Machine Learning第九周笔记:异常检测与推荐系统
博客已经迁移到Marcovaldo’s blog: http://marcovaldong.github.io/
Andrew Ng在Machine Learning的第九周介绍了异常检测(anomaly detection)和推荐系统(recommender system),将笔记整理在下面。
Anomaly Detection
Density Estimation
Problem Motivation
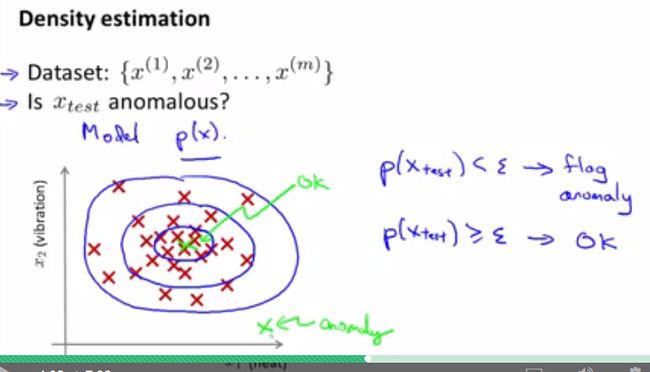
视频开头,Andrew Ng告诉我们,异常检测(anomaly detection)主要应用于无监督式学习,但它更像是监督式学习。我们以飞行器发动机为例来介绍异常检测。飞行器发动机会有很多特征,这里我们用 x1 表示产生的热量,用 x2 表示振动强度,且假设有数据集{ x(1) , x(2) ,…,x^{(m)}}(注意,这里的数据是标记的),下图坐标系中每个点代表一组数据。我们的问题是怎样根据现有的这些未标记数据去判断一组新数据是否可靠(如新数据是真实的,还是编造的)。下图中有两组绿色标记的数据点,直观上,我们会觉得上面的那组数据应该更可靠一些,因为该数据点周围有许多其他的数据点;而下面的那组太孤立,可能存在问题。
这里我们引入了一个密度估计的模型来判断新数据 xtest 异常与否,其中 p(x) 是指数据点在整个数据集中的密度分布,其具体公式会在后面给出。
对于下图中的training set,我们发现数据点从中心(图中的小圆圈处)到四周(图中的大圆圈处),其密度由大到小。处于中心的数据点其更有可能是正常的,而处于边缘处的数据点则更有可能是异常的。
异常检测的应用有很多,如下图中给出的流量监测中的反作弊、装备制造、监测数据中心的机器运作情况。在前一个应用中,首先提取用户的特征(如用户登录频率、用户访问页面数量、用户的post数量等),收集数据,然后得出密度分布模型 p(x) ,最后用来判断某个用户是否作弊。在后一个应用中,我们可能会提取的特征有内存使用情况、磁盘可用/占用情况、CPU工作量、CPU工作量/流量等等。通过这些特征值,我们可以判断机器运作是否正常。例如,若CPU利用率很高,而流量很小,则该机器可能进入了死循环。

Gaussian Distribution
这一小节我们介绍Gaussian分布,也就是高中就开始学的正态分布。如果你对Gaussian分布已经相当熟悉的话,就可以跳过这一节了。假设 x∈R ,如果x服从期望值为 μ ,方差为 σ2 的Gaussian分布的话,则有
概率密度函数的图像如下图所示

下图给出不同参数的Gaussian分布的图像,反映了概率分布函数随数据样本点期望和方差的变化情况。
我们知道概率分布函数中两个参数的定义,对于给定的数据集{ {x(1),x(2),...,x(m)} },其中 x∈R 。下面给出计算公式:
Algorithm
给定训练数据集{ x(1) ,…, x(m) },其中 x∈R ,对于x我们有
其中 xi 是x的第i个分量(i的取值是从1到n),且有
这就前面提到的密度估计模型。(这里,特征 x1 到 xn 是互不相关的)下图给出了具体的密度估计算法:

下图给出了一个具体的应用,特征 x1 和 x2 分别服从于 N(μ1,σ21) 、 N(μ2,σ22) 的正态分布,二者互不相关。图中标出了两个测试数据 x(1)test 、 x(2)test ,通过计算得知 x(1)test 为正常数据,而 x(2)test 为异常数据。
Building an Anomaly Detection System
Developing and Evaluating an Anomaly Detection System
在构建一个学习算法(选择特征等)时, 一个能够衡量学习算法性能的指标会其很大的帮助作用。假设我们有一些已经标记了的数据(正常数据标记为 y=0 ,异常数据标记为 y=1 ),我么应该让training set中的数据全部为正常数据,cross-validation set和test set中的大部分是正常数据,小部分是异常数据。
下面沿用前面的飞行棋发动机的例子,给出具体的数据分布。注意第二种数据分布中,cross-validation set和test set中的正常数据是一样的,这在很多时候是允许的。

当然,在处理未标记的数据集时,采用的是同样的一个过程。另外,这里提到了评判学习算法性能的指标,如precision、recall、 F1score ,不明白的可以查看第六周笔记二。
Anomaly Detection vs. Supervised Learning
通过前面的学习,我们发现异常检测和有监督式学习很像,这一节我们就来讨论一下,那些情况适合使用异常检测,那些时候适合有监督式学习。
首先是数据集的分布上有区别:异常检测适用于positive examples(异常数据,y=1)占很少一部分而negative examples(正常数据,y=0)占很大一部分的数据集;而有监督式学习适用于positive examples和negative examples数量相当的数据集。另外,异常检测可以应对多种类型的异常数据,其处理的新的异常数据很可能是以前没有遇到过的(比如,电脑异常中可能会遇到CPU利用率多高、流量过大等多种异常,而这些异常的数量肯定都很低,且必须都能被检测出来);而监督式学习处理的新数据与training set中的数据是相似的。

在这里我们结合前面提到的几个应用来对比二者的不同。异常检测的应用有流量监测中的反作弊、装备制造、监测数据中心的机器运作情况等,这里的异常用户/设备(发动机)/电脑相对于正常用户/设备(发动机)/电脑数量很少很少,且种类多样。监督式学习的应用有垃圾邮件系统、天气预测、癌症分类,这几种应用都是讲数据分成数量相当的几类,且同一类中的数据很相似。
Choosing What features to Use
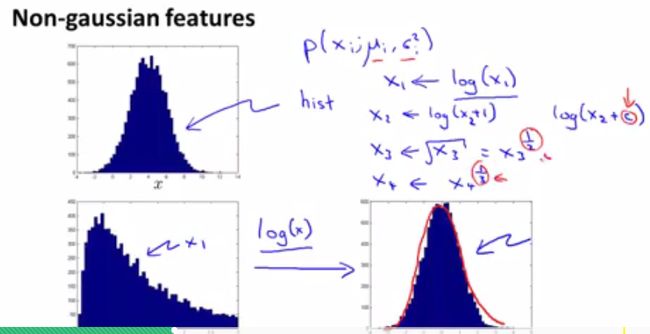
这一小节我们介绍在异常检测中如何设计特征。我们是使用概率密度分布来处理数据,检测异常,因此我们需要是数据集中的特征满足某一分布,如Gaussian分布(当然,你也可以使用其他的分布,这时你就要调整前面的 p(x) )。下图中左上是一个特征的频率直方图,基本符合Gaussian分布,这时我们可以直接进行异常检测;类似左下这样的明显不符合Gaussian分布,这时我们就需要对其进行调整(图中将 x1 改成了 log(x1) ),再进行异常检测。
通常情况下,在对新数据进行检测时,我们希望由正常数据得到的 p(x) 值很大,而由异常数据得到的 p(x) 值很小,这样就能成功的将二者分开了。但是,有时候却发现,异常数据和正常数据得到的 p(x) 值相当,不能区分开,此时我们就要考虑添加新的特征了。(我的理解是,原有特征对这个异常对敏感,需要增添对此类异常敏感的特征)视频中举了检测电脑运行异常的例子:机器可能出现CPU利用率很高但网络流量很小的情况,原有的特征可能不能检测出这种异常,这时我们要增加类似 x5 、 x6 这样的特征,如下图所示。

Multivariate Gaussian Distribution(Optimal)
下面这两小节都是在介绍多维Gaussian分布,可查阅相关概率书籍。
Multivariate Gaussian Distribution
这里使用电脑异常检测的例子,下图左侧给出了数据点在坐标系中的分布情况,其中横坐标 x1 表示CPU利用率(CPU load),纵坐标 x2 表示内存占用情况(memory use)。下图右侧给出了 x1 、 x2 的频率直方图。我们取坐标系中绿色叉叉对应的数据点x,按照原来的计算方法来检测其是否异常。按照右侧的频率直方图,我们可以发现 p(x1;μ1,σ21) 和 p(x2;μ2,σ22) 都不会取到太小的值,因此最终的p(x)会取到一个不是很小的值,系统会将其认定为正常数据。但观察左侧坐标系,我们发现 x1 和 x2 是正相关的,而绿色叉叉的CPU利用率比较小,内存占用比较大,应该是一个异常数据。很显然,原来的异常检测未能正确判断这组数据。

发生上面情况的原因是, x1 和 x2 不是相互独立的。此时,我们就应该使用多维正态分布。对于 x∈R ,我们不再挨个单独计算 p(xi) 。而是计算下面的公式(搞了半天没写出Latex公式,只好截图(X_X)):
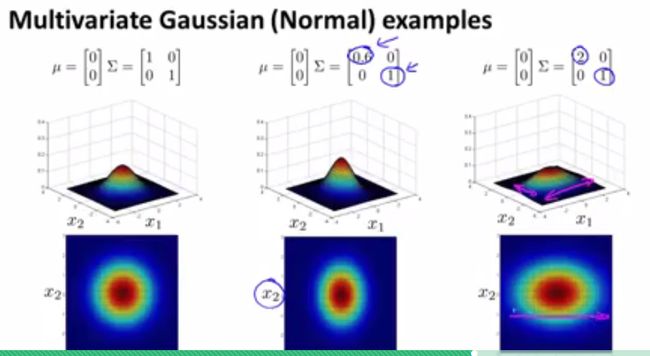
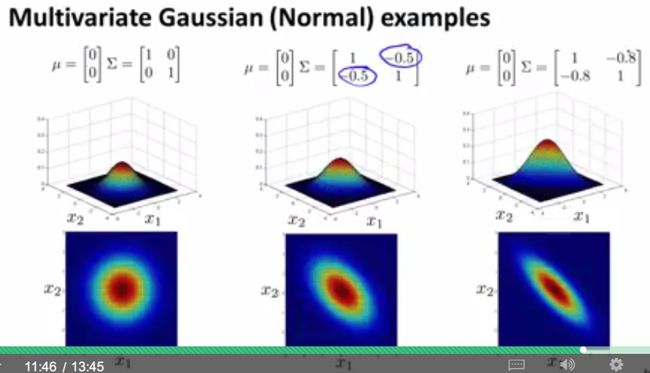
下面几张图给出了概率密度函数随参数 μ 和 ∑ 的变化情况,足够我们使用。若有兴趣了解更多,请查阅相关概率论教材。

Anomaly Detection Using the Multivariate Gaussian Distribution
给定training set{ x(1),x(2),...,x(m) },下图给出计算参数 μ 和 ∑ 的计算公式:
使用前面给出的Gaussian分布概率密度函数p(x)来对新数据x进行判断,若 p(x)<ϵ ,则标记为异常数据。
前面原始模型与多维Gaussian分布模型的区别在于特征的相关性:原始模型中的特征之间是相互独立,其对应于多维Gaussian分布模型中的协方差矩阵 ∑ 是一个对角矩阵(即将原始模型的参数放到矩阵中,对角线上是n个特征的方差,其他位置为0);而多维Gaussian分布的协方差矩阵 ∑ 是一个对称矩阵(对角线上是n个特征的方差,而非对角线位置表示的是两两特征之间的相互影响)。想了解更多数学原理的话,请查阅概率论教材。
原始模型和多维Gaussian分布模型均可以处理特征不相互独立的问题,差别在于原始模型需要人工去估计两两特征之间的影响,而多维Gaussian分布则自动的量化了两两特征之间的影响。相对应地,前者的计算较简单,后者的计算量增加很多。
当提取到的特征很多,达到了 104 及其以上时,我们建议使用传统模型,因为这时 ∑(−1) 将会有超大的计算量。多维Gaussian分布模型则要求训练数据量m远大于n(视频说起码要 m>10n ),否则参数 ∑ 可能会是不可逆的。
Recommender Systems
Predicting Movie Ratings
Problem Formulation
在看到一部电影时,我们通常会去豆瓣上看一下众多网友对该电影的评分情况,然后我们以此来判断要不要看这部电影。这里用到的就是推荐系统(recommender system)机器学习的最大应用之一就是推荐系统,它可以帮助我们更加了解用户,从而提升用户体验,创造更多效益。这里以电影评级预测为例来介绍推荐系统。
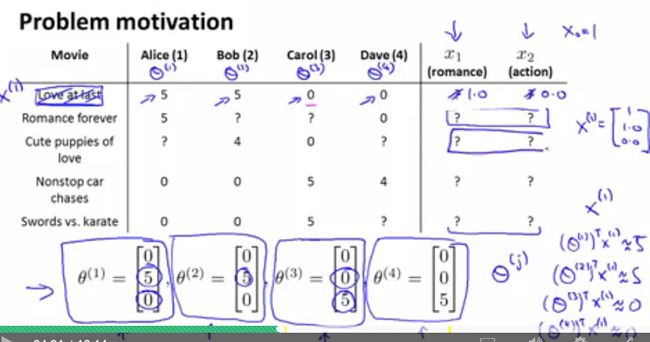
下图给出了4个用户对5部电影的评分情况,其中电影分数取值是{1,2,3,4,5},“?”表示该用户对该电影还未评分。这里引入变量 nu 、 nm 分别代表用户和电影的数量,变量 r(i,j) 表示用户j是否对电影i评分(若已评分则 r(i,j)=1 ,若未评分则 r(i,j)=0 ),变量 y(i,j) 表示用户j对电影i的评分(只有 r(i,j)=0 时才有这一项)。推荐系统要做的就是根据类似这样的数据来预测用户会喜欢那些类型的电影,从而向其推荐。
Content Based Recommendations
如何预测上图中的问号呢,下面给出过程。我们对电影进行特征提取,得到了两个特征 x1 、 x2 分别表示电影更倾向于爱情的还是动作的,如下图所示。所以每一部电影都会有一个特征向量 x(i)∈R3 ,如 x(1)=(1,0.9,0)T 。下面我们要做的是在已有的数据集中为用户j学习到一个参数 θ(j)∈R3 ,用 (θ(j))Tx(i) 去预测用户j对电影i的评分。如假设系统学习到用户Alice的参数为 θ(1)=(0,5,0)T ,那么系统预测用户Alice对电影Cute puppies of love的评分为 (θ(1))Tx(3)=4.95 。同样地,我们也就可以预测出表中其他问号的值了。
现在我们的问题转换成了线性回归问题,求出其中的参数 θ(j) 即可,接下来我们要做的就是下面这件事(引入变量 m(j) 表示用户j评价过的电影数量):
其中 θ(j)∈Rn+1 对于已有的数据集, m(j) 是一个定值,不会影响到上式,所以我们省去这个变量:
而系统要得到所有的参数 θ(1) 到 θ(nu) ,此时我们要做的是下面这件事(其实就是把所有的 θ 放一块儿求):
然后用梯度下降法去修正参数(Latex公式写得实在太累,还是截图吧):
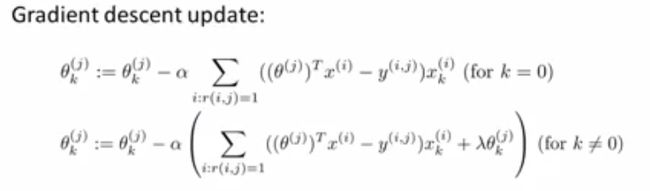
Collaborative Filtering
Collaborative Filtering
前面我们给出了每部的电影的具体特征值,但我们怎么得到这些特征值呢,协同过滤(collaborative filtering)将帮助我们完成这一工作。现在问题变成了求解下图中的所有问号:
现在假设我们已经得到了参数 θ(1) 到 θ(4) ,那我们由 (θ(j))Tx(i)=y(i,j) 很容易就可以得到 x(1) 到 x(5) 。
所以,此时我们要做的是下面这件事:

现在我们知道了,给定 x(1) 到 x(nm) (和电影评分数据集),我们能求得 θ(1) 到 θ(nu) ;而给定 θ(1) 到 θ(nu) (和评分数据集),我们能求得 x(1) 到 x(nm) 。现在,我们不妨从一组随机猜测的 θ(j) 出发去求出一组 x(i) ,再从这组 x(i) 出发求出一组新的 θ(j) ,如此往复下去,直到我们得到一组令人满意的 θ(j) 和 x(i) ,这就是协同过滤的基本流程。下一小节,我们将给出具体的算法。
Collaborative Filtering Algorithm
前面说了可以从随机的一组 θ(j) 出发交替求出 x(i) 和 θ(j) ,直至得到要求。现在我们尝试着同时求出这两组参数,给出下面的这样一个损失函数(用Latex敲出来的公式忒长了,无法显示,只好截图):
![]()
此时我们的目标就是最小化上面的损失函数:
注意,此时我们省去了线性回归中添加的 x0 ,因此有 x(i)∈Rn 和 θ(j)∈Rn 。
下图是协同过滤算法的详细过程:

Low Rank Matrix Factorization
Vectorization: Low Rank Matrix Factorization
这一小节我们要做的是将数据放到矩阵中

前面我们都是在讲如何根据已有评分数据预测用户对某一部电影的喜爱程度,下面我们介绍如何去发现相关电影(finding related movies)。首先,我们需要提取电影的特征,如特征 x1 代表电影的爱情片系数(值越大,说明该电影越偏向于爱情片),特征 x2 表示电影的动作片系数,特征 x3 表示电影的喜剧片系数等等。其实选择是一个很难的事情,现在业界好像还都在“拍脑门”(哎,我觉得这个特征不错,试一把,不成再换)似的提取特征,不过现在很火的深度学习(deep learning)似乎就是在解决这种问题。在选取n个特征之后,其实发现与电影i相关(类型相同等)的电影j就变成了这样一件事:
于是,找到上面公式的5个最小值对应的影片,就找到了5部与电影i最相近的影片。
Implementational Detail: Mean Normalization
最后一小节讲的是实现推荐系统时要注意的几个细节问题。我们如何去处理一个没有任何评分数据的用户,如Eve呢?我们需要为Eve找到一个参数 θ(5) 来最小化损失函数。由于Eve没有任何评分记录,所以损失函数的第一部分 12∑(i,j):r(i,j)=1((θ(j))Tx(i)−y(i,j))2 为0;而第二部分 λ2∑nmi=1∑nk=1(x(i)k)2 是对特征参数 x(i) 的求和,是一个常数,对损失函数没有影响;而第三部分 λ2∑nuj=1∑nk=1(θ(j))2 与 θ(5) 相关,要使损失函数得到最小值,只有 θ(5) 为零向量。所以结论是,推荐系统无法向零数据用户推荐电影,因为实在没有数据参考。
利用均值标准化是求出每个特征的均值,然后用其去处理原始数据,具体如下所示:

现在我们要从标准化的数据出发去预测,如预测用户j对电影i的评分为 (θ(j))T(x(i))+μi 。对于还没有评分数据的用户Eve,我们初始化其参数 θ(5)=(0,0)T ,我们预测他对电影i的评分为 (θ(5))T(x(i))+μi 。
以上就是Machine Learning中的异常检测和推荐系统。