HDFS读书笔记-总体介绍(一)
一直以来对hadoop相关系列的学习都是较为零散的,不成体系。没有经过自己总结和沉淀的资料也很难长久的消化和在工作中实际运用。故而也希望通过这样系列的方式对所学习,所了解的资料进行总结。
HDFS(Hadoop Distributed File System)
顾名思义,是hadoop的分布式文件系统。HDFS是hadoop的一个子项目。Hadoop的名字在这里也提一下,是作者小孩很喜欢的一只小象玩具的名字。
HDFS的目标:
1、部署在廉价的PC服务器上。
2、用数据冗余的方式提供高容错性,认为硬件故障是常态。
3、一次写入,多次读取。(简单的数据一致性,所以场景有限)
4、提供高吞吐量,非低延迟。(一般用于离线计算存储)
5、海量数据,超大集群。
架构图:
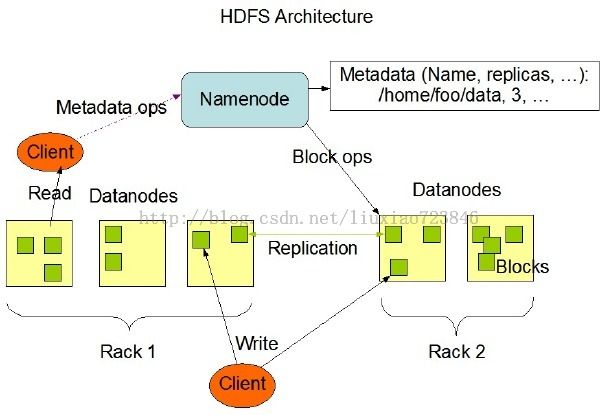
HDFS使用经典的主从结构,由一个NameNode和N个DataNode组成。简单来说,NameNode就是一个维护了什么文件在哪台机器上的元数据集合。而DataNode就是存储实际文件的机器。
从图上可以看出,client要访问文件,会先从NameNode获取到元数据,再访问实际的机器。
而一个NameNode会存在两个问题:
1、为了降低获取元数据的延迟,所有的元数据都常驻内存中,故而有内存限制。
2、单点问题,一旦NameNode挂掉,HDFS就只能人工干预并进行恢复。
这两个问题都可以单独以一个篇幅来讲述,所以在这里仅点到为止。后续的系列中我会单独叙述。
HDFS一般针对大文件,主要由于文件数目越多,NameNode内存越大。这样会大大降低NameNode的工作能力。(针对小文件的优化,在系列中我们会讲到)
DataNode中文件是以block的方式存放的,一个文件可能会被切分成多个block,简单来说一个文件如果是100M,会被切割成一个64M,一个36M的Blocks存储在DataNode中。(每个block默认64M,可配置),一个block中只会有一个文件的内容,当一个文件小于64M的时候,依然独占此block,但是不真正占用磁盘64M。以Block为单位来存放数据的好处是可增加文件读取和写入的并行能力,极大的提高DataNode的磁盘效率,并且对于文件的定位有更好的帮助。
多个block会分布在不同的机器上,并且每个block会有相对应的备份。(默认数目为3)
NameNode得知整体dataNode中的存储情况是通过DataNode定时向NameNode心跳并汇报当前block情况。如果一定的时间内DataNode中没有心跳汇报,NameNode则会认为该DataNode挂掉,进而会进行以下的处理。
1、返回给客户端的机器列表中不再有挂掉的机器。(返回给客户端的机器列表不是namenode主动推送的。是客户端定时从namenode同步一次的。 不过有些版本的hdfs会把这部分信息存储在zookeeper中通知过去。 不过这个成本是有点高的)
2、根据当前集群的情况,将挂掉的机器上的block进行冗余备份,以达到用户配置的冗余数目。(我们说过一份block会有3个备份。 一台机器挂掉了,还有另外两个备份在其他两个机器上。 namenode会判断哪个机器比较合适再放一个备份。 然后把block复制一份过去。 让总体的备份数目达到3)
在这里,笔者也要提出:常见的分布式存储系统,对于性能和容错等问题的优化方式一般是主要有两方面:
1、使用内存(本地内存、分布式内存)。
2、使用数据冗余。
了解整个结构如何协作的最好的方法就是来看如何读、写一个文件,从而能了解到整个流程:
文件写入
流程图:
1、客户端向远程的Namenode发起创建文件请求;
文件读取
1、使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
2、Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的datanode地址;
3、客户端开发库会选取离客户端最接近的datanode来读取block;
4、读取完当前block的数据后,关闭与当前的datanode连接,并为读取下一个block寻找最佳的datanode;
5、当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
6、读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。