javaweb基于内容的图片搜索引擎(2)_后台爬图
(源码后期会放在github上)
这一个博文主要就是爬图;
怎样爬图呢?或者从哪儿去爬图呢?这是首先要考虑的问题。
开始我想到了百度,就是百度图片,利用下面的url:
http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1460352369285_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=狗
仅仅需要把最后一个改成目标检索就可以了,然后我再用jsoup来解析,但是这里就遇到了第一个问题,就是js的问题,
在经过折腾后,我发现如果单纯用jsoup,解析后的原网页仅仅是一部分,也就是我们经常是,下拉条往下,然后就有很多图片,但通过解析原网页,可以看到这样的
字符串后面就是目标图片网页:

也就是说,我能得到图片了,这个问题解决了,百度剩下的无尽的图片肯定是用js动态生成,而它的js太多,我也就没去深究了。
接着下一个问题,如何能链接到原网页,也就是我能得到这个图片出现的网页呢?
很明显,直接通过jsoup来解析,是不能得到的,百度藏的太紧了。。
但是又需要,经过多次把弄后,我决定换一个源头,用搜狗的图片--它的可以得到原网页,并且图片更多~
但是呢?搜狗的并不能通过url来直接获得所要搜索的目标图片。如图:

这个时候就要用htmlunit了,模拟搜狗搜索来“搜索”我要的图片集,这里贴出代码截图(代码后期会放到github中):
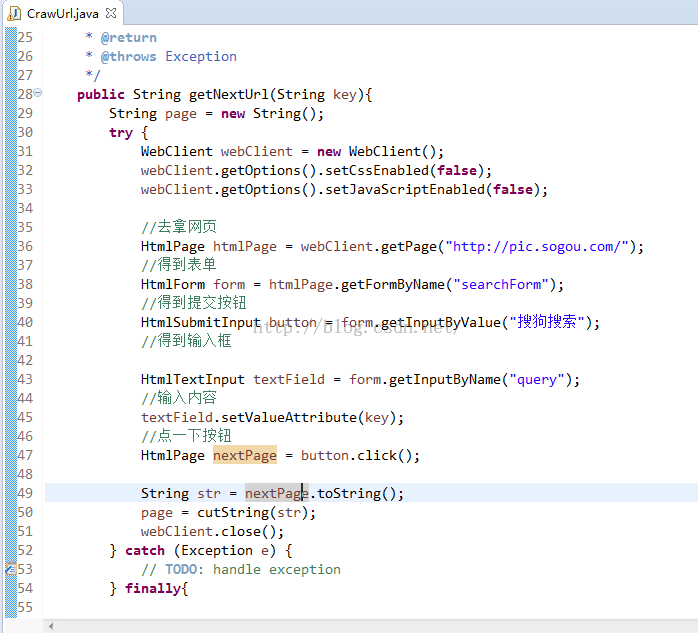
到这儿,我的图片就搜到了,再由下面的两个图片就可以知道我既可以获得源图片,又可以获得原图片网址:

也就是一个page_url和一个pic_url,这样就大功告成了。
以上就是爬图的整个过程