GCC-3.4.6源代码学习笔记(82)
5.9. 试探性的解析器
5.9.1. 概观
当前GCC实现的是一个试探性的C++解析器,由于C++并不是严格的上下文无关文法,解析器可能需要多次尝试才能成功解析。因此解析器需要的是窥视功能——看看自己的理解对不对,不对从头重新解读。这个窥视功能可由cp_lexer_peek_token提供。
643 static cp_token *
644 cp_lexer_peek_token (cp_lexer * lexer) in parser.c
645 {
646 cp_token *token;
647
648 /* If there are no tokens, read one now. */
649 if (!lexer->next_token)
650 cp_lexer_read_token (lexer);
651
652 /* Provide debugging output. */
653 if (cp_lexer_debugging_p (lexer))
654 {
655 fprintf (cp_lexer_debug_stream, "cp_lexer: peeking at token: ");
656 cp_lexer_print_token (cp_lexer_debug_stream, lexer->next_token);
657 fprintf (cp_lexer_debug_stream, "/n");
658 }
659
660 token = lexer->next_token;
661 cp_lexer_set_source_position_from_token (lexer, token);
662 return token;
663 }
这里的C++解析器是LL(n)形式的,而不是传统的LL(1)形式。向前窥视第n个符号的功能由更为强大的函数cp_lexer_peek_nth_token提供。
702 static cp_token *
703 cp_lexer_peek_nth_token (cp_lexer* lexer, size_t n) in parser.c
704 {
705 cp_token *token;
706
707 /* N is 1-based, not zero-based. */
708 my_friendly_assert (n > 0, 20000224);
709
710 /* Skip ahead from NEXT_TOKEN, reading more tokens as necessary. */
711 token = lexer->next_token;
712 /* If there are no tokens in the buffer, get one now. */
713 if (!token)
714 {
715 cp_lexer_read_token (lexer);
716 token = lexer->next_token;
717 }
718
719 /* Now, read tokens until we have enough. */
720 while (--n > 0)
721 {
722 /* Advance to the next token. */
723 token = cp_lexer_next_token (lexer, token);
724 /* If that's all the tokens we have, read a new one. */
725 if (token == lexer->last_token)
726 token = cp_lexer_read_token (lexer);
727 }
728
729 return token;
730 }
函数cp_lexer_peek_token,cp_lexer_peek_nth_token及cp_lexer_read_token都不移动first_token。当我们确认无疑地知道某个符号的含义时(比如,关键字),这个符号就不应该再出现在下一次的尝试中。这意味着该符号已经被“消化了”,“消化”符号的函数就是cp_lexer_consume_token。
737 static cp_token *
738 cp_lexer_consume_token (cp_lexer* lexer) n parser.c
739 {
740 cp_token *token;
741
742 /* If there are no tokens, read one now. */
743 if (!lexer->next_token)
744 cp_lexer_read_token (lexer);
745
746 /* Remember the token we'll be returning. */
747 token = lexer->next_token;
748
749 /* Increment NEXT_TOKEN. */
750 lexer->next_token = cp_lexer_next_token (lexer,
751 lexer->next_token);
752 /* Check to see if we're all out of tokens. */
753 if (lexer->next_token == lexer->last_token)
754 lexer->next_token = NULL;
755
756 /* If we're not saving tokens, then move FIRST_TOKEN too. */
757 if (!cp_lexer_saving_tokens (lexer))
758 {
759 /* If there are no tokens available, set FIRST_TOKEN to NULL. */
760 if (!lexer->next_token)
761 lexer->first_token = NULL;
762 else
763 lexer->first_token = lexer->next_token;
764 }
765
766 /* Provide debugging output. */
767 if (cp_lexer_debugging_p (lexer))
768 {
769 fprintf (cp_lexer_debug_stream, "cp_lexer: consuming token: ");
770 cp_lexer_print_token (cp_lexer_debug_stream, token);
771 fprintf (cp_lexer_debug_stream, "/n");
772 }
773
774 return token;
775 }
cp_lexer 中的域next_token总是指向下一个被“消化”的符号,因此在750行,把该域指向的符号向前推进一个。而域last_token是所缓存符号的结尾标记,当next_token推进到这个位置时,next_token被设为NULL以表示没有符号剩下了。
而在757行,cp_lexer_saving_tokens检查cp_lexer中的可变长数组saved_tokens是否不为空。如果不空,表示符号按照解析器的要求要被保留(由cp_lexer_save_tokens触发),否则,推进域first_token来释放符号所占用的空间。
尝试性的解析由函数cp_parser_parse_tentatively拉开序幕。首先是为这次的尝试准备一个解析器上下文。在后面的操作中,编译器看到这个上下文,就知道正在进行尝试性解析。通过这样的上下文栈,尝试性解析可以多层嵌套。
15388 static void
15389 cp_parser_parse_tentatively (cp_parser* parser) in parser.c
15390 {
15391 /* Enter a new parsing context. */
15392 parser->context = cp_parser_context_new (parser->context);
15393 /* Begin saving tokens. */
15394 cp_lexer_save_tokens (parser->lexer);
15395 /* In order to avoid repetitive access control error messages,
15396 access checks are queued up until we are no longer parsing
15397 tentatively. */
15398 push_deferring_access_checks (dk_deferred);
15399 }
接下来在15398行,一个新的访问控制项被加入deferred_access_stack。这个一个延迟检查项,因为解析器将要到来的符号代表什么,只能尽各种可能来识别它们。其间可能会有多次尝试,在尝试期间不需要进行访问检查。访问检查将在完成尝试性解析时执行,在那个时候,解析器应该已经知道这些符号代表什么。
我们已经看到,在cp_lexer中,域first_token指向第一个被窥视的符号,而last_token指向最后一个缓存符号的位置,next_token则指向下一个将被窥视的符号。因此,在 first_token和next_token之间的符号是已经被窥视的,而在next_token和last_token之间的,是将要窥视的符号(如果first_token不等于next_token,这意味着我们在一个嵌套的尝试性解析中)。注意到在这次解析的过程中,first_token也不会被改变,因而如果我们需要重新解析,只要恢复next_token就足够了。这就是为什么cp_lexer_save_tokens只记录first_token到 next_token的距离(由函数cp_lexer_token_difference获得)。
844 static void
845 cp_lexer_save_tokens (cp_lexer* lexer) in parser.c
846 {
847 /* Provide debugging output. */
848 if (cp_lexer_debugging_p (lexer))
849 fprintf (cp_lexer_debug_stream, "cp_lexer: saving tokens/n");
850
851 /* Make sure that LEXER->NEXT_TOKEN is non-NULL so that we can
852 restore the tokens if required. */
853 if (!lexer->next_token)
854 cp_lexer_read_token (lexer);
855
856 VARRAY_PUSH_INT (lexer->saved_tokens,
857 cp_lexer_token_difference (lexer,
858 lexer->first_token,
859 lexer->next_token));
860 }
在调用了cp_lexer_save_tokens后,域saved_tokens不再是空的。回过去看函数cp_lexer_consume_token,save_tokens域不空,将使得没有符号被“消化”(first_token不像通常那样被推进)。
通过串接尝试性解析,我们可以把一个大的尝试性解析分成多个小的尝试性解析。例如,我们要解析一个由3个语法成分组成的语句,假定这3部分可能的组合如下图。
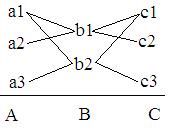
那么我们就可以把这个大的尝试分解为3个小的独立的尝试A,B和C。假如,现在输入的语句是a1b1c2,尝试A首先成功,接下来尝试B、C也成功,那么A,B,C构成的大尝试也就成功了。这时,通过cp_parser_commit_to_tentative_parse来提交这些尝试。假如输入的是a1b1c3,那么尝试C返回与a1b1不相容的c3,解析则失败。尝试C的上下文将被标记为CP_PARSER_STATUS_KIND_ERROR。
15403 static void
15404 cp_parser_commit_to_tentative_parse (cp_parser* parser) in parser.c
15405 {
15406 cp_parser_context *context;
15407 cp_lexer *lexer;
15408
15409 /* Mark all of the levels as committed. */
15410 lexer = parser->lexer;
15411 for (context = parser->context; context->next; context = context->next)
15412 {
15413 if (context->status == CP_PARSER_STATUS_KIND_COMMITTED)
15414 break;
15415 context->status = CP_PARSER_STATUS_KIND_COMMITTED;
15416 while (!cp_lexer_saving_tokens (lexer))
15417 lexer = lexer->next;
15418 cp_lexer_commit_tokens (lexer);
15419 }
15420 }
看到cp_lexer_commit_tokens将从save_tokens弹出一个对象,而15411行的FOR循环将横扫所有未提交的上下文,因此在cp_lexer_consume_token的下一次调用中,将把first_token更新为next_token。如果尝试性解析没有开始过,该FOR循环将不执行就退出,因为主上下文的next域总是为null。
864 static void
865 cp_lexer_commit_tokens (cp_lexer* lexer) in parser.c
866 {
867 /* Provide debugging output. */
868 if (cp_lexer_debugging_p (lexer))
869 fprintf (cp_lexer_debug_stream, "cp_lexer: committing tokens/n");
870
871 VARRAY_POP (lexer->saved_tokens);
872 }
注意到虽然提交了尝试性解析,但它们的上下文并没有释放。只有退出了它们的上下文,解析才被认为完成。另外,如果在解析过程中发生错误,我们需要停止解析,并回滚到解析开始的地方,准备下一次的尝试。要停止解析并从其上下文退出,我们需要调用函数cp_parser_parse_definitely。同样看到如果解析已经被提交,它几乎就是不活动的。
15438 static bool
15439 cp_parser_parse_definitely (cp_parser* parser) in parser.c
15440 {
15441 bool error_occurred;
15442 cp_parser_context *context;
15443
15444 /* Remember whether or not an error occurred, since we are about to
15445 destroy that information. */
15446 error_occurred = cp_parser_error_occurred (parser);
15447 /* Remove the topmost context from the stack. */
15448 context = parser->context;
15449 parser->context = context->next;
15450 /* If no parse errors occurred, commit to the tentative parse. */
15451 if (!error_occurred)
15452 {
15453 /* Commit to the tokens read tentatively, unless that was
15454 already done. */
15455 if (context->status != CP_PARSER_STATUS_KIND_COMMITTED)
15456 cp_lexer_commit_tokens (parser->lexer);
15457
15458 pop_to_parent_deferring_access_checks ();
15459 }
15460 /* Otherwise, if errors occurred, roll back our state so that things
15461 are just as they were before we began the tentative parse. */
15462 else
15463 {
15464 cp_lexer_rollback_tokens (parser->lexer);
15465 pop_deferring_access_checks ();
15466 }
15467 /* Add the context to the front of the free list. */
15468 context->next = cp_parser_context_free_list;
15469 cp_parser_context_free_list = context;
15470
15471 return !error_occurred;
15472 }
在cp_parser_parse_tentatively中,在开始尝试性解析时,我们推迟了访问控制检查。现在在停止该解析时,如果解析成功,那么是时候执行这个延迟的检查;如果解析失败,仍然需要移除这个延迟检查,让下一次尝试自己来处理访问控制。
216 void
217 pop_to_parent_deferring_access_checks (void) in semantics.c
218 {
219 tree deferred_check = get_deferred_access_checks ();
220 deferred_access *d1 = deferred_access_stack;
221 deferred_access *d2 = deferred_access_stack->next;
222 deferred_access *d3 = deferred_access_stack->next->next;
223
224 /* Temporary swap the order of the top two states, just to make
225 sure the garbage collector will not reclaim the memory during
226 processing below. */
227 deferred_access_stack = d2;
228 d2->next = d1;
229 d1->next = d3;
230
231 for ( ; deferred_check; deferred_check = TREE_CHAIN (deferred_check))
232 /* Perform deferred check if required. */
233 perform_or_defer_access_check (TREE_PURPOSE (deferred_check),
234 TREE_VALUE (deferred_check));
235
236 deferred_access_stack = d1;
237 d1->next = d2;
238 d2->next = d3;
239 pop_deferring_access_checks ();
240 }
我们已经看到deferred_access_stack是类型为deferred_access的栈。栈中的每个节点分别代表应用了延迟访问检查的作用域,而节点中的域deferred_access_checks记录了该作用域中所请求的延迟检查。函数get_deferred_access_checks返回当前作用域的延迟检查。
206 tree
207 get_deferred_access_checks (void) in semantics.c
208 {
209 return deferred_access_stack->deferred_access_checks;
210 }
在下一节我们再来看函数perform_or_defer_access_check。在执行完这些延迟检查后,从该栈中弹出这些检查。
187 void
188 pop_deferring_access_checks (void) in semantics.c
189 {
190 deferred_access *d = deferred_access_stack;
191 deferred_access_stack = d->next;
192
193 /* Remove references to access checks TREE_LIST. */
194 d->deferred_access_checks = NULL_TREE;
195
196 /* Store in free list for later use. */
197 d->next = deferred_access_free_list;
198 deferred_access_free_list = d;
199 }
在出错时回滚到起点由cp_lexer_rollback_tokens完成。
877 static void
878 cp_lexer_rollback_tokens (cp_lexer* lexer) in parser.c
879 {
880 size_t delta;
881
882 /* Provide debugging output. */
883 if (cp_lexer_debugging_p (lexer))
884 fprintf (cp_lexer_debug_stream, "cp_lexer: restoring tokens/n");
885
886 /* Find the token that was the NEXT_TOKEN when we started saving
887 tokens. */
888 delta = VARRAY_TOP_INT(lexer->saved_tokens);
889 /* Make it the next token again now. */
890 lexer->next_token = cp_lexer_advance_token (lexer,
891 lexer->first_token,
892 delta);
893 /* It might be the case that there were no tokens when we started
894 saving tokens, but that there are some tokens now. */
895 if (!lexer->next_token && lexer->first_token)
896 lexer->next_token = lexer->first_token;
897
898 /* Stop saving tokens. */
899 VARRAY_POP (lexer->saved_tokens);
900 }
因为在尝试性解析的过程中没有符号被真正“消化”,first_token总是不变的,获取起点时的next_token可谓直截了当。
449 static cp_token *
450 cp_lexer_advance_token (cp_lexer *lexer, cp_token *token, ptrdiff_t n) in parser.c
451 {
452 token += n;
453 if (token >= lexer->buffer_end)
454 token = lexer->buffer + (token - lexer->buffer_end);
455 return token;
456 }
在这里,可以很清楚地看到,cp_parser_parse_tentatively及cp_parser_parse_definitely的调用必需一一对应,以维护延迟检查栈的良好状态。