数据结构(15)--哈夫曼树以及哈夫曼编码的实现
参考书籍:数据结构(C语言版)严蔚敏吴伟民编著清华大学出版社
1.哈夫曼树
假设有n个权值{w1, w2, ..., wn},试构造一棵含有n个叶子结点的二叉树,每个叶子节点带权威wi,则其中带权路径长度WPL最小的二叉树叫做最优二叉树或者哈夫曼树。
特点:哈夫曼树中没有度为1的结点,故由n0 = n2+1以及m= n0+n1+n2,n1=0可推出m=2*n0-1,即一棵有n个叶子节点的哈夫曼树共有2n-1个节点。
2.哈夫曼编码
通信传送的目标是使总码长尽可能的短。
变长编码的原则:
1.使用频率高的字符用尽可能短的编码(这样可以减少数据传输量);
2.任一字符的编码都不能作为另一个字符编码的开始部分(这样就使得在两个字符的编码之间不需要添加分隔符号)。这种编码称为前缀编码。
根据每种字符在电文中出现的次数构造哈夫曼树,将哈夫曼树中每个分支结点的左分支标上0,右分支标上1,把从根结点到每个叶子结点的路径上的标号连接起来,作为叶结点所代表的字符的编码。这样得到的编码称为哈夫曼编码。
思考:为什么哈夫曼编码符合变长编码的原则?哈夫曼树所构造出的编码的长度是不是最短的?
哈夫曼树求得编码为最优前缀码的原因: 在构造哈夫曼树的过程中:
1.权值大的在上层,权值小的在下层。满足出现频率高的码长短。
2.树中没有一片叶子是另一叶子的祖先,每片叶子对应的编码就不可能是其它叶子编码的前缀。即上述编码是二进制的前缀码。
假设每种字符在电文中出现的次数为wi (出现频率即为权值),其码长为li,电文中只有n种字符,则编码后电文总码长为,而哈夫曼树是WPL最小的二叉树,因此哈夫曼编码的码长最小。
3.哈夫曼编码实例
四种字符以及他们的权值:a:30, b:5, c:10, d:20
第一步:构建哈夫曼树
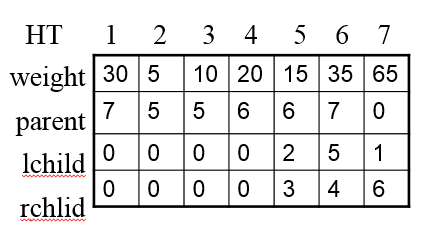
第二步:为哈夫曼树的每一条边编码
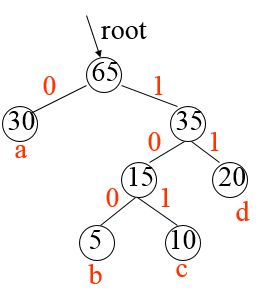
第三步:生成哈夫曼编码表
4.代码实现
4.1哈夫曼树定义
哈夫曼树的存储结构:采用静态三叉链表
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define N 4//带权值的叶子节点数或者是需要编码的字符数
#define M 2*N-1//n个叶子节点构造的哈夫曼树有2n-1个结点
#define MAX 10000
typedef char TElemType;
//静态三叉链表存储结构
typedef struct{
//TElemType data;
unsigned int weight;//权值只能是正数
int parent;
int lchild;
int rchild;
}HTNode;//, *HuffmanTree;
typedef HTNode HuffmanTree[M+1];//0号单元不使用
typedef char * HuffmanCode[N+1];//存储每个字符的哈夫曼编码表,是一个字符指针数组,每个数组元素是指向字符指针的指针
4.2构造哈夫曼树
//构造哈夫曼树
void createHuffmanTree(HuffmanTree &HT, int *w, int n){
if(n <= 1)
return;
//对树赋初值
for(int i = 1; i <= n; i++){//HT前n个分量存储叶子节点,他们均带有权值
HT[i].weight = w[i];
HT[i].lchild = 0;
HT[i].parent = 0;
HT[i].rchild = 0;
}
for(; i <=M; i++){//HT后m-n个分量存储中间结点,最后一个分量显然是整棵树的根节点
HT[i].weight = 0;
HT[i].lchild = 0;
HT[i].parent = 0;
HT[i].rchild = 0;
}
//开始构建哈夫曼树,即创建HT的后m-n个结点的过程,直至创建出根节点。用哈夫曼算法
for(i = n+1; i <= M; i++){
int s1, s2;
select(HT, i-1, s1, s2);//在HT[1...i-1]里选择parent为0的且权值最小的2结点,其序号分别为s1,s2,parent不为0说明该结点已经参与构造了,故不许再考虑
HT[s1].parent = i;
HT[s2].parent = i;
HT[i].lchild = s1;
HT[i].rchild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
}
//在HT[1...k]里选择parent为0的且权值最小的2结点,其序号分别为s1,s2,parent不为0说明该结点已经参与构造了,故不许再考虑
void select(HuffmanTree HT, int k, int &s1, int &s2){
//假设s1对应的权值总是<=s2对应的权值
unsigned int tmp = MAX, tmpi = 0;
for(int i = 1; i <= k; i++){
if(!HT[i].parent){//parent必须为0
if(tmp > HT[i].weight){
tmp = HT[i].weight;//tmp最后为最小的weight
tmpi = i;
}
}
}
s1 = tmpi;
tmp = MAX;
tmpi = 0;
for(i = 1; i <= k; i++){
if((!HT[i].parent) && i!=s1){//parent为0
if(tmp > HT[i].weight){
tmp = HT[i].weight;
tmpi = i;
}
}
}
s2 = tmpi;
}
打印哈夫曼树
//打印哈夫曼满树
void printHuffmanTree(HuffmanTree HT, char ch[]){
printf("\n");
printf("data, weight, parent, lchild, rchild\n");
for(int i = 1; i <= M; i++){
if(i > N){
printf(" -, %5d, %5d, %5d, %5d\n", HT[i].weight, HT[i].parent, HT[i].lchild, HT[i].rchild);
}else{
printf(" %c, %5d, %5d, %5d, %5d\n", ch[i], HT[i].weight, HT[i].parent, HT[i].lchild, HT[i].rchild);
}
}
printf("\n");
}
4.3编码
为哈夫曼树的每一条分支编码,并生成哈夫曼编码表HC
//为每个字符求解哈夫曼编码,从叶子到根逆向求解每个字符的哈夫曼编码
void encodingHuffmanCode(HuffmanTree HT, HuffmanCode &HC){
//char *tmp = (char *)malloc(n * sizeof(char));//将每一个字符对应的编码放在临时工作空间tmp里,每个字符的编码长度不会超过n
char tmp[N];
tmp[N-1] = '\0';//编码的结束符
int start, c, f;
for(int i = 1; i <= N; i++){//对于第i个待编码字符即第i个带权值的叶子节点
start = N-1;//编码生成以后,start将指向编码的起始位置
c = i;
f = HT[i].parent;
while(f){//f!=0,即f不是根节点的父节点
if(HT[f].lchild == c){
tmp[--start] = '0';
}else{//HT[f].rchild == c,注意:由于哈夫曼树中只存在叶子节点和度为2的节点,所以除开叶子节点,节点一定有左右2个分支
tmp[--start] = '1';
}
c = f;
f = HT[f].parent;
}
HC[i] = (char *)malloc((N-start)*sizeof(char));//每次tmp的后n-start个位置有编码存在
strcpy(HC[i], &tmp[start]);//将tmp的后n-start个元素分给H[i]指向的的字符串
}
}
打印哈夫曼编码表,当编码表生成以后,以后就可以对字符串进行编码了,只要对应编码表进行转换即可
//打印哈夫曼编码表
void printHuffmanCoding(HuffmanCode HC, char ch[]){
printf("\n");
for(int i = 1; i <= N; i++){
printf("%c:%s\n", ch[i], HC[i]);
}
printf("\n");
}
4.4解码
//解码过程:从哈夫曼树的根节点出发,按字符'0'或'1'确定找其左孩子或右孩子,直至找到叶子节点即可,便求得该字串相应的字符
void decodingHuffmanCode(HuffmanTree HT, char *ch, char testDecodingStr[], int len, char *result){
int p = M;//HT的最后一个节点是根节点,前n个节点是叶子节点
int i = 0;//指示测试串中的第i个字符
//char result[30];//存储解码以后的字符串
int j = 0;//指示结果串中的第j个字符
while(i<len){
if(testDecodingStr[i] == '0'){
p = HT[p].lchild;
}
if(testDecodingStr[i] == '1'){
p = HT[p].rchild;
}
if(p <= N){//p<=N则表明p为叶子节点,因为在构造哈夫曼树HT时,HT的m个节点中前n个节点为叶子节点
result[j] = ch[p];
j++;
p = M;//p重新指向根节点
}
i++;
}
result[j] = '\0';//结果串的结束符
}
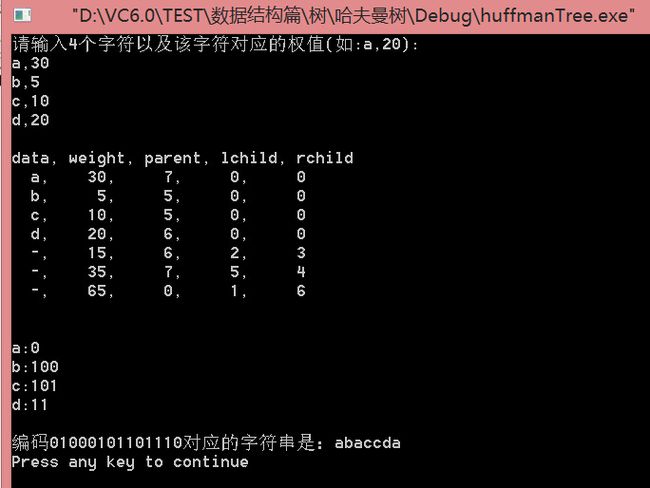
4.5演示
void main(){
HuffmanTree HT;
TElemType ch[N+1];//0号单元不使用,存储n个等待编码的字符
int w[N+1];//0号单元不使用,存储n个字符对应的权值
printf("请输入%d个字符以及该字符对应的权值(如:a,20):\n", N);
for(int i = 1; i <= N; i++){
scanf("%c,%d", &ch[i], &w[i]);
getchar();//吃掉换行符
}//即w里第i个权值对应的是ch里第i个字符元素
createHuffmanTree(HT, w , N);//构建哈夫曼树
printHuffmanTree(HT, ch);
HuffmanCode HC;//HC有n个元素,每个元素是一个指向字符串的指针,即每个元素是一个char *的变量
encodingHuffmanCode(HT, HC);//为每个字符求解哈夫曼编码
printHuffmanCoding(HC, ch);
//解码测试用例:abaccda----01000101101110
char * testDecodingStr = "01000101101110";
int testDecodingStrLen = 14;
printf("编码%s对应的字符串是:", testDecodingStr);
char result[30];//存储解码以后的字符串
decodingHuffmanCode(HT, ch, testDecodingStr, testDecodingStrLen, result);//解码(译码),通过一段给定的编码翻译成对应的字符串
printf("%s\n", result);
}