机器学习算法的Python实现 (1):logistics回归 与 线性判别分析(LDA)
本文为笔者在学习周志华老师的机器学习教材后,写的课后习题的的编程题。之前放在答案的博文中,现在重新进行整理,将需要实现代码的部分单独拿出来,慢慢积累。希望能写一个机器学习算法实现的系列。
本文主要包括:
1、logistics回归
2、线性判别分析(LDA)
使用的python库:
- numpy
- matplotlib
- pandas
使用的数据集:机器学习教材上的西瓜数据集3.0α
| Idx | density | ratio_sugar | label |
| 1 | 0.697 | 0.46 | 1 |
| 2 | 0.774 | 0.376 | 1 |
| 3 | 0.634 | 0.264 | 1 |
| 4 | 0.608 | 0.318 | 1 |
| 5 | 0.556 | 0.215 | 1 |
| 6 | 0.403 | 0.237 | 1 |
| 7 | 0.481 | 0.149 | 1 |
| 8 | 0.437 | 0.211 | 1 |
| 9 | 0.666 | 0.091 | 0 |
| 10 | 0.243 | 0.0267 | 0 |
| 11 | 0.245 | 0.057 | 0 |
| 12 | 0.343 | 0.099 | 0 |
| 13 | 0.639 | 0.161 | 0 |
| 14 | 0.657 | 0.198 | 0 |
| 15 | 0.36 | 0.37 | 0 |
| 16 | 0.593 | 0.042 | 0 |
| 17 | 0.719 | 0.103 | 0 |
logistic回归:
参考《机器学习实战》的内容。本题分别写了梯度上升方法以及随机梯度上升方法。对书本上的程序做了一点点改动
# -*- coding: cp936 -*-
from numpy import *
import pandas as pd
import matplotlib.pyplot as plt
#读入csv文件数据
df=pd.read_csv('watermelon_3a.csv')
m,n=shape(dataMat)
df['norm']=ones((m,1))
dataMat=array(df[['norm','density','ratio_sugar']].values[:,:])
labelMat=mat(df['label'].values[:]).transpose()
#sigmoid函数
def sigmoid(inX):
return 1.0/(1+exp(-inX))
#梯度上升算法
def gradAscent(dataMat,labelMat):
m,n=shape(df.values)
alpha=0.1
maxCycles=500
weights=array(ones((n,1)))
for k in range(maxCycles):
a=dot(dataMat,weights)
h=sigmoid(a)
error=(labelMat-h)
weights=weights+alpha*dot(dataMat.transpose(),error)
return weights
#随机梯度上升
def randomgradAscent(dataMat,label,numIter=50):
m,n=shape(dataMat)
weights=ones(n)
for j in range(numIter):
dataIndex=range(m)
for i in range(m):
alpha=40/(1.0+j+i)+0.2
randIndex_Index=int(random.uniform(0,len(dataIndex)))
randIndex=dataIndex[randIndex_Index]
h=sigmoid(sum(dot(dataMat[randIndex],weights)))
error=(label[randIndex]-h)
weights=weights+alpha*error[0,0]*(dataMat[randIndex].transpose())
del(dataIndex[randIndex_Index])
return weights
#画图
def plotBestFit(weights):
m=shape(dataMat)[0]
xcord1=[]
ycord1=[]
xcord2=[]
ycord2=[]
for i in range(m):
if labelMat[i]==1:
xcord1.append(dataMat[i,1])
ycord1.append(dataMat[i,2])
else:
xcord2.append(dataMat[i,1])
ycord2.append(dataMat[i,2])
plt.figure(1)
ax=plt.subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
x=arange(0.2,0.8,0.1)
y=array((-weights[0]-weights[1]*x)/weights[2])
print shape(x)
print shape(y)
plt.sca(ax)
plt.plot(x,y) #ramdomgradAscent
#plt.plot(x,y[0]) #gradAscent
plt.xlabel('density')
plt.ylabel('ratio_sugar')
#plt.title('gradAscent logistic regression')
plt.title('ramdom gradAscent logistic regression')
plt.show()
#weights=gradAscent(dataMat,labelMat)
weights=randomgradAscent(dataMat,labelMat)
plotBestFit(weights)
梯度上升法得到的结果如下:
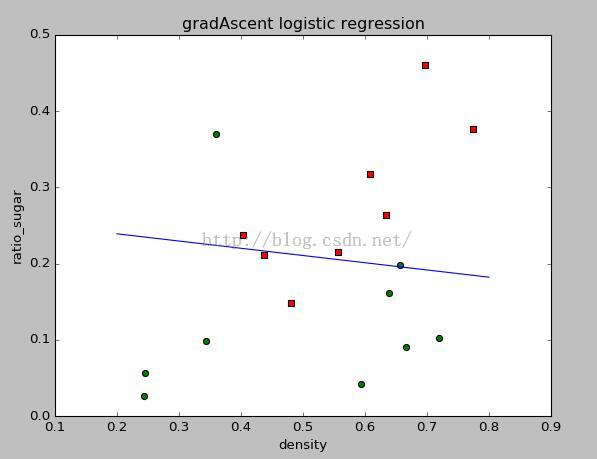
随机梯度上升法得到的结果如下:

可以看出,两种方法的效果基本差不多。但是随机梯度上升方法所需要的迭代次数要少很多
线性判别分析
LDA的编程主要参考书上P62的3.39 以及P61的3.33这两个式子。由于用公式可以直接算出,因此比较简单
公式如下:

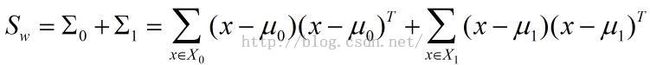
代码如下:
# -*- coding: cp936 -*-
from numpy import *
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_csv('watermelon_3a.csv')
def calulate_w():
df1=df[df.label==1]
df2=df[df.label==0]
X1=df1.values[:,1:3]
X0=df2.values[:,1:3]
mean1=array([mean(X1[:,0]),mean(X1[:,1])])
mean0=array([mean(X0[:,0]),mean(X0[:,1])])
m1=shape(X1)[0]
sw=zeros(shape=(2,2))
for i in range(m1):
xsmean=mat(X1[i,:]-mean1)
sw+=xsmean.transpose()*xsmean
m0=shape(X0)[0]
for i in range(m0):
xsmean=mat(X0[i,:]-mean0)
sw+=xsmean.transpose()*xsmean
w=(mean0-mean1)*(mat(sw).I)
return w
def plot(w):
dataMat=array(df[['density','ratio_sugar']].values[:,:])
labelMat=mat(df['label'].values[:]).transpose()
m=shape(dataMat)[0]
xcord1=[]
ycord1=[]
xcord2=[]
ycord2=[]
for i in range(m):
if labelMat[i]==1:
xcord1.append(dataMat[i,0])
ycord1.append(dataMat[i,1])
else:
xcord2.append(dataMat[i,0])
ycord2.append(dataMat[i,1])
plt.figure(1)
ax=plt.subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
x=arange(-0.2,0.8,0.1)
y=array((-w[0,0]*x)/w[0,1])
print shape(x)
print shape(y)
plt.sca(ax)
#plt.plot(x,y) #ramdomgradAscent
plt.plot(x,y) #gradAscent
plt.xlabel('density')
plt.ylabel('ratio_sugar')
plt.title('LDA')
plt.show()
w=calulate_w()
plot(w)
结果如下:
对应的w值为:
[ -6.62487509e-04, -9.36728168e-01]
由于数据分布的关系,所以LDA的效果不太明显。所以我改了几个label=0的样例的数值,重新运行程序得到结果如下:
效果比较明显,对应的w值为:
[-0.60311161, -0.67601433]