复习笔记——数据结构
//图片和例子,出自wiki
一.栈
1.括号匹配,
“(” 进栈
“)”匹配则出栈,否则报错
2.表达式
后序表达式
3.数组,矩阵的压缩存储
a.三角方阵,对称方阵
b.稀疏矩阵
struct xxx
{
int row;
int col;
int value;
}
二.树
1.线索二叉树
把二叉树的空指针,替换为标签+前驱或者后继的指针
2.平衡二叉树的插入和删除
三.图
1.邻接矩阵,邻接表
2.最小生成树
prim 是找和当前集合相连的最小权边
kruskal 是随便找最小权边,只要不形成环
3.最短路径
Dijkstra 和prim很像
Floyd 像矩阵乘法,不过乘法规则为min{...}
4.拓扑排序
依次找到不依赖于其它点的点
5.关键路径
四.查找
1.B树
每个点的出度小于等于m,大于等于ceil(m/2)
B树的插入和删除
2.B+树
B+树的构建就是数据库索引的构建。
具体可以看: http://blog.csdn.net/hguisu/article/details/7786014
3.hash
其实是傻瓜式的方法
查找信息的时候后依然用关键字匹配,key-value,用key做关键字,key是hash函数的输入。
五.排序
1.插入排序
普通版:和选择排序相对照,介于冒泡和选择之间
升级版:折半插入排序,就是把普遍插入排序前面查找的过程改为折半查找
终极版:希尔排序,shell sort, http://zh.wikipedia.org/wiki/%E5%B8%8C%E5%B0%94%E6%8E%92%E5%BA%8F
例如,假设有这样一组数[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
13 14 94 33 8225 59 94 65 23
45 27 73 25 39
10
然后我们对每列进行排序:
10 14 73 25 2313 27 94 33 39
25 59 94 65 82
45
将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ].这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 7325 23 13
27 94 33
39 25 59
94 65 82
45
排序之后变为:
10 14 1325 23 33
27 25 59
39 65 73
45 94 82
94
最后以1步长进行排序(此时就是简单的插入排序了)。
2.交换排序普通版:冒泡
终极版:快速排序,quick sort, qsort
快排的关键在在于怎样选基准值,并把小于基准值和大于基准值的项分开。
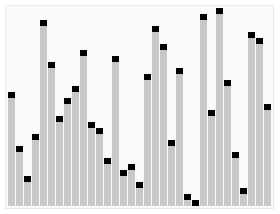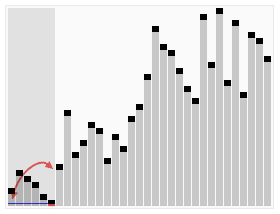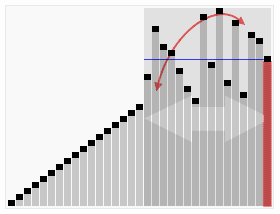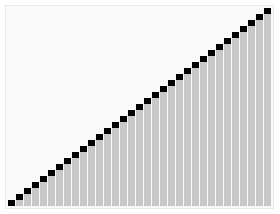
3.选择排序
普通版:选择排序
升级版:堆排序
a.末尾插入元素,对应自下而上的调整,堆尾插入
b.改变首个元素,对应自上而下的调整,堆首删除(堆尾和堆首置换,然后自上而下调整)
两者均可以用来构建堆:
用a,相当于从前到后,每个元素插入现有的堆
用b,相当于从后向前,调整每个小堆(子堆)的跟
排序时:
相当于每次从堆中删除最大的元素(堆的第一个元素),和堆尾元素互换,然后自上而下调整
4.归并排序
5.基数排序
Original, unsorted list:
- 170, 45, 75, 90, 802, 2, 24, 66
Sorting by least significant digit (1s place) gives:
- 17 0, 9 0, 80 2, 2, 2 4, 4 5, 7 5, 6 6
- Notice that we keep 802 before 2, because 802 occurred before 2 in the original list, and similarly for pairs 170 & 90 and 45 & 75.
Sorting by next digit (10s place) gives:
- 8 02, 2, 24, 45, 66, 1 70, 75, 90
- Notice that 802 again comes before 2 as 802 comes before 2 in the previous list.
Sorting by most significant digit (100s place) gives:
- 2, 24, 45, 66, 75, 90, 170, 802
It is important to realize that each of the above steps requires just a single pass over the data, since each item can be placed in its correct bucket without having to be compared with other items.
Some radix sort implementations allocate space for buckets by first counting the number of keys that belong in each bucket before moving keys into those buckets. The number of times that each digit occurs is stored in an array. Consider the previous list of keys viewed in a different way:
- 170, 045, 075, 090, 002, 024, 802, 066
The first counting pass starts on the least significant digit of each key, producing an array of bucket sizes:
- 2 (bucket size for digits of 0: 17 0, 09 0)
- 2 (bucket size for digits of 2: 00 2, 80 2)
- 1 (bucket size for digits of 4: 02 4)
- 2 (bucket size for digits of 5: 04 5, 07 5)
- 1 (bucket size for digits of 6: 06 6)
A second counting pass on the next more significant digit of each key will produce an array of bucket sizes:
- 2 (bucket size for digits of 0: 0 02, 8 02)
- 1 (bucket size for digits of 2: 0 24)
- 1 (bucket size for digits of 4: 0 45)
- 1 (bucket size for digits of 6: 0 66)
- 2 (bucket size for digits of 7: 1 70, 0 75)
- 1 (bucket size for digits of 9: 0 90)
A third and final counting pass on the most significant digit of each key will produce an array of bucket sizes:
- 6 (bucket size for digits of 0: 002, 024, 045, 066, 075, 090)
- 1 (bucket size for digits of 1: 170)
- 1 (bucket size for digits of 8: 802)
At least one LSD radix sort implementation now counts the number of times that each digit occurs in each column for all columns in a single counting pass. (See the external links section.) Other LSD radix sort implementations allocate space for buckets dynamically as the space is needed.
附加:桶排序
1.选择排序
例:5 8 5 2 9,第一遍选择第一个元素5会和2交换,那么原序列中两个5的相对前后顺序就被破坏了
2.快速排序
例1:5 3 3 4 3 8 9 10 11,现在中枢元素5和3(第5个元素,下标从1开始计)交换就会把元素3的稳定性打乱,所以快速排序是一个不稳定的排序算法,不稳定发生在中枢元素和a[j] 交换的时刻。
例2:5 1 2 9 3 4 6 7 4 8,以5为基准,划分是会遇到9和4互换,导致4不稳定
3.希尔排序
每组是并行的,显然
4.堆排序
每次队首要和堆尾交换,显然
七.额外的空间
1.归并排序,O(n)
2.快速排序,递归调用的堆栈,O(logn)
3.基数排序,桶的队列,和桶的元素,O(n+队列数)
八.外部排序
1.先块内排序,然后块间用merge sort
2.多路合并,失败者树,很像堆的插入
3.置换选择,块内排序的另一种选择,不知道有什么好处
4.最佳归并树,就是Huffman树,使访问硬盘次数最小,感觉不太科学。。。