Linux 内核源代码情景分析 chap2 存储管理 (6) --- 页面的定期换出
1. 目的
Linux 内核通过定期检查并且预先将若干页面换出, 实现减轻系统在缺页异常时候所产生的负担。 虽然, 无法避免需要临时寻找可以换出的页面, 但是, 可以减少这种事件发生的概率。Linux 内核中设置一个专门用来定期将页面换出的线程 kswapd。
kswapd 相当于一个进程 有自己的进程控制块 task_struct 结构, 但是呢, 他没有自己独立的地址空间, 我们可以将它理解为是线程。
2. kswapd 例行路线
2.1 kswapd 建立
==================== mm/vmscan.c 1146 1153 ====================
1146 static int __init kswapd_init(void)
1147 {
1148 printk("Starting kswapd v1.8\n");
1149 swap_setup();
1150 kernel_thread(kswapd, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGNAL);
1151 kernel_thread(kreclaimd, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGNAL);
1152 return 0;
1153 }
==================== mm/swap.c 293 305 ====================
[kswapd_init()>swap_setup()]
293 /*
294 * Perform any setup for the swap system
295 */
296 void __init swap_setup(void)
297 {
298 /* Use a smaller cluster for memory <16MB or <32MB */
299 if (num_physpages < ((16 * 1024 * 1024) >> PAGE_SHIFT))
300 page_cluster = 2;
301 else if (num_physpages < ((32 * 1024 * 1024) >> PAGE_SHIFT))
302 page_cluster = 3;
303 else
304 page_cluster = 4;
305 }
- kswapd_init 在系统初始化期间受到调用,主要负责 2 个事情:
- 在 swap_setup 中设定一个全局量 page_cluster。 为什么要设置这个量呢? 因为这个参数和磁盘设备驱动有关, 读磁盘时 需要先经过寻道, 但是寻道操作非常费时, 所以一般读磁盘的时候会多读几个页面, 称为预读。
- 使用 kernel_thread 创建线程kswapd 和 kreclaimd。
2.2 kswapd 执行
==================== mm/vmscan.c 947 1046 ====================
947 /*
948 * The background pageout daemon, started as a kernel thread
949 * from the init process.
950 *
951 * This basically trickles out pages so that we have _some_
95
952 * free memory available even if there is no other activity
953 * that frees anything up. This is needed for things like routing
954 * etc, where we otherwise might have all activity going on in
955 * asynchronous contexts that cannot page things out.
956 *
957 * If there are applications that are active memory-allocators
958 * (most normal use), this basically shouldn't matter.
959 */
960 int kswapd(void *unused)
961 {
962 struct task_struct *tsk = current;
963
964 tsk->session = 1;
965 tsk->pgrp = 1;
966 strcpy(tsk->comm, "kswapd");
967 sigfillset(&tsk->blocked);
968 kswapd_task = tsk;
969
970 /*
971 * Tell the memory management that we're a "memory allocator",
972 * and that if we need more memory we should get access to it
973 * regardless (see "__alloc_pages()"). "kswapd" should
974 * never get caught in the normal page freeing logic.
975 *
976 * (Kswapd normally doesn't need memory anyway, but sometimes
977 * you need a small amount of memory in order to be able to
978 * page out something else, and this flag essentially protects
979 * us from recursively trying to free more memory as we're
980 * trying to free the first piece of memory in the first place).
981 */
982 tsk->flags |= PF_MEMALLOC;
983
984 /*
985 * Kswapd main loop.
986 */
987 for (;;) {
988 static int recalc = 0;
989
990 /* If needed, try to free some memory. */
991 if (inactive_shortage() || free_shortage()) {
992 int wait = 0;
993 /* Do we need to do some synchronous flushing? */
994 if (waitqueue_active(&kswapd_done))
995 wait = 1;
996 do_try_to_free_pages(GFP_KSWAPD, wait);
997 }
998
999 /*
1000 * Do some (very minimal) background scanning. This
1001 * will scan all pages on the active list once
1002 * every minute. This clears old referenced bits
1003 * and moves unused pages to the inactive list.
1004 */
1005 refill_inactive_scan(6, 0);
1006
1007 /* Once a second, recalculate some VM stats. */
1008 if (time_after(jiffies, recalc + HZ)) {
1009 recalc = jiffies;
1010 recalculate_vm_stats();
1011 }
1012
1013 /*
1014 * Wake up everybody waiting for free memory
1015 * and unplug the disk queue.
1016 */
1017 wake_up_all(&kswapd_done);
1018 run_task_queue(&tq_disk);
1019
1020 /*
1021 * We go to sleep if either the free page shortage
1022 * or the inactive page shortage is gone. We do this
1023 * because:
1024 * 1) we need no more free pages or
1025 * 2) the inactive pages need to be flushed to disk,
1026 *it wouldn't help to eat CPU time now ...
1027 *
1028 * We go to sleep for one second, but if it's needed
1029 * we'll be woken up earlier...
1030 */
1031 if (!free_shortage() || !inactive_shortage()) {
1032 interruptible_sleep_on_timeout(&kswapd_wait, HZ);
1033 /*
1034 * If we couldn't free enough memory, we see if it was
1035 * due to the system just not having enough memory.
1036 * If that is the case, the only solution is to kill
1037 * a process (the alternative is enternal deadlock).
1038 *
1039 * If there still is enough memory around, we just loop
1040 * and try free some more memory...
1041 */
1042 } else if (out_of_memory()) {
1043 oom_kill();
1044 }
1045 }
1046 }
- 就如同程序开始的注释中所描述的, 这个kswapd 是一个页面换出的守护进程, 他可以在没有进程主动释放内存的时候, 抽取出一些空闲页面, 来为后面的页面分配做准备。
- 通过设置PF_MEMALLOC 声明自己的权限, 表明自己是内存分配者
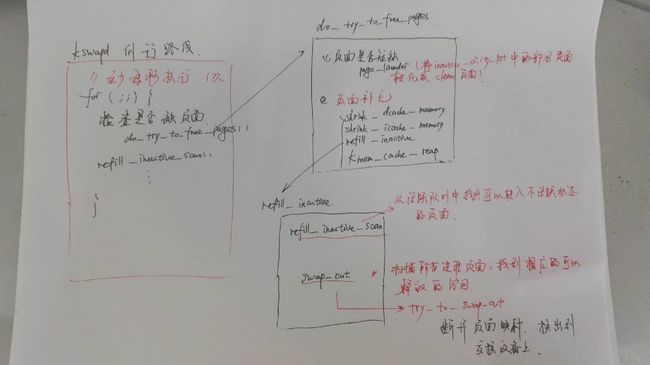
- 注意到, 这是一个死循环, 在循环的末尾,我们会调用interruptible_sleep_on_timeout 进入睡眠,允许内核自由的调度其他的进程运行。 而这里的 HZ 决定了内核中每秒有多少次时钟的中断。 分析可知这个循环至少每隔 1s 执行一遍, 这就是kswapd 的例行路线了。
- 接下来, 我们来看一下 这个例行路线中一般会做些什么呢?
- 当物理页面短缺的时候, 我们需要预先找到一些页面, 将他们的映射断开, 使这些页面从活跃状态转入到不活跃状态中去。
- 每次都要执行的, 将已经处于不活跃 脏 状态的页面写入到交换设备, 使他们成为不活跃干净页面,继续缓冲 或者 回收他们成为空闲页面。
2.2.1 inactive_shortage
==================== mm/vmscan.c 805 822 ====================
[kswapd()>inactive_shortage()]
805 /*
806 * How many inactive pages are we short?
807 */
808 int inactive_shortage(void)
809 {
810 int shortage = 0;
811
812 shortage += freepages.high;
813 shortage += inactive_target;
814 shortage -= nr_free_pages();
815 shortage -= nr_inactive_clean_pages();
816 shortage -= nr_inactive_dirty_pages;
817
818 if (shortage > 0)
819 return shortage;
820
821 return 0;
822 }
- 这段代码主要用来检查内存中可供分配或者周转的物理页面是否短缺
- freepages.high 表征空闲页面的数量, inactive_target 表征不活跃页面的数量。 而他们两者的和表征了正常情况下, 系统潜在的页面的供应量。而这部分供应量又来自于3个部分:
- 现存的空闲页面, 这些页面是可以立即参与分配的页面, 分布在各个管理区 zone 中, 通过free_area[MAX_ORDER]进行管理, 并且是合并成了地址连续, 大小为 2,4,8,…,2N 。 这些页面的数量通过nr_free_pages 进行统计。
- 不活跃干净页面, 这些页面也是通过zone 进行管理的, 但是他们不成块。 通过 nr_inactive_clean_pages 进行统计。
- 不活跃脏页面, 需要先净化这些页面, 然后才能使用, 通过 nr_inactive_dirty_pages 进行统计。
- 我们可以这么去理解这个 inactive_shortage: 我们实际可以用来分配页面的资源主要是 3 个部分,而 系统潜在的供应量, 我们可以理解为是理论上的需求, 当我的需求的量大于 实际提供的, 就表明页面短缺了。
- 我们还可以通过 free_shortage 检查是否有某个具体的管理区中存在严重的短缺,ie, 判断具体管理区中的可以直接分配的页面数量是否低于一个最低限度。
2.2.2 waitqueue_active
==================== include/linux/wait.h 152 161 ====================
[kswapd()>waitqueue_active()]
152 static inline int waitqueue_active(wait_queue_head_t *q)
153 {
154 #if WAITQUEUE_DEBUG
155 if (!q)
156 WQ_BUG();
157 CHECK_MAGIC_WQHEAD(q);
158 #endif
159
160 return !list_empty(&q->task_list);
161 }
- 当发现页面短缺的时候, 我们需要设法释放和换出若干页面, 通过do_try_to_free_pages 完成。
- 通过waitqueue_active, 我们可以查看 kswapd_done 队列中是否由函数在等待执行。 这个kswapd_done 队列, 会保证在kswapd每完成一次例行操作的时候, 会执行其中的挂载到队列中的函数。
2.2.3 do_try_to_free_pages
==================== mm/vmscan.c 907 941 ====================
[kswapd()>do_try_to_free_pages()]
907 static int do_try_to_free_pages(unsigned int gfp_mask, int user)
908 {
909 int ret = 0;
910
911 /*
912 * If we're low on free pages, move pages from the
913 * inactive_dirty list to the inactive_clean list.
914 *
915 * Usually bdflush will have pre-cleaned the pages
916 * before we get around to moving them to the other
917 * list, so this is a relatively cheap operation.
918 */
919 if (free_shortage() || nr_inactive_dirty_pages > nr_free_pages() +
920 nr_inactive_clean_pages())
921 ret += page_launder(gfp_mask, user);
922
923 /*
924 * If needed, we move pages from the active list
925 * to the inactive list. We also "eat" pages from
926 * the inode and dentry cache whenever we do this.
927 */
928 if (free_shortage() || inactive_shortage()) {
929 shrink_dcache_memory(6, gfp_mask);
930 shrink_icache_memory(6, gfp_mask);
931 ret += refill_inactive(gfp_mask, user);
932 } else {
933 /*
934 * Reclaim unused slab cache memory.
935 */
936 kmem_cache_reap(gfp_mask);
937 ret = 1;
938 }
939
940 return ret;
941 }
- 当我们空闲页面比较短缺, 或者非活跃脏页面的数量相对较多的时候, 我们就利用page_launder 获取一部分干净的页面。
- 如果经过上面1 的操作, 页面还是短缺的话, 就考虑将活跃页面转为非活跃页面进行处理。
2.2.3.1 page_launder
==================== mm/vmscan.c 465 670 ====================
[kswapd()>do_try_to_free_pages()>page_launder()]
465 /**
466 * page_launder - clean dirty inactive pages, move to inactive_clean list
467 * @gfp_mask: what operations we are allowed to do
468 * @sync: should we wait synchronously for the cleaning of pages
469 *
470 * When this function is called, we are most likely low on free +
471 * inactive_clean pages. Since we want to refill those pages as
472 * soon as possible, we'll make two loops over the inactive list,
473 * one to move the already cleaned pages to the inactive_clean lists
474 * and one to (often asynchronously) clean the dirty inactive pages.
475 *
476 * In situations where kswapd cannot keep up, user processes will
477 * end up calling this function. Since the user process needs to
478 * have a page before it can continue with its allocation, we'll
479 * do synchronous page flushing in that case.
480 *
481 * This code is heavily inspired by the FreeBSD source code. Thanks
482 * go out to Matthew Dillon.
483 */
484 #define MAX_LAUNDER (4 * (1 << page_cluster))
485 int page_launder(int gfp_mask, int sync)
486 {
487 int launder_loop, maxscan, cleaned_pages, maxlaunder;
488 int can_get_io_locks;
489 struct list_head * page_lru;
490 struct page * page;
491
492 /*
493 * We can only grab the IO locks (eg. for flushing dirty
494 * buffers to disk) if __GFP_IO is set.
495 */
496 can_get_io_locks = gfp_mask & __GFP_IO;
497
498 launder_loop = 0;
499 maxlaunder = 0;
500 cleaned_pages = 0;
501
502 dirty_page_rescan:
503 spin_lock(&pagemap_lru_lock);
504 maxscan = nr_inactive_dirty_pages;
505 while ((page_lru = inactive_dirty_list.prev) != &inactive_dirty_list &&
506 maxscan-- > 0) {
507 page = list_entry(page_lru, struct page, lru);
508
509 /* Wrong page on list?! (list corruption, should not happen) */
510 if (!PageInactiveDirty(page)) {
511 printk("VM: page_launder, wrong page on list.\n");
512 list_del(page_lru);
513 nr_inactive_dirty_pages--;
514 page->zone->inactive_dirty_pages--;
515 continue;
516 }
517
518 /* Page is or was in use? Move it to the active list. */
519 if (PageTestandClearReferenced(page) || page->age > 0 ||
520 (!page->buffers && page_count(page) > 1) ||
521 page_ramdisk(page)) {
522 del_page_from_inactive_dirty_list(page);
523 add_page_to_active_list(page);
524 continue;
525 }
526
527 /*
528 * The page is locked. IO in progress?
529 * Move it to the back of the list.
530 */
531 if (TryLockPage(page)) {
532 list_del(page_lru);
533 list_add(page_lru, &inactive_dirty_list);
534 continue;
535 }
536
537 /*
538 * Dirty swap-cache page? Write it out if
539 * last copy..
540 */
541 if (PageDirty(page)) {
542 int (*writepage)(struct page *) = page->mapping->a_ops->writepage;
543 int result;
544
545 if (!writepage)
546 goto page_active;
547
548 /* First time through? Move it to the back of the list */
549 if (!launder_loop) {
550 list_del(page_lru);
551 list_add(page_lru, &inactive_dirty_list);
552 UnlockPage(page);
553 continue;
554 }
555
556 /* OK, do a physical asynchronous write to swap. */
557 ClearPageDirty(page);
558 page_cache_get(page);
559 spin_unlock(&pagemap_lru_lock);
560
561 result = writepage(page);
562 page_cache_release(page);
563
564 /* And re-start the thing.. */
565 spin_lock(&pagemap_lru_lock);
566 if (result != 1)
567 continue;
568 /* writepage refused to do anything */
569 set_page_dirty(page);
570 goto page_active;
571 }
572
573 /*
574 * If the page has buffers, try to free the buffer mappings
575 * associated with this page. If we succeed we either free
576 * the page (in case it was a buffercache only page) or we
577 * move the page to the inactive_clean list.
578 *
579 * On the first round, we should free all previously cleaned
580 * buffer pages
581 */
582 if (page->buffers) {
583 int wait, clearedbuf;
584 int freed_page = 0;
585 /*
586 * Since we might be doing disk IO, we have to
587 * drop the spinlock and take an extra reference
588 * on the page so it doesn't go away from under us.
589 */
590 del_page_from_inactive_dirty_list(page);
591 page_cache_get(page);
592 spin_unlock(&pagemap_lru_lock);
593
594 /* Will we do (asynchronous) IO? */
595 if (launder_loop && maxlaunder == 0 && sync)
596 wait = 2; /* Synchrounous IO */
597 else if (launder_loop && maxlaunder-- > 0)
598 wait = 1; /* Async IO */
599 else
600 wait = 0; /* No IO */
601
602 /* Try to free the page buffers. */
603 clearedbuf = try_to_free_buffers(page, wait);
604
605 /*
606 * Re-take the spinlock. Note that we cannot
607 * unlock the page yet since we're still
608 * accessing the page_struct here...
609 */
610 spin_lock(&pagemap_lru_lock);
611
612 /* The buffers were not freed. */
613 if (!clearedbuf) {
614 add_page_to_inactive_dirty_list(page);
615
616 /* The page was only in the buffer cache. */
617 } else if (!page->mapping) {
618 atomic_dec(&buffermem_pages);
619 freed_page = 1;
620 cleaned_pages++;
621
622 /* The page has more users besides the cache and us. */
623 } else if (page_count(page) > 2) {
624 add_page_to_active_list(page);
625
626 /* OK, we "created" a freeable page. */
627 } else /* page->mapping && page_count(page) == 2 */ {
628 add_page_to_inactive_clean_list(page);
629 cleaned_pages++;
630 }
631
632 /*
633 * Unlock the page and drop the extra reference.
634 * We can only do it here because we ar accessing
635 * the page struct above.
636 */
637 UnlockPage(page);
638 page_cache_release(page);
639
640 /*
641 * If we're freeing buffer cache pages, stop when
642 * we've got enough free memory.
643 */
644 if (freed_page && !free_shortage())
645 break;
646 continue;
647 } else if (page->mapping && !PageDirty(page)) {
648 /*
649 * If a page had an extra reference in
650 * deactivate_page(), we will find it here.
651 * Now the page is really freeable, so we
652 * move it to the inactive_clean list.
653 */
654 del_page_from_inactive_dirty_list(page);
655 add_page_to_inactive_clean_list(page);
656 UnlockPage(page);
657 leaned_pages++;
658 } else {
659 page_active:
660 /*
661 * OK, we don't know what to do with the page.
662 * It's no use keeping it here, so we move it to
663 * the active list.
664 */
665 del_page_from_inactive_dirty_list(page);
666 add_page_to_active_list(page);
667 UnlockPage(page);
668 }
669 }
670 spin_unlock(&pagemap_lru_lock);
==================== mm/vmscan.c 671 697 ====================
[kswapd()>do_try_to_free_pages()>page_launder()]
671
672 /*
673 * If we don't have enough free pages, we loop back once
674 * to queue the dirty pages for writeout. When we were called
675 * by a user process (that /needs/ a free page) and we didn't
676 * free anything yet, we wait synchronously on the writeout of
677 * MAX_SYNC_LAUNDER pages.
678 *
679 * We also wake up bdflush, since bdflush should, under most
680 * loads, flush out the dirty pages before we have to wait on
681 * IO.
682 */
683 if (can_get_io_locks && !launder_loop && free_shortage()) {
684 launder_loop = 1;
685 /* If we cleaned pages, never do synchronous IO. */
686 if (cleaned_pages)
687 sync = 0;
688 * We only do a few "out of order" flushes. */
689 maxlaunder = MAX_LAUNDER;
690 /* Kflushd takes care of the rest. */
691 wakeup_bdflush(0);
692 goto dirty_page_rescan;
693 }
694
695 /* Return the number of pages moved to the inactive_clean list. */
696 return cleaned_pages;
697 }
- 这个函数很长, 主要用来清理非活跃脏页面, 并将他们移动到非活跃干净链表中。就如注释中描述的, 它使用了两个循环来扫描非活跃链表, 一个循环用来将已经cleaned 的页面移动到 inactive_clean_list 中去, 另一个循环用来异步的清理非活跃的脏页面, 将他们变成干净的页面。
- 使用 cleaned_pages 表示累计被 洗干净的页面的数量, 用 launder_loop 来控制扫描不活跃脏页面队列的次数。我们可以看到 代码 683 行处 使用了 !launder_loop 作为判断条件, ie, 最多只会对非活跃页面进行 两次扫描。
- 通过maxscan 设置最大的扫描数量,为什么需要这么做呢?这是因为, 我们在循环扫描一个不活跃脏页面队列的时候, 可能会把有些页面从当前位置移动到队列的尾部, 设置最大的扫描数量可以避免对一个页面的重复操作。
- 510 ~ 516 检查当前页面是不是非活跃脏页面, 如果不是, 就应该把它移除出这个队列。
- 518 ~ 524 检查这个页面是否是正在使用的, 如果是的话, 就把他移入活跃队列。 当页面被移入非活跃脏页面时候, 然后又受到了访问, 就有可能发生这样的情形。这里面有 4 个判断条件, 页面没有老化, 或者 页面没有使用缓冲区 但是 页面的引用计数 大于 1, 或者
使用了 ramdisk, ie, 用内存空间来模拟磁盘。在这些情况下面, 都是不应该将这些页面换出来的, 因而, 代码中把这些不能转出的在非活跃脏队列中的页面 转到了活跃队列中。 - 527 ~ 535 使用TryLockPage, 对与已经锁定的页面, 返回 1 表明这个页面正在被操作,将他移动到队列的尾部, 而如果未锁定, 返回0, 并且此时页面已经被锁定了。
- 537 ~ 546 判断该脏页面是否设定了 write_page 函数指针, 如果没有设置的话, 是无法写到交换设备中的, 只能返回到活跃队列中去。
- 548 ~ 554 判断这是不是第一趟扫描, 如果是第一趟扫描的话, 只需要将他移动到队列的尾端就可以了。并不真正将页面送回活跃队列中去。只有在第二趟扫描的时候, 才会将页面写出去。
- 556 ~ 562 是实际的将页面写入到交换设备中去, 不过需要先通过ClearPageDirty 把页面的 PG_dirty 标志位清零。 为什么需要清零呢? 这是因为这个写操作可能是同步的, 也可能是异步的, 需要一定的操作时间才能完成。再次期间为了避免内核再一次进入page_launder 将这个再写出一次, 就可以通过将 PG_dirty 标志位清零来处理。
- 另外, 在调用writepage 的前后分别调用了 page_cache_get 和 page_cache_release , 主要是为了在页面写出的过程中, 多一个用户。 个人理解是为了防止页面被无故的清理掉。需要注意的是, 这里将页面写出到交换文件中后, 并没有将页面立即转移到不活跃干净队列中去, 而仅仅只是把 PG_dirty 清零了。
- 564 ~ 571 如果页面写出失败, 就调用set_page_dirty 将他再次设置为 脏页面, 并移动到活跃队列中去。
- 574 ~ 647 就像注释中描述的, 如果页面有 buffer, 我们需要释放与这个页面相关联的buffer。 如果这个页面是一个仅仅用来做buffer 缓存的页面, 就可以将他直接释放掉。 而如果不是, 我们可以把他移动到 inactive_clean_list 中去。在第一轮扫描过程中, launder_loop 设置了 wait 为 0 (600 行)。用来释放所有之前已经清理过的页面。
- 647 ~ 658 如果页面不再是脏的, 并且有一个映射, 说明这个页面是可以被释放的, 那么我们将它移到干净页面队列中去。
- 658 ~ 670 如果 没法处理的话, 就把他移入到活跃队列中。
2.2.3.2 page_launder 小结
感觉这个page_launder 主要用来将不活跃脏队列中的页面, 转化成不活跃干净的页面。 他一般进行两次扫描, 第一次扫描时候, 释放之前已经清理过的所有 用作buffer 的page, 将一些需要处理的页面设置为 PG_dirty, 并将他们放到 inactive_dirty_list 的末尾。第二次扫描的时候, 才将他们换出, 并移入到相应的队列中去。
2.2.3.3 页面回收的4个方面
回到do_try_to_free_pages的代码中, 在经过page_launder 处理过后, 如果可以分配的物理页面的数量还是不足, 就需要进一步设法回收页面了。主要有4个途径:
1. shrink_dcache_memory, shrink_icache_memory, 由于打开文件的过程中需要分配和使用代表着目录项的dentry 数据结构, 以及代表着文件索引节点的 inode 数据结构。 这些结构在文件关闭之后不会立即被释放, 而是放在 LRU 队列中作为后备, 以防止在不久的将来的文件操作中还会被用到。这两个函数呢, 就是对这部分空间的回收。
2. kmem_cache_reap, 由于在内核中运行需要动态分配很多的数据结构, 因此在内核中采用了一种 称为是 slab 的管理机制。这个机制将物理页面分成小块进行分配。 但是他不会主动退还这部分空间, 就需要kmem_cache_reap 进行回收。
3. refill_inactive 操作。
2.2.3.4 refill_inactive
==================== mm/vmscan.c 824 905 ====================
[kswapd()>do_try_to_free_pages()>refill_inactive()]
824 /*
825 * We need to make the locks finer granularity, but right
826 * now we need this so that we can do page allocations
827 * without holding the kernel lock etc.
828 *
829 * We want to try to free "count" pages, and we want to
830 * cluster them so that we get good swap-out behaviour.
831 *
832 * OTOH, if we're a user process (and not kswapd), we
833 * really care about latency. In that case we don't try
834 * to free too many pages.
835 */
836 static int refill_inactive(unsigned int gfp_mask, int user)
837 {
838 int priority, count, start_count, made_progress;
839
840 count = inactive_shortage() + free_shortage();
841 if (user)
842 count = (1 << page_cluster);
843 start_count = count;
844
845 /* Always trim SLAB caches when memory gets low. */
846 kmem_cache_reap(gfp_mask);
847
848 priority = 6;
849 do {
850 made_progress = 0;
851
852 if (current->need_resched) {
853 __set_current_state(TASK_RUNNING);
854 schedule();
855 }
856
857 while (refill_inactive_scan(priority, 1)) {
858 made_progress = 1;
859 if (--count <= 0)
860 goto done;
861 }
862
863 /*
864 * don't be too light against the d/i cache since
865 * refill_inactive() almost never fail when there's
866 * really plenty of memory free.
867 */
868 shrink_dcache_memory(priority, gfp_mask);
869 shrink_icache_memory(priority, gfp_mask);
870
871 /*
872 * Then, try to page stuff out..
873 */
874 while (swap_out(priority, gfp_mask)) {
875 made_progress = 1;
876 if (--count <= 0)
877 goto done;
878 }
879
880 /*
881 * If we either have enough free memory, or if
882 * page_launder() will be able to make enough
883 * free memory, then stop.
884 */
885 if (!inactive_shortage() || !free_shortage())
886 goto done;
887
888 /*
889 * Only switch to a lower "priority" if we
890 * didn't make any useful progress in the
891 * last loop.
892 */
893 if (!made_progress)
894 priority--;
895 } while (priority >= 0);
896
897 /* Always end on a refill_inactive.., may sleep... */
898 while (refill_inactive_scan(0, 1)) {
899 if (--count <= 0)
900 goto done;
901 }
902
903 done:
904 return (count < start_count);
905 }
- 代码开始处的注释说了, 我们试图释放 count 个 页面, 为了保证有更好的swap_out 的性能, 我们将他们以簇为单位进行数据处理。
- 这里的user 表示是否有函数在 kswapd_done 队列中等待。他决定了这次回收页面的紧要程度, 对我们回收的页面的数量有一定影响。(841 ~ 842)。
- 846 通过kmem_cache_reap 回收一部分的 slab 空间。
- 848 ~ 895 通过一个大的do .. while 循环, 逐步加大力度, 进行页面的回收。
- 852 ~ 855 先检查task_struct 结构中的need_resched 是否 为 1.如果是的话, 就使用 schedule 使内核可以执行一次调度。为什么需要这样操作呢? 这是因为, kswapd 是个内核线程, 他永远不会返回自己的用户空间, (因为他没有), 这时候, 为了避免kswapd 占用cpu 长期不释放, 就需要通过这个操作实现, ‘自律’。
- 这个函数主要进行两个操作:
- 通过refill_inactive_scan 扫描活跃页面队列, 从中找到可以转入不活跃状态的页面。
- 通过swap_out 找出一个进程, 然后扫描他的映射表, 找到其中可以转入到不活跃状态的页面。
2.2.3.4.1 refill_inactive_scan
==================== mm/vmscan.c 699 769 ====================
699 /**
700 * refill_inactive_scan - scan the active list and find pages to deactivate
701 * @priority: the priority at which to scan
702 * @oneshot: exit after deactivating one page
703 *
704 * This function will scan a portion of the active list to find
705 * unused pages, those pages will then be moved to the inactive list.
706 */
707 int refill_inactive_scan(unsigned int priority, int oneshot)
708 {
709 struct list_head * page_lru;
710 struct page * page;
711 int maxscan, page_active = 0;
712 int ret = 0;
713
714 /* Take the lock while messing with the list... */
715 spin_lock(&pagemap_lru_lock);
716 maxscan = nr_active_pages >> priority;
717 while (maxscan-- > 0 && (page_lru = active_list.prev) != &active_list) {
718 page = list_entry(page_lru, struct page, lru);
719
720 /* Wrong page on list?! (list corruption, should not happen) */
721 if (!PageActive(page)) {
722 printk("VM: refill_inactive, wrong page on list.\n");
723 list_del(page_lru);
724 nr_active_pages--;
725 continue;
726 }
727
728 /* Do aging on the pages. */
729 if (PageTestandClearReferenced(page)) {
730 age_page_up_nolock(page);
731 page_active = 1;
732 } else {
733 age_page_down_ageonly(page);
734 /*
735 * Since we don't hold a reference on the page
736 * ourselves, we have to do our test a bit more
737 * strict then deactivate_page(). This is needed
738 * since otherwise the system could hang shuffling
739 * unfreeable pages from the active list to the
740 * inactive_dirty list and back again...
741 *
742 * SUBTLE: we can have buffer pages with count 1.
743 */
744 if (page->age == 0 && page_count(page) <=
745 (page->buffers ? 2 : 1)) {
746 deactivate_page_nolock(page);
747 page_active = 0;
748 } else {
749 page_active = 1;
750 }
751 }
752 /*
753 * If the page is still on the active list, move it
754 * to the other end of the list. Otherwise it was
755 * deactivated by age_page_down and we exit successfully.
756 */
757 if (page_active || PageActive(page)) {
758 list_del(page_lru);
759 list_add(page_lru, &active_list);
760 } else {
761 ret = 1;
762 if (oneshot)
763 break;
764 }
765 }
766 spin_unlock(&pagemap_lru_lock);
767
768 return ret;
769 }
1. 像注释里面所说的, 这个函数用来扫描 active_list, 找出可以转化为非活跃状态的页面。
2. 类似于 page_launder, 这个函数也维护了一个 maxscan。但是呢, 这个maxscan 是和我们的 priority 相关的。ie, 只有在priority 为 0 的时候, 才会扫描整个队列。
3. 720 ~ 726 判断这个页面是不是活跃的, 如果不是删除他。
4. 729 中的 PageTestandClearReferenced 用来检测这个页面是否还在使用(受到访问), 如果还在使用, 还有引用就不去清理他。并将它的age 递增。
5. 732 ~ 751 如果页面不再受到访问, 就递减他的age 寿命。 当这个页面的寿命达到 0 的时候,就表明这个页面很久没有受到访问了。
然后, 再看他的空间映射, 如果页面并不用作文件系统的读写缓冲, 只要页面计数大于 1 就表明还有用户空间映射。 如果页面有文件系统的读写缓冲, 此时页面计数应该与 2 做比较。通过将 page_active 记为 0, 表明页面应该从活跃状态转为 非活跃状态。
6. 752 ~ 763 如果页面被标记成了page_active 就把他移动到队列尾部, 否则, 根据oneshot 判断是否退出。
2.2.3.4.2 refill_inactive_scan 流程小结
- 通过priority 优先级确定 maxscan 的大小。遍历相应的active_list, 如果页面不是active 的, 删除他。
- 然后判断页面 page 是否受到访问, 如果受到访问, 递增他的age, 并将它移动到队列尾端
- 如果页面没有受到访问, 递减他的age, 如果age 降到 0, 并且 根据他是否有用户空间映射, 判断页面是否还处于活跃状态, 当页面的age 降到 0 的时候, 并且没有用户空间映射的时候, 通过 deactivate_page_nolock(page) 将页面变为 非活跃状态。否则移动到队列的尾端。
2.2.3.4.3 swap_out
==================== mm/vmscan.c 297 378 ====================
[kswapd()>do_try_to_free_pages()>refill_inactive()>swap_out()]
297 /*
298 * Select the task with maximal swap_cnt and try to swap out a page.
299 * N.B. This function returns only 0 or 1. Return values != 1 from
300 * the lower level routines result in continued processing.
301 */
302 #define SWAP_SHIFT 5
303 #define SWAP_MIN 8
304
305 static int swap_out(unsigned int priority, int gfp_mask)
306 {
307 int counter;
308 int __ret = 0;
309
310 /*
311 * We make one or two passes through the task list, indexed by
312 * assign = {0, 1}:
313 * Pass 1: select the swappable task with maximal RSS that has
314 * not yet been swapped out.
315 * Pass 2: re-assign rss swap_cnt values, then select as above.
316 *
317 * With this approach, there's no need to remember the last task
318 * swapped out. If the swap-out fails, we clear swap_cnt so the
319 * task won't be selected again until all others have been tried.
320 *
321 * Think of swap_cnt as a "shadow rss" - it tells us which process
322 * we want to page out (always try largest first).
323 */
324 counter = (nr_threads << SWAP_SHIFT) >> priority;
325 if (counter < 1)
326 counter = 1;
327
328 for (; counter >= 0; counter--) {
329 struct list_head *p;
330 unsigned long max_cnt = 0;
331 struct mm_struct *best = NULL;
332 int assign = 0;
333 int found_task = 0;
334 select:
335 spin_lock(&mmlist_lock);
336 p = init_mm.mmlist.next;
337 for (; p != &init_mm.mmlist; p = p->next) {
338 struct mm_struct *mm = list_entry(p, struct mm_struct, mmlist);
339 if (mm->rss <= 0)
340 continue;
341 found_task++;
342 /* Refresh swap_cnt? */
343 if (assign == 1) {
344 mm->swap_cnt = (mm->rss >> SWAP_SHIFT);
345 if (mm->swap_cnt < SWAP_MIN)
346 mm->swap_cnt = SWAP_MIN;
347 }
348 if (mm->swap_cnt > max_cnt) {
349 max_cnt = mm->swap_cnt;
350 best = mm;
351 }
352 }
353
354 /* Make sure it doesn't disappear */
355 if (best)
356 atomic_inc(&best->mm_users);
357 spin_unlock(&mmlist_lock);
358
359 /*
360 * We have dropped the tasklist_lock, but we
361 * know that "mm" still exists: we are running
362 * with the big kernel lock, and exit_mm()
363 * cannot race with us.
364 */
112
365 if (!best) {
366 if (!assign && found_task > 0) {
367 assign = 1;
368 goto select;
369 }
370 break;
371 } else {
372 __ret = swap_out_mm(best, gfp_mask);
373 mmput(best);
374 break;
375 }
376 }
377 return __ret;
378 }
1. 类似于refill_inactive_scan 循环的时候依赖于maxscan, 这个函数在循环的时候依赖于 counter, 而这个counter 与系统当前的线程的数量, 以及调用时候的优先级 priority 相关。
2. 这个函数呢, 并不会做物理意义上的换出操作, 只是为把一些页面交换到交换设备上做准备而已。
3. 每个进程都有自身的虚存空间, 在这个空间中已经分配并且建立了映射的页面构成了一个集合。而这个集合中对应的物理页面在内存中的页面的集合, 一般是这个集合的一个子集。我们称为是“驻内存页集合”, 其大小为rss。
4. rss表示一个进程占用的内存页面的数量, *而swap_cnt 表示一个进程在一轮换出内存页面的努力中尚未考察的数量。***ie, rss > swap_cnt
5. 335 ~ 352 遍历除init 进程以外的所有进程, 来寻找一块swap_cnt 数量最大的进程。如果第一轮扫描没有找到这样的进程, 就把mm->rss 拷贝到mm->swap_cnt 再查找一次, 最大的swap_cnt。
6. 354 ~ 357 为进程块添加一个用户, 避免进程块消失
7. 从进程的角度而言, 对进程页面的占用主要有两个方面:
1. 由于页面异常而产生页面建立或者页面映射恢复
2. 调用swap_out 切断若干页面的映射
8. 找到一个最大的进程块之后, 就使用 swap_out_mm 完成页面的具体的换出工作。然后用mmput 递减他的用户计数。
2.2.3.4.4 swap_out 小结
本质上也是一个两层扫描, 找到最大 swap_cnt 的进程块, 并将它换出。
2.2.3.4.5 swap_out_mm
2.2.3.4.5.1 part 1
==================== mm/vmscan.c 257 295 ====================
[kswapd()>do_try_to_free_pages()>refill_inactive()>swap_out()>swap_out_mm()]
257 static int swap_out_mm(struct mm_struct * mm, int gfp_mask)
258 {
259 int result = 0;
260 unsigned long address;
261 struct vm_area_struct* vma;
262
263 /*
264 * Go through process' page directory.
265 */
266
267 /*
268 * Find the proper vm-area after freezing the vma chain
269 * and ptes.
270 */
271 spin_lock(&mm->page_table_lock);
272 address = mm->swap_address;
273 vma = find_vma(mm, address);
274 if (vma) {
275 if (address < vma->vm_start)
276 address = vma->vm_start;
277
278 for (;;) {
279 result = swap_out_vma(mm, vma, address, gfp_mask);
280 if (result)
281 goto out_unlock;
282 vma = vma->vm_next;
283 if (!vma)
284 break;
285 address = vma->vm_start;
286 }
287 }
288 /* Reset to 0 when we reach the end of address space */
289 mm->swap_address = 0;
290 mm->swap_cnt = 0;
291
292 out_unlock:
293 spin_unlock(&mm->page_table_lock);
294 return result;
295 }
1. mm->swap_address 表征了在执行过程中需要接着考察的页面的地址。
2. 先找到相应需要考察的虚存区域 vma。然后通过 swap_out_vma 试图换出一个页面, 如果不行, 继续向后尝试。
3. 这个过程中有个非常重要的调用: try_to_swap_out
2.2.3.4.6 try_to_swap_out
==================== mm/vmscan.c 27 56 ====================
[kswapd()>do_try_to_free_pages()>refill_inactive()>swap_out()>swap_out_mm()>swap_out_vma()>swap_out_pgd()
>swap_out_pmd()>try_to_swap_out()]
27 /*
28 * The swap-out functions return 1 if they successfully
29 * threw something out, and we got a free page. It returns
30 * zero if it couldn't do anything, and any other value
31 * indicates it decreased rss, but the page was shared.
32 *
33 * NOTE! If it sleeps, it *must* return 1 to make sure we
34 * don't continue with the swap-out. Otherwise we may be
35 * using a process that no longer actually exists (it might
36 * have died while we slept).
37 */
38 static int try_to_swap_out(struct mm_struct * mm, struct vm_area_struct* vma, unsigned long address,
pte_t * page_table, int gfp_mask)
39 {
40 pte_t pte;
41 swp_entry_t entry;
42 struct page * page;
43 int onlist;
44
45 pte = *page_table;
46 if (!pte_present(pte))
47 goto out_failed;
48 page = pte_page(pte);
49 if ((!VALID_PAGE(page)) || PageReserved(page))
50 goto out_failed;
51
52 if (!mm->swap_cnt)
53 return 1;
54
55 mm->swap_cnt--;
56
1. 这里的page_table 实际上指向一个页面表项, 而不是一个页面表。
2. 上述代码主要是对page 做有效性验证。
附加代码:
==================== mm/vmscan.c 106 107 ====================
106 out_failed:
107 return 0;
==================== include/asm-i386/page.h 118 118 ====================
118 #define VALID_PAGE(page) ((page - mem_map) < max_mapnr)
- valid_page 主要根据页面在数组中的下标不能超过 最大的物理内存页面序号 max_mapnr 来判断。
2.2.3.4.5.2 part 2
==================== mm/vmscan.c 57 74 ====================
[kswapd()>_do_try_to_free_pages()>refill_inactive()>swap_out()>swap_out_mm()>swap_out_vma()>swap_out_pgd()
>swap_out_pmd()>try_to_swap_out()]
57 onlist = PageActive(page);
58 /* Don't look at this pte if it's been accessed recently. */
59 if (ptep_test_and_clear_young(page_table)) {
60 age_page_up(page);
61 goto out_failed;
62 }
63 if (!onlist)
64 /* The page is still mapped, so it can't be freeable... */
65 age_page_down_ageonly(page);
66
67 /*
68 * If the page is in active use by us, or if the page
69 * is in active use by others, don't unmap it or
70 * (worse) start unneeded IO.
71 */
72 if (page->age > 0)
73 goto out_failed;
74
==================== include/linux/mm.h 230 230 ====================
230 #define PageActive(page) test_bit(PG_active, &(page)->flags)
==================== include/asm-i386/pgtable.h 285 285 ====================
285 static inline int ptep_test_and_clear_young(pte_t *ptep) { return
test_and_clear_bit(_PAGE_BIT_ACCESSED, ptep); }
==================== mm/swap.c 125 138 ====================
[kswapd()>_do_try_to_free_pages()>refill_inactive()>swap_out()>swap_out_mm()>swap_out_vma()>swap_out_pgd()
>swap_out_pmd()>try_to_swap_out()>age_page_up()]
125 void age_page_up(struct page * page)
126 {
127 /*
128 * We're dealing with an inactive page, move the page
129 * to the active list.
130 */
131 if (!page->age)
132 activate_page(page);
133
134 /* The actual page aging bit */
135 page->age += PAGE_AGE_ADV;
136 if (page->age > PAGE_AGE_MAX)
137 page->age = PAGE_AGE_MAX;
138 }
==================== mm/swap.c 103 110 ====================
103 /*
104 * We use this (minimal) function in the case where we
105 * know we can't deactivate the page (yet).
106 */
107 void age_page_down_ageonly(struct page * page)
108 {
109 page->age /= 2;
110 }
- 通过 ptep_test_and_clear_young 来测试一个页面是否年轻。ie, 从上一次try_to_swap_out 扫描后, 如果又被访问过了, 说明还是很年轻的。
- 另外, 这个操作之后 PAGE_ACCESSED 标志位会被置为 0. 当然对年轻的页面一定是不会进行换出的。但是我们会增加他的寿命 age。
- 那如果页面不在 活跃队列中的话, 就将他的寿命 age 减半, 衰老。age 没有降到 0 的话, 就不可以把他换出来。
2.2.3.4.5.3 part 3
==================== mm/vmscan.c 75 108 ====================
[kswapd()>_do_try_to_free_pages()>refill_inactive()>swap_out()>swap_out_mm()>swap_out_vma()>swap_out_pgd()>swap_o
ut_pmd()>try_to_swap_out()]
75 if (TryLockPage(page))
76 goto out_failed;
77
78 /* From this point on, the odds are that we're going to
79 * nuke this pte, so read and clear the pte. This hook
80 * is needed on CPUs which update the accessed and dirty
81 * bits in hardware.
82 */
83 pte = ptep_get_and_clear(page_table);
84 flush_tlb_page(vma, address);
85
86 /*
87 * Is the page already in the swap cache? If so, then
88 * we can just drop our reference to it without doing
89 * any IO - it's already up-to-date on disk.
90 *
91 * Return 0, as we didn't actually free any real
92 * memory, and we should just continue our scan.
93 */
94 if (PageSwapCache(page)) {
95 entry.val = page->index;
96 if (pte_dirty(pte))
97 set_page_dirty(page);
98 set_swap_pte:
99 swap_duplicate(entry);
100 set_pte(page_table, swp_entry_to_pte(entry));
101 drop_pte:
102 UnlockPage(page);
103 mm->rss--;
104 deactivate_page(page);
105 page_cache_release(page);
106 out_failed:
107 return 0;
108 }
==================== include/linux/mm.h 183 183 ====================
183 #define TryLockPage(page) test_and_set_bit(PG_locked, &(page)->flags)
==================== include/linux/mm.h 217 217 ====================
217 #define PageSwapCache(page) test_bit(PG_swap_cache, &(page)->flags)
1. 如果一个页面的PG_locked 标志位 已经为 1 了, 表明他已经被别的进程锁定了, 不能才对他处理了。
2. 如果页面已经被缓存过了,ie, 页面内容已经在 交换设备上了, 只要将映射断开即可。PG_swap_cache 表示的就是page 结构在 swapper_space 队列中。而这时候 的 index 字段就是一个32 bit 的索引项 swp_entry_t 指向页面在交换设备上映像的指针。
3. 使用swap_duplicate 检测索引项的内容, 并递增相应盘上页面的共享计数。
4. 使用 set_pte 将指向盘上页面的索引项置入相应的页面表项, 这样原先对内存页面的映射, 现在转变成了对盘上页面的映射。从而完成断开物理页面映射的操作。
#2.2.3.4.5.3.1 swap_duplicate
==================== mm/swapfile.c 820 871 ====================
[kswapd()>_do_try_to_free_pages()>refill_inactive()>swap_out()>swap_out_mm()>swap_out_vma()>swap_out_pgd()
>swap_out_pmd()>try_to_swap_out()>swap_duplicate()]
119
820 /*
821 * Verify that a swap entry is valid and increment its swap map count.
822 * Kernel_lock is held, which guarantees existance of swap device.
823 *
824 * Note: if swap_map[] reaches SWAP_MAP_MAX the entries are treated as
825 * "permanent", but will be reclaimed by the next swapoff.
826 */
827 int swap_duplicate(swp_entry_t entry)
828 {
829 struct swap_info_struct * p;
830 unsigned long offset, type;
831 int result = 0;
832
833 /* Swap entry 0 is illegal */
834 if (!entry.val)
835 goto out;
836 type = SWP_TYPE(entry);
837 if (type >= nr_swapfiles)
838 goto bad_file;
839 p = type + swap_info;
840 offset = SWP_OFFSET(entry);
841 if (offset >= p->max)
842 goto bad_offset;
843 if (!p->swap_map[offset])
844 goto bad_unused;
845 /*
846 * Entry is valid, so increment the map count.
847 */
848 swap_device_lock(p);
849 if (p->swap_map[offset] < SWAP_MAP_MAX)
850 p->swap_map[offset]++;
851 else {
852 static int overflow = 0;
853 if (overflow++ < 5)
854 printk("VM: swap entry overflow\n");
855 p->swap_map[offset] = SWAP_MAP_MAX;
856 }
857 swap_device_unlock(p);
858 result = 1;
859 out:
860 return result;
861
862 bad_file:
863 printk("Bad swap file entry %08lx\n", entry.val);
864 goto out;
865 bad_offset:
866 printk("Bad swap offset entry %08lx\n", entry.val);
867 goto out;
868 bad_unused:
120
869 printk("Unused swap offset entry in swap_dup %08lx\n", entry.val);
870 goto out;
871 }
1. 这里的type 表征交换设备的序号
2. 833 ~ 844 检验entry 的合法性
3. 845 ~ 856 递增设备文件上的共享计数
#2.2.3.4.5.3.2 deactive_page
==================== mm/swap.c 189 194 ====================
[kswapd()>_do_try_to_free_pages()>refill_inactive()>swap_out()>swap_out_mm()>swap_out_vma()>swap_out_pgd()
>swap_out_pmd()>try_to_swap_out()>deactivate_page()]
189 void deactivate_page(struct page * page)
190 {
191 spin_lock(&pagemap_lru_lock);
192 deactivate_page_nolock(page);
193 spin_unlock(&pagemap_lru_lock);
194 }
[kswapd()>_do_try_to_free_pages()>refill_inactive()>swap_out()>swap_out_mm()>swap_out_vma()>swap_out_pgd()
>swap_out_pmd()>try_to_swap_out()>deactivate_page()>deactivate_page_nolock()]
154 /**
155 * (de)activate_page - move pages from/to active and inactive lists
156 * @page: the page we want to move
157 * @nolock - are we already holding the pagemap_lru_lock?
158 *
159 * Deactivate_page will move an active page to the right
160 * inactive list, while activate_page will move a page back
161 * from one of the inactive lists to the active list. If
162 * called on a page which is not on any of the lists, the
163 * page is left alone.
164 */
165 void deactivate_page_nolock(struct page * page)
166 {
167 /*
168 * One for the cache, one for the extra reference the
169 * caller has and (maybe) one for the buffers.
170 *
171 * This isn't perfect, but works for just about everything.
172 * Besides, as long as we don't move unfreeable pages to the
173 * inactive_clean list it doesn't need to be perfect...
174 */
175 int maxcount = (page->buffers ? 3 : 2);
176 page->age = 0;
177 ClearPageReferenced(page);
178
179 /*
180 * Don't touch it if it's not on the active list.
181 * (some pages aren't on any list at all)
182 */
183 if (PageActive(page) && page_count(page) <= maxcount && !page_ramdisk(page)) {
184 del_page_from_active_list(page);
185 add_page_to_inactive_dirty_list(page);
186 }
187 }
==================== include/linux/swap.h 234 240 ====================
234 #define del_page_from_active_list(page) { \
122
235 list_del(&(page)->lru); \
236 ClearPageActive(page); \
237 nr_active_pages--; \
238 DEBUG_ADD_PAGE \
239 ZERO_PAGE_BUG \
240 }
==================== include/linux/swap.h 217 224 ====================
217 #define add_page_to_inactive_dirty_list(page) { \
218 DEBUG_ADD_PAGE \
219 ZERO_PAGE_BUG \
220 SetPageInactiveDirty(page); \
221 list_add(&(page)->lru, &inactive_dirty_list); \
222 nr_inactive_dirty_pages++; \
223 page->zone->inactive_dirty_pages++; \
224 }
==================== include/linux/pagemap.h 34 34 ====================
34 #define page_cache_release(x) __free_page(x)
==================== include/linux/mm.h 379 379 ====================
379 #define __free_page(page) __free_pages((page), 0)
==================== mm/page_alloc.c 549 553 ====================
549 void __free_pages(struct page *page, unsigned long order)
550 {
551 if (!PageReserved(page) && put_page_testzero(page))
552 __free_pages_ok(page, order);
553 }
==================== include/linux/mm.h 152 152 ====================
152 #define put_page_testzero(p) atomic_dec_and_test(&(p)->count)
- page 中有个值 count。
- 当页面为空闲页面的时候, count 为 0
- 刚分配的时候, count 为 1 (rmqueue)
- 以后每添加一个用户, 建立或者恢复映射, 都会使得count 增加。
- 当页面为 活跃页面, 页面的引用小于 maxcount, 并且没有进行 ramdisk 操作, 我们就可以将页面转入到非活跃队列中去。
- 使用 page_cache_release 递减页面使用的引用计数。
2.2.3.4.5.4 part 4
==================== mm/vmscan.c 110 157 ====================
[kswapd()>_do_try_to_free_pages()>refill_inactive()>swap_out()>swap_out_mm()>swap_out_vma()>swap_out_pgd()
>swap_out_pmd()>try_to_swap_out()]
110 /*
111 * Is it a clean page? Then it must be recoverable
112 * by just paging it in again, and we can just drop
113 * it..
114 *
115 * However, this won't actually free any real
116 * memory, as the page will just be in the page cache
117 * somewhere, and as such we should just continue
118 * our scan.
119 *
120 * Basically, this just makes it possible for us to do
121 * some real work in the future in "refill_inactive()".
122 */
123 flush_cache_page(vma, address);
124 if (!pte_dirty(pte))
125 goto drop_pte;
126
127 /*
128 * Ok, it's really dirty. That means that
129 * we should either create a new swap cache
130 * entry for it, or we should write it back
131 * to its own backing store.
132 */
133 if (page->mapping) {
134 set_page_dirty(page);
135 goto drop_pte;
136 }
137
138 /*
139 * This is a dirty, swappable page. First of all,
140 * get a suitable swap entry for it, and make sure
141 * we have the swap cache set up to associate the
142 * page with that swap entry.
143 */
144 entry = get_swap_page();
145 if (!entry.val)
146 goto out_unlock_restore; /* No swap space left */
147
148 /* Add it to the swap cache and mark it dirty */
149 add_to_swap_cache(page, entry);
150 set_page_dirty(page);
151 goto set_swap_pte;
152
153 out_unlock_restore:
154 set_pte(page_table, pte);
155 UnlockPage(page);
156 return 0;
157 }
==================== include/asm-i386/pgtable.h 269 269 ====================
269 static inline int pte_dirty(pte_t pte) { return (pte).pte_low & _PAGE_DIRTY; }
==================== include/linux/mm.h 187 191 ====================
[kswapd()>_do_try_to_free_pages()>refill_inactive()>swap_out()>swap_out_mm()>swap_out_vma()>swap_out_pgd()
>swap_out_pmd()>try_to_swap_out()>set_page_dirty()]
187 static inline void set_page_dirty(struct page * page)
188 {
189 if (!test_and_set_bit(PG_dirty, &page->flags))
190 __set_page_dirty(page);
191 }
==================== mm/filemap.c 134 147 ====================
134 /*
135 * Add a page to the dirty page list.
136 */
137 void __set_page_dirty(struct page *page)
138 {
139 struct address_space *mapping = page->mapping;
140
141 spin_lock(&pagecache_lock);
142 list_del(&page->list);
143 list_add(&page->list, &mapping->dirty_pages);
144 spin_unlock(&pagecache_lock);
145
146 mark_inode_dirty_pages(mapping->host);
147 }
==================== include/linux/swap.h 150 150 ====================
150 #define get_swap_page() __get_swap_page(1)
- 页表项中有个标志位 _PAGE_DIRTY, 如果这个标记为 0, 表示这个页面没有被写过, 对这样的页面, 如果长期没有写入, 我们可以解除他的映射。
- 如果是通过mmap 建立起来的文件映射, 则其page 结构中的指针 mapping 指向相应的address_space 数据结构。对这样的页面, 需要特殊处理, set_page_dirty 将页面转移到文件映射的 脏 页面队列中。
- 对于一个脏的, 不在swapper_space 队列中的页面,我们可以通过 get_swap_page 从交换设备上 分配一个页面, 然后利用 add_to_swap_cache 将页面链入到 swapper_space 队列中, 以及活跃队列中。
- 页面老化的速度和 扫描的次数有关。
3. kswapd 例行路线小结