集合框架_泛型
一,介绍:
1,集合:集合是用来存储和管理其他对象的对象,即对象的容器,集合可以扩容,长度可以改变,可以存储多种类型的数据。
2,集合对象:
分体系:List Set
list:新出的子类都是以list结尾的,通常都是非同步的。
ArrayList:数组结构,查询速度快。
linkedList :链表结构,增删速度快。
Set:
HashSet:哈希结构:查询速度更快,元素唯一。通过hashCode(),equals方法保证唯一性。
TreeSet:看到Tree,就知道二叉树,可以排序排序就想到comparable的compareto方法,Comparator的compare方法。
二,图例:
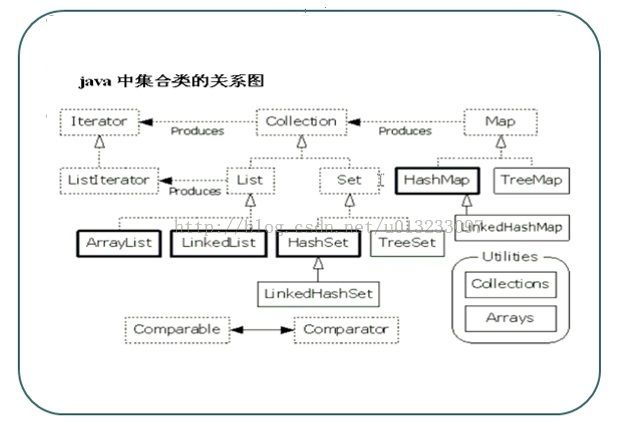
三,功能介绍:
1,Collection:
Collection是最基本集合接口,Collection 层次结构 中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的.
方法:
1, hashCode(): 返回此 collection 的哈希码值。
2,isEmpty() : 如果此 collection 不包含元素,则返回true。
3,iterator() : 返回在此 collection 的元素上进行迭代的迭代器。
4,size() : 返回此 collection 中的元素数。
5,contains():如果此 collection 包含指定的元素,则返回 true。更确切地讲,当且仅当此 collection 至少包含一个满足 (o==null ? e==null : o.equals(e)) 的元素e 时,返回true。
6,containsAll(Collection<?> : 如果此 collection 包含指定 collection 中的所有元素,则返回true。
2,LIst:
List 组件为用户提供了一个可滚动的文本项列表。可设置此 list,使其允许用户进行单项或多项选择。List集合代表一个有序集合,集合中每个元素都有其对应的顺序索引。List集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。 List作为Collection接口的子接口,可以使用Collection接口里的全部方法。
list可以存储重复元素,如果需求中要求容器中的元素必须保证唯一性则list不能保证。但保证了元素的顺序。
方法:
1,add(String item) 向滚动列表的末尾添加指定的项。
2,remove(int position) 从此滚动列表中移除指定位置处的项。
3,remove(String item) 从列表中移除项的第一次出现。
4,removeAll() 从此列表中移除所有项。
5,select(int index) 选择滚动列表中指定索引处的项。
6,查询:get(index);
ArrayList:是数组结构的,长度是可变的(原理是创建新数组+复制数组),查询的速度很快,增删较慢,不同步的。
LinkedList:是链表结构,不同步的,增删速度很快,查询速度较慢。
可用于实现堆栈,队列。
堆栈:先进后出:first in last out:filo。
队列:先进先出:first in first out:fifo.
3,Set:不包含重复元素的集合,不保证顺序,而且方法和collection一致。set集合取出元素的方式只有一种:迭代器。
hashSet:哈希表结构,不同步,保证元素唯一性的方式依赖于:hashcode(),equals()方法。
TreeSet:基于TreeMap的navigableSet实现,使用元素的自然顺序对元素进行排序。可以对Set集合中的元素进行排序。使用的是二叉树结构。使用的对象比较方法的结果是否为零,是零,视为相同元素,则不用存入。
TreeSet集合中元素的比较有两种方式:
1,元素自身具备自然排序,其实就是实现了Comparable接口,重写了comparableTo方式。
2,比较器,其实就是在创建TreeSet集合时,在构造函数中指定具体的比较方式。需要定义一个类,实现Comparable接口,重写comparable方法。 再往集合中存储对象时,通常该对象都需要覆盖hashCode,equals同时创建Comparable接口,建立对象的自然排序。通常还有一个方法也会复写toString();
4,Map:
Map是一种以键值对的形式存在的集合,其中每个键映射到一个值,几乎所有通用 Map 都使用哈希映射。位于java.util包中。其子类有HashMap,TreeMap。Map:<key,value>将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值。将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值。
1,map集合特点:
1,内部存储的都是键值对,
2,必须要保证键的唯一性。一次存一对元素。
,2,方法:
put(k key,V value):将指定的值与此映射中的指定键关联。如果键相同,值会被覆盖,并且put会有返回值返回旧值。
get(key):通过给定的键获取值。
keySet();获取map集合中的键的set集合。并会逆序输出。
entrySet():将map集合中映射关系(键值对的对应关系)存储到了Set集合中。映射关系的类型:Map.Entry。
map.values():获取所有的值,因为不需要保证唯一性,所以返回类型是Collection。
map集合没有迭代器,取出元素的方式:将map集合转成单列集合,再使用单列集合的迭代器就行了。也不能直接被foreach循环遍历。
Map集合元素的取出方式:
package Map;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class keySet {
//map集合中的元素取出方式:
public static void main(String[] args) {
Map<String ,String> map = new HashMap<String,String>();
map.put("01", "zhangsan01");
map.put("02", "zhangsan02");
map.put("03", "zhangsan03");
map.put("04", "zhangsan04");
map.put("05", "zhangsan05");
/*//1,先获取Set对象,通过keySet方式:
Set<String> keySet = map.keySet();
//获取迭代对象:
Iterator<String> it = keySet.iterator();
//遍历:
while(it.hasNext()){
String key = it.next();
String value = map.get(key);
System.out.println(key+":::"+value);
}*/
//方法二:将Map集合的映射关系取出,存入到Set集合中;
Set<Map.Entry<String,String>> entrySet = map.entrySet();
Iterator<Map.Entry<String, String>> it = entrySet.iterator();
while(it.hasNext()){
Map.Entry<String,String> me = it.next();
String key = me.getKey();
String value = me.getValue();
System.out.println(key+"::::"+value);
}
}
}
3,HashMap:
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用null 值和null 键。(除了非同步和允许使用 null 之外,HashMap 类与Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。数据结构:哈希表,不是同步的,但其有方法可以转为同步的(synchronizedMap())。允许为空作为键和值存进去。不保证映射的顺序,键相同,值不同。HashMap能存入。重写hashCode后则不能存入。
子类:-LinkHashMap:基于链表+哈希表,可以保证map集合有序(存入和取出顺序一致)。
4,Hashtable:
数据结构:哈希表,是同步的,不允许空作为键和值。被HashMap替代了。此类实现一个哈希表,该哈希表将键映射到相应的值。任何非null 对象都可以用作键或值。
子类:-properties:属性值,键和值都是字符串,而且可以结合流进行减值的操作,Io流中有介绍。
5,TreeMap:数据结构:二叉树,不是同步的,可以对map集合中的键进行排序。
5,collections:工具类:collections,集合框架中用于操作集合对象的工具类。都是静态的工具方法。此类完全由在collection上进行操作或返回collection的静态方法组成。
方法:
max(Collection<? extends T> coll):根据元素自然顺序,返回给定collection的最大元素。
min(Collection<? extends T> coll):根据元素自然顺序,返回给定collection的最小元素。
max(Collection<? extends T> coll,Comparator<? super T> comp):根据指定比较器产生的顺序,返回给定collection的最大元素。
min(Collection<? extends T> coll,Comparator<? super T> comp):根据指定比较器产生的顺序,返回给定collection的最小元素。
sort(List<T> list):根据元素的自然顺序,对指定列表按升序进行排序。
sort(List<T> list,Comparator<? super T> c):根据指定比较器产生的自然顺序,对指定列表按升序进行排序。
reverseOrder():返回一个比较器,他强行逆转实现了Comparable接口的对象Collection的自然顺序。
reverseOrder(Comparator<T> cmp):返回一个比较器,它强行逆转指定比较器的顺序。
6,Arrays:工具类,集合和数组的互转。
用于操作数组的工具类。类中定义的一些都是静态工具方法:
1,对数组排序,
2,二分查找,
3,数组复制,
4,对两个数组进行元素的比较,判断两个数组是否相同。
5,将数组转成字符串:tostring();
asList(T...a):返回一个受指定数组支持的固定大小的的列表。
数组转成集合:就是为了使用集合的方法操作数组中的元素。
但是不要使用增删等改变长度的方法。add remove方法不可用,会发生异常:UnsupportedOperationException
若数组中存储的是基本数据类型,那么转成集合,数组对象会作为集合中的元素存在。数组中元素是引用数据类型时转成集合,数组元素会作为集合元素存在。
集合转成数组:目的为了限制对元素的增删操作。
toArray();如果传递的数组的长度小于集合的长度,会创建一个同类型的数组长度。如果传递的数组的长度大雨了集合的长度,就会使用这个数组,没有存储元素的位置为null,长度最好直接定义为和集合长度一致。
四,泛型:
1,泛型:当方法要操作的类型不确定和类上的泛型不一定一样,这时可以将泛型定义在方法上。称之为泛型方法。如果方法时静态的,还需要使用泛型,那么泛型必须定义在方法上。
1,一种安全机制。
2,将运行时期的ClassCastException,转移到了编译时期变成了编译失败。
3,泛型技术,是给编译器使用的技术。
4,泛型的出现避免了强转的麻烦。
2,当使用泛型接类或者接口时,传递的具体的类型不确定,可以通过通配符表示。如果想要对被打印的集合中的元素进行限制,只在指定的一些类型,进行打印。使用泛型的限定。
<? extends Person>:接受Person类型或者person的子类型。称为上限。
<? super e>:接收E类型或者e父类型。下限
<? extends E>:接收E类型或者E的子类型。上限
五,细节:
1, 1,集合中存储的其实都是对象的地址。
2,jdk1.5后集合中可以存储基本数值,但存储的是基本数据类型包装类的对象。
3,集合取出来的都是Object对象,需要使用元素的特有方法时,需要向下转型。
4,存储时提升为了Object。取出则需要向下转型。
2,Hashtable和HashMap的区别:
1.Hashtable是Dictionary的子类,HashMap是Map接口的一个实现类;
2.Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。即是说,在多线程应用程序中,不用专门的操作就安全地可以使用Hashtable了;而对于HashMap,则需要额外的同步机制。
3,但HashMap的同步问题可通过Collections的一个静态方法得到解决:
Map Collections.synchronizedMap(Map m)
4,Hashtable:不允许空作为键和值。被HashMap替代了.
3,hashMap和Treemap区别:
HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。
1. HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,只不过Set用的只是Map的key
2. Map的key和Set都有一个共同的特性就是集合的唯一性.TreeMap更是多了一个排序的功能.
3. hashCode和equal()是HashMap用的, 因为无需排序所以只需要关注定位和唯一性即可.
a. hashCode是用来计算hash值的,hash值是用来确定hash表索引的.
b. hash表中的一个索引处存放的是一张链表, 所以还要通过equal方法循环比较链上的每一个对象才可以真正定位到键值对应的Entry.
c. put时,如果hash表中没定位到,就在链表前加一个Entry,如果定位到了,则更换Entry中的value,并返回旧value
4. 由于TreeMap需要排序,所以需要一个Comparator为键值进行大小比较.当然也是用Comparator定位的.
a. Comparator可以在创建TreeMap时指定
b. 如果创建时没有确定,那么就会使用key.compareTo()方法,这就要求key必须实现Comparable接口.
c. TreeMap是使用Tree数据结构实现的,所以使用compare接口就可以完成定位了.
注意:
1、Collection没有get()方法来取得某个元素。只能通过iterator()遍历元素。
2、Set和Collection拥有一模一样的接口。
3、List,可以通过get()方法来一次取出一个元素。使用数字来选择一堆对象中的一个,get(0)...。(add/get)
4、一般使用ArrayList。用LinkedList构造堆栈stack、队列queue。
5、Map用 put(k,v) / get(k),还可以使用containsKey()/containsValue()来检查其中是否含有某个key/value。
HashMap会利用对象的hashCode来快速找到key。
hashing
哈希码就是将对象的信息经过一些转变形成一个独一无二的int值,这个值存储在一个array中。
我们都知道所有存储结构中,array查找速度是最快的。所以,可以加速查找。
发生碰撞时,让array指向多个values。即,数组每个位置上又生成一个梿表。
6、Map中元素,可以将key序列、value序列单独抽取出来。
使用keySet()抽取key序列,将map中的所有keys生成一个Set。
使用values()抽取value序列,将map中的所有values生成一个Collection。
为什么一个生成Set,一个生成Collection?那是因为,key总是独一无二的,value允许重复。