hadoop完全分布式集群搭建
搭建一个三个节点的hadoop集群
1.虚拟机安装
(1)先安装一台linux(centos7.0)虚拟机设置静态ip,绑定主机名

(2)关闭防火墙,禁止防火墙开机启动
systemctl stop firewalld ##关闭防火墙
systemctl disable firewalld ##禁止防火墙开机启动
firewall-cmd --state ##查看防火墙状态
(3)安装jdk(1.7+),添加到环境变量
(4)克隆出另外两台,修改ip地址
2.ssh面密码登录
选定一台机器作为主节点执行: ssh-keygen (一直回车即可)
进入~/.ssh目录执行:cp id_rsa.pub authorized_keys
在另外两台服务器上创建~/.ssh目录,并改变其权限chmod 700 ~/.ssh;将authorized_keys拷贝至另外两台服务器的~/.ssh目录下,这样就能免密码ssh登录另外两台服务器
3.zookeeper安装
(1)下载解压zookeeper tar包,进入ZOOKEEPER_HOME/conf 目录
mv zoo_sample.cfg zoo.cfg
修改zoo.cfg如下:
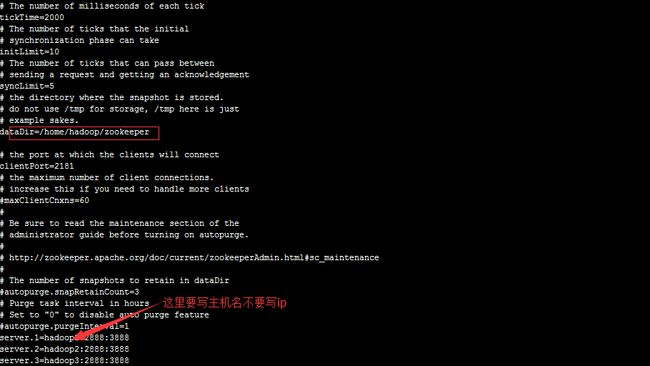
(2)将配置好的zookeeper拷贝至另外两个节点
(3)在每一个节点上的上面红框路径下创建myid文件,内容为红色箭头server后面的数字
(4)在三台服务器上启动zk,进入 $ZOOKEEPER_HOME/bin/
./zkServer.sh start
(5)jps会看到QuorumPeerMain进程,./zkServer.sh status看以查看该节点的角色是follower还是leader。
4.hadoop安装
(1)下载解压hadoop tar包得到HADOOP_HOME,将hadoop加入环境变量
进入HADOOP_HOME/etc/hadoop修改hadoop-env.sh
export JAVA_HOME=/your/java/home
(2)进入HADOOP_HOME/etc/hadoop,修改core-site.xml
<property>
<name>fs.defaultFS</name> ###指定NameNode的集群模式,此处的 mycluster 为hdfs-site.xml中dfs.nameservices的值(集群的注册名称,名字随意)
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name> ###(必须改);默认为/tmp目录,linux系统重启/tmp下的文件会被删除
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name> ###指定zookeeper集群及端口号
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
(3)进入HADOOP_HOME/etc/hadoop,修改hdfs-site.xml
<property>
<name>dfs.nameservices</name> ###NameNode注册名称
<value>mycluster</value>
</property>
<property> ###定义集群的NameNode
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name> ###指定NameNode节点
<value>hadoop1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name> ###指定NameNode节点
<value>hadoop2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop1:50070</value> ###指定http端口
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop2:50070</value> ###指定http端口
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name> ###指定JournalNode节点
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name> ###指定JournalNode节点edits的存放目录
<value>/hadoop/journal</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name> ###指定NameNode失败接管代理类
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name> ###指定接管方式
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name> ###指定ssh免密码登录的私钥路径,要将私钥拷贝至每一个NameNode的指定路径下!
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
(4)进入HADOOP_HOME/etc/hadoop,将mapred-site.xml.template重命名为 mapred-site.xml并修改:
<property>
<name>mapreduce.framework.name</name> ###指定由yarn管理集群资源
<value>yarn</value>
</property>
(5)进入HADOOP_HOME/etc/hadoop,修改yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name> ###开启ResourceManager的HA
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name> ###注册ResourceManager Ha的名称
<value>RM_HA_ID</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name> ###指定集群的所有ResourceManager进程所在的节点
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name> ###指定ResourceManager进程所在节点
<value>hadoop1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name> ###指定ResourceManager进程所在节点
<value>hadoop2</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name> ###失败恢复
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name> ###指定zookeeper集群地址
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(6)进入HADOOP_HOME/etc/hadoop,修改slaves文件 ###指定DataNode节点
hadoop1
hadoop2
hadoop3
(7)将配好好的hadoop拷贝至其他节点,包括profile文件
5.初始化hadoop集群(必须严格执行步骤)
(1)启动ZK
(2)启动journalnode,分别在jn节点上执行 hadoop-daemon.sh start journalnode
(3)格式化HDFS,在一个NameNode节点上执行 hdfs namenode -format
启动namenode进程
在另一NN上执行 hdfs namenode -bootstrapStandby
(4)格式化ZK(在其中一个NN上执行即可)hdfs zkfc -formatZK
(5)启动dfs,yarn start-dfs.sh start-yarn.sh
(6)启动另一个resourcemanager,在另一个拥有resourcemanager进程的节点上执行 yarn-deamon.sh start resourcemanager
6.部署结果,通过浏览器可以看到一个active和一个standby的NameNode以及DataNode的节点信息
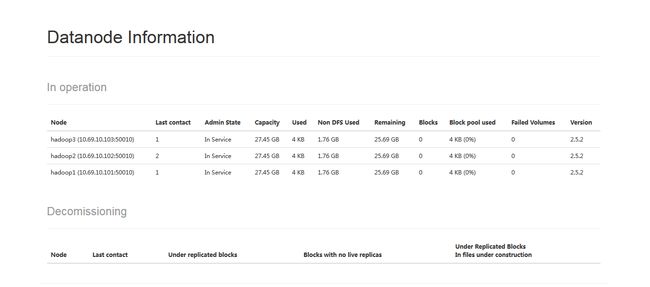
杀死active的NameNode进程,原本standby的NameNode变成active
