3。若“压缩”后的字符串没有变短,则返回原先的字符串。
1.6 给定一幅由 N x N 矩阵表示的图像,其中每个像素的大小为 4 字节,编写一个方法,将图像旋转90度。不占用额外内存空间能否做到?
1.7 编写一个算法,若 M x N 矩阵中某个元素为0,则将其所在的行与列清零。
1.8 假定有一个方法isSubstring,可检查一个单词是否为其他字符串的子串。给定两个字符串 s1 和 s2,请编写代码检查 s2 是否为 s1 旋转而成,要求只能调用一次isSubstring。(比如,waterbottle是erbottlewat旋转后的字符串。)
2、链表
2.1 编写代码,移除未排序链表中的重复结点。如果不得使用临时缓冲区,又该怎么解决?
2.2 实现一个算法,找出单向链表中倒数第 k 个结点。
2.3 实现一个算法,删除单向链表中间的某个结点,假定你只能访问该结点。示例:
- 输入:单向链表
a->b->c->d->e中的结点c - 结果:不返回任何数据,但该链表变为
a->b->d->e。
2.4 编写代码,以给定值x为基准将链表分割成两部分,所有小于x的结点排在大于或等于x的结点之前。
2.5 给定两个用链表表示的整数,每个结点包含一个数位。这些数位是反向存放的,也就是个位排在链表首部。编写函数对这两个整数求和,并用链表形式返回结果。示例:
- 输入:(
7->1->6)+(5->9->2),即 617+295 - 输出:
2->1->9,即 912
假设这些数位是正向存放的,请再做一遍。示例:
- 输入:(
6->1->7)+(2->9->5),即 617+295 - 输出:
9->1->2,即 912
2.6 给定一个有环链表,实现一个算法返回环路的开头结点。有环链表的定义:在链表中某个结点的 next 元素指向在它前面出现过的结点,则表明该链表存在环路。示例:
- 输入:
A->B->C->D->E->C(C结点出现了两次) - 输出:C
2.7 编写一个函数,检查链表是否为回文。
参考答案(C++)
1.1 如果允许使用数据结构,我首先想到的是map,下标操作map['key']在 key 存在时执行搜索操作,否则执行插入操作。示例代码如下:
bool func(char A[], int len)
{
map<char, int> amap;
for(int i=0; i<len; ++i)
{
amap[A[i]] += 1;
}
map<char, int>::iterator beg = amap.begin();
for(;beg!=amap.end(); ++beg)
{
if(beg->second > 1)
return false;
}
return true;
}如果不允许使用额外的数据结构,该如何处理呢?假定字符集为 ASCII,那么我们可以创建一个标记数组,索引 i 对应的 bool 值指示该字符串是否含有字母表第 i 个字符。若这个字符第二次出现,则立即返回 false。
bool func(char A[], int len) // 假定字符集为 ASCII
{
if(len > 256)
return false;
bool char_set[256] = {false};
for(int i=0; i<len; ++i)
{
if(char_set[A[i]]) // 字符已经出现过
return false;
char_set[A[i]] = true;
}
return true;
}
1.2 根据函数的原型void reverse(char* str),我们并不知道字符串的长度,所以需要先求出长度再进行反转:
void reverse(char* str)
{
char* tmp = str;
int len = 0;
while(*tmp++ != '\0') // 求出字符串的长度
++len;
int low = 0;
int high = len - 1;
while(low < high) // 反转
{
char c = str[low];
str[low] = str[high];
str[high] = c;
++low;
--high;
}
}
1.3 由题意可知,这是一个变位词的问题,可以看我的另一篇文章《变位词问题》。通常的做法是把两个字符串按字母表顺序排序,比较排序后的字符串是否相等:
bool myfunction(char i, char j)
{
return i > j;
}
bool Compare(string s1, string s2)
{
if(s1.length() != s2.length())
return false;
// 泛型算法 sort() 采用的是快速排序算法
sort(s1.begin(), s1.end(), myfunction);
sort(s2.begin(), s2.end(), myfunction);
if(!s1.compare(s2)) // 相等返回0
return true;
else
return false;
}另外一种方法就是:检查两个字符串的各字符数是否相同。(假定字符集为ASCII)我们只需创建一个大小 256 的整型数组,遍历第一个字符串,给每个字符计数;遍历第二个字符串,递减对应字符的数量。最后判断数组元素是否全部为0。
1.4 本题的思路就是进行两次扫描。第一次扫描记录字符串中有多少空格,从而计算最终字符串的长度;第二次扫描从后往前移动字符并插入20%。代码如下:
void replaceSpace(char *str, int len)
{
int spaceNum = 0;
for(int i=0; i<len; ++i)
{
if(str[i] == ' ')
++spaceNum;
}
int newLen = len + spaceNum*2;
for(int i=len-1; i>=0; --i)
{
if(str[i] != ' ')
{
str[newLen - 1] = str[i];
newLen = newLen - 1;
}
else
{
str[newLen - 1] = '0';
str[newLen - 2] = '2';
str[newLen - 3] = '%';
newLen = newLen - 3;
}
}
}
1.5 本题思路很简单:遍历字符串,将字符和对应的重复次数拷贝到新字符串。
// int转string
string int2string(int n)
{
stringstream ss;
string str;
ss << n;
ss >> str;
return str;
}
string compress(string str)
{
string tmp;
char c = str[0];
int count = 1;
for(int i=1; i<str.length(); ++i)
{
if(str[i] == c)
++count;
else
{
tmp = tmp + c + int2string(count);
c = str[i];
count = 1;
}
}
tmp = tmp + c + int2string(count);
return str.length()>tmp.length() ? tmp:str;
}
1.6 归纳题意,简言之就是:对N阶方阵进行原地转置。(思路就是对每一层执行环状旋转,将上边移到右边、右边移到下边、下边移到左边、左边移到上边)
void rotate(int **mtx, int n)
{
for(int layer=0; layer < n/2; ++layer)
{
int first = layer;
int last = n-1-layer;
for(int i=first; i<last; ++i)
{
int offset = i - first;
// 暂存上边:top = mtx[first][i]
int top = *((int*)mtx+first*n+i);
// 左到上:mtx[first][i] = mtx[last-offset][first]
*((int*)mtx+first*n+i) = *((int*)mtx+(last-offset)*n+first);
// 下到左:mtx[last-offset][first] = mtx[last][last-offset]
*((int*)mtx+(last-offset)*n+first) = *((int*)mtx+last*n+(last-offset));
// 右到下:mtx[last][last-offset] = mtx[i][last]
*((int*)mtx+last*n+(last-offset)) = *((int*)mtx+i*n+last);
// 上到右:mtx[i][last] = top
*((int*)mtx+i*n+last) = top;
}
}
}这里要注意二维数组作参数传递的问题,另外调用的时候像这样rotate((int**)A, 4)。这个算法的时间复杂度为O(n^2),已是最优的做法。
1.7 这个问题貌似很简单,直接遍历嘛!只要发现为零的元素,就将其所在的行与列清零。不过这个方法有个陷阱:清零以后会导致连锁效应,最后整个矩阵都变成 0。我们的做法是:遍历两遍,第一遍记录要清零的行与列,第二遍再执行清零操作。
void setZero(int **mtx, int m, int n)
{
bool *row = new bool[m](); // 默认初始化为false
bool *col = new bool[n]();
for(int i=0; i<m; ++i)
for(int j=0; j<n; ++j)
{
if(*((int*)mtx+i*n+j) == 0)
{
row[i] = true;
col[j] = true;
}
}
for(int i=0; i<m; ++i)
for(int j=0; j<n; ++j)
{
if(row[i] || col[j])
{
*((int*)mtx+i*n+j) = 0;
}
}
delete [] row;
delete [] col;
}
1.8 如果x = wat,y = erbottle,则s1 = xy,s2 = yx。不论x和y之间的分割点在何处,我们会发现yx肯定是xyxy的子串。即,s2总是s1s1的子串。
bool isRotation(string s1, string s2)
{
if(s1.length() == s2.length() && s1.length()>0)
{
return isSubstring(s1+s1, s2);
}
return false;
}
在解决链表问题时,首先我们得学会如何创建链表,下面是单链表创建和打印的示例代码:
typedef struct node
{
node* next;
int data;
} *LinkList;
// 根据数组创建单链表:尾插法
LinkList createList(int A[], int len)
{
int i = 0;
node *head = (node*)malloc(sizeof(node));
node *s, *tail = head;
while(i<len)
{
s = (node*)malloc(sizeof(node));
s->data = A[i++];
tail->next = s;
tail = s;
}
tail->next = NULL;
return head; /*头结点不保存数据*/
}
// 打印单链表
void printList(LinkList L)
{
node *p = L->next;
while(p!=NULL)
{
cout << p->data;
p = p->next;
if(p!=NULL)
cout << "->";
}
cout << endl;
}
2.1 要想移除链表中的重复结点,我们只需在遍历的过程中,将每个未重复结点加入一个缓冲区。若发现有结点在缓冲区已经存在(即重复),则将该结点从链表中移除。只需遍历一次即可。
void deleteDups(LinkList L)
{
set<int> buffer; // 这里使用set容器
node *p = L->next;
node *pre = L;
while(p!=NULL)
{
int data = p->data;
if(buffer.find(data) == buffer.end())
{
buffer.insert(data);
pre = p;
p = p->next;
}
else /* 重复 */
{
pre->next = p->next;
node* q = p; // 记录删除的结点
p = p->next;
free(q); // 释放
}
}
}如果不借助额外的缓冲区,那么就只能两两比较以判断是否重复,时间复杂度为O(n^2)。需要使用两个指针来迭代:
void deleteDups(LinkList L)
{
if(L == NULL) return;
node* current = L->next;
while(current!=NULL)
{
node* runner = current;
while(runner->next!=NULL)
{
if(runner->next->data == current->data)
{
node* p = runner->next;
runner->next = runner->next->next;
free(p);
}
else
{
runner = runner->next;
}
}
current = current->next;
}
}
2.2 本题有多种解法。
解法一:有人可能首先会想到:这太简单了,先遍历一次链表获取长度 length,那么倒数第 k 个结点就是第 (length - k)个结点。但是,你觉得这会是面试官想要的答案吗??
解法二:递归。先通过递归到达链表的末尾,然后从后往前进行计数,每次递归调用返回时,将计数器加1。当计数器等于 k 时,访问的就是链表倒数第 k 个元素。(注意计数器 i 需要传引用)
node* kthToLast(node* head, int k, int &i)
{
if(head == NULL)
return NULL;
node* p = kthToLast(head->next, k, i);
i = i + 1;
if(i == k)
{
return head;
}
return p;
}- 解法三:迭代法。相比于递归,迭代法通常不太直观但效率更高。思路就是:用两个指针 p1 和 p2 指向链表中两个距离为k的结点,然后以相同速度移动这两个指针,当其中一个指针指向链表的尾结点时,另一个指针指向的就是倒数第k个结点。(“快行指针”技巧)
node* kthToLast(LinkList L, int k) // 时间复杂度O(n),空间复杂度O(1)
{
if(k<=0)
return NULL;
// 两个指针
node* p1 = L->next;
node* p2 = L->next;
// p2向前移动k个结点
for(int i=0; i<k-1; ++i)
{
if(p2 == NULL) /*错误检查*/
return NULL;
p2 = p2->next;
}
if(p2 == NULL) return NULL;
// 移动p1与p2
while(p2->next!=NULL)
{
p1 = p1->next;
p2 = p2->next;
}
return p1;
}
2.3 本题中,你访问不到链表的首结点,只能访问待删除结点及之后的结点。所以我们的做法是:直接将后继结点的数据复制到当前结点,然后删除这个后继结点。
bool deleteNode(node* c)
{
if(c==NULL || c->next==NULL) // 尾结点无法删除
return false;
node* next = c->next;
c->data = next->data;
c->next = next->next;
free(next);
return true;
}
2.4 链表不同于数组,在用现有元素创建新的链表时,我们不必移动和交换元素,只是改变元素的 next 指针的指向。所以本题的思路也很简单:遍历链表,将小于 x 的元素连接成一个链表,将大于等于 x 的元素连接成一个链表,最后合并两个链表即可。
LinkList partition(LinkList L, int x)
{
node* biggerHead = NULL;
node* biggerTail = NULL;
node* smallerHead = NULL;
node* smallerTail = NULL;
node* p = L->next;
while(p!=NULL)
{
node* next = p->next;
p->next = NULL;
if(p->data < x)
{ /*将比x小的结点插入smaller链表的尾部*/
if(smallerHead == NULL)
{
smallerHead = p;
smallerTail = smallerHead;
}
else
{
smallerTail->next = p;
smallerTail = p;
}
}
else
{ /*将比x大的结点插入bigger链表的尾部*/
if(biggerHead == NULL)
{
biggerHead = p;
biggerTail = biggerHead;
}
else
{
biggerTail->next = p;
biggerTail = p;
}
}
p = next;
}
/*遍历结束,合并两个链表*/
if(smallerHead == NULL)
{
L->next = biggerHead;
return L;
}
smallerTail->next = biggerHead;
L->next = smallerHead;
return L;
}
2.5 本题的思路是逐个结点对应相加,然后判断是否进位。我们使用递归来模拟这个加法过程。
LinkList add(LinkList L1, LinkList L2, int carry)
{
/*两个链表全部为空且进位为0,则函数返回*/
if(L1==NULL && L2==NULL && carry==0)
return NULL;
node* result = (node*)malloc(sizeof(node));
int value = carry;
if(L1!=NULL)
value+=L1->data;
if(L2!=NULL)
value+=L2->data;
result->data = value%10; /*取个位*/
node* more = add(L1==NULL?NULL:L1->next,
L2==NULL?NULL:L2->next,
value>=10?1:0);
result->next = more;
return result;
}注意,这里add之后返回的链表没有“头指针”。
2.6 这个问题是由经典面试题——检查链表是否存在回路——演变而来。
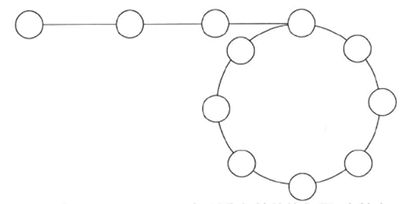
如上图所示,如果链表中存在回路,那么我们遍历时会陷入死循环。那么,我们如何检测链表是否存在环 以及 寻找环的入口点呢?答案是“快慢指针”。
① 设置两个指针(fast、slow),初始值都指向头,slow每次前进一步,fast每次前进二步。如果链表存在环,则fast必定先进入环,而slow后进入环,两个指针必定相遇。这是检测。
② 在fast和slow第一次相遇的时候,假定slow走了n步,环路的入口是在p步,
c为fast和slow相交点距离环路入口的距离。那么,slow走的路径: p+c = n;
fast走的路径: p+c+k*L = 2*n(L为环路的周长,k是整数),即n = k*L
显然,如果从p+c点开始,slow再走n步的话,还可以回到p+c这个点。
同时,fast从头开始走,步长为1,经过n步,也会达到p+c这点。
显然,在这个过程中fast和slow只有前p步骤走的路径不同。所以当p1和p2再次重合的时候,必然是在链表的环路入口点上。
③ 综上所述,可得出如下算法:
创建两个指针:fast和slow
slow每走一步,fast就走两步
两者碰在一起时,将slow重新指向链表头,fast保持不变
以相同速度移动slow和fast,一次一步,然后返回新的碰撞处。
node* findLoopEntrance(LinkList L)
{
node* slow = L->next;
node* fast = L->next;
while(fast!=NULL && fast->next!=NULL)
{
slow = slow->next;
fast = fast->next->next;
if(fast == slow) /*碰撞*/
break;
}
if(fast==NULL || fast->next==NULL)
return NULL; /*没有环路*/
slow = L->next; /*重新指向链表头*/
while(slow!=fast)
{
slow = slow->next;
fast = fast->next;
}
return fast;
}
2.7 所谓“回文”指正向看和反向看是一样的。在链表中可以定义为 0->1->2->1->0。
解法一:根据定义,先将整个链表反转,然后比较反转链表和原始链表。若两者相同,则该链表为回文。(只需比较链表的前半部分)
解法二:迭代法。先进行迭代,将链表的前半部分入栈,再继续进行迭代,与后半部分进行比较。每次迭代时,比较当前结点和栈顶元素,若完成迭代时比较结果完全相同,则该链表为回文。(在链表长度未知的情况下,可以使用“快慢指针”将前半部分入栈)
bool isPalindrome(LinkList L)
{
node* fast = L->next;
node* slow = L->next;
stack<int> s;
/**将链表的前半部分入栈**/
while(fast!=NULL && fast->next!=NULL)
{
s.push(slow->data);
slow = slow->next;
fast = fast->next->next;
}
/**链表有奇数个元素,跳过中间元素**/
if(fast!=NULL)
slow = slow->next;
/**比较**/
while(slow!=NULL)
{
int top = s.top();
s.pop();
if(top!=slow->data)
return false;
slow = slow->next;
}
return true;
}
个人站点:http://songlee24.github.com